with a as (
select a.*, row_number() over (partition by department order by attributeID) rn
from attributes a),
e as (
select employeeId, department, attribute1, 1 rn from employees union all
select employeeId, department, attribute2, 2 rn from employees union all
select employeeId, department, attribute3, 3 rn from employees
)
select e.employeeId, a.attributeid, e.department, a.attribute, a.meaning,
e.attribute1 as value
from e join a on a.department=e.department and a.rn=e.rn
order by e.employeeId, a.attributeid
Uji data dan keluaran:
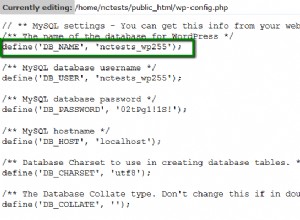
create table employees (employeeID number(3), name varchar2(10), department varchar2(5), age number(3), attribute1 varchar2(10), attribute2 varchar2(10), attribute3 varchar2(10));
insert into employees values (1, 'john', 'IT', 22, 'attr1val1', 'attr2val2', null);
insert into employees values (2, 'jane', 'HR', 32, 'attr1val3', 'attr2val4', 'attr3val5');
insert into employees values (3, 'joe', 'HR', 23, 'attr1val6', 'attr2val7', 'attr3val8');
insert into employees values (4, 'jack', 'IT', 45, 'attr1val9', 'attr2val10', null);
create table attributes (attributeID number(3), department varchar2(10), attribute varchar2(10), meaning varchar2(10));
insert into attributes values (1, 'IT', 'attribute1', 'laptoptype');
insert into attributes values (2, 'IT', 'attribute2', 'networkloc');
insert into attributes values (3, 'HR', 'attribute1', 'location');
insert into attributes values (4, 'HR', 'attribute2', 'position');
insert into attributes values (5, 'HR', 'attribute3', 'allocation');
EMPLOYEEID ATTRIBUTEID DEPARTMENT ATTRIBUTE MEANING VALUE
---------- ----------- ---------- ---------- ---------- ----------
1 1 IT attribute1 laptoptype attr1val1
1 2 IT attribute2 networkloc attr2val2
2 3 HR attribute1 location attr1val3
2 4 HR attribute2 position attr2val4
2 5 HR attribute3 allocation attr3val5
3 3 HR attribute1 location attr1val6
3 4 HR attribute2 position attr2val7
3 5 HR attribute3 allocation attr3val8
4 1 IT attribute1 laptoptype attr1val9
4 2 IT attribute2 networkloc attr2val10
Sunting :Penjelasan
Sebagai jawaban, saya menggunakan with
klausa hanya untuk membagi solusi menjadi langkah-langkah yang dapat dibaca. Anda dapat memindahkannya ke from klausa permintaan utama jika itu lebih nyaman bagi Anda. Pokoknya:subquery a membaca data dari tabel attributes dan menambahkan nomor untuk baris, jadi untuk setiap departemen mereka selalu diberi nomor dari 1. Saya menggunakan row_number()
untuk itu. Subkueri e serikat (semua) diperlukan atribut dan nomormereka sesuai. Angka yang dihasilkan di kedua subkueri kemudian digunakan dalam gabungan utama:a.department=e.department and a.rn=e.rn .
Alternatif 1 - jika Anda menggunakan Oracle 11g, Anda dapat menggunakan unpivot
. Lihat apa yang dihasilkan oleh subquery, dan bagaimana subquery digabungkan dengan attributes tabel:
with e as (
select employeeId, name, department, attribute, value from employees
unpivot (value for attribute in ("ATTRIBUTE1", "ATTRIBUTE2", "ATTRIBUTE3"))
)
select e.employeeId, a.attributeid, e.department, a.attribute,
a.meaning, e.value
from e join attributes a on a.department=e.department
and lower(a.attribute)=lower(e.attribute)
order by e.employeeId, a.attributeid;
Alternatif 2 - dengan generator subquery hierarkis (subquery r ), direalisasikan oleh connect by
yang simple membuat angka dari 1, 2, 3 yang selanjutnya digabungkan dengan employees dan atribut yang tepat dilampirkan sebagai nilai dalam case ayat. Istirahat dibuat dengan cara yang sama seperti pada jawaban asli.
with a as (
select a.*, row_number() over (partition by department order by attributeID) rn
from attributes a),
r as (select level rn from dual connect by level<=3),
e as (
select employeeId, department, rn,
case when r.rn = 1 then attribute1
when r.rn = 2 then attribute2
when r.rn = 3 then attribute3
end value
from employees cross join r
)
select e.employeeId, a.attributeid, e.department, a.attribute,
a.meaning, e.value
from e join a on a.department=e.department and a.rn=e.rn
order by e.employeeId, a.attributeid
Ketiga versi memberi saya hasil yang sama. Saya juga menguji opsi pertama pada tabel serupa dengan 100 ribu baris dan mendapatkan output dalam beberapa detik (untuk 5 atribut). Silakan uji semua solusi dan cobalah untuk memahaminya. Jika Anda dapat menggunakan versi unpivot, saya lebih suka ini. Maaf untuk penjelasan yang tertunda dan kesalahan bahasa apa pun.