Gunakan subquery untuk membungkus perhitungan row_number, lalu gunakan kolom turunan di split-by.
--query "select col1, ... colN, RANGEGROUP
from (select t.*, row_number() OVER (order by t.item_id ) AS RANGEGROUP
from table t ) s
where 1=1 and \$CONDITIONS"
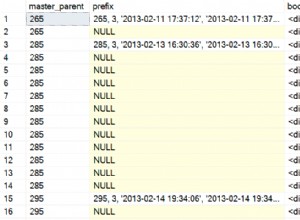
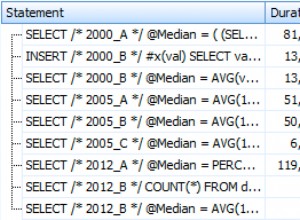
row_number harus deterministik, artinya ketika dieksekusi beberapa kali, itu harus menetapkan nomor yang sama persis untuk semua baris. Apa yang bisa terjadi jika ORDER BY di OVER tidak berisi kolom atau kombinasi unik:row_number dapat mengembalikan nomor yang berbeda untuk baris yang sama. Dan jika Anda menggunakannya secara split-by, Anda akan mendapatkan duplikasi karena baris yang sama dapat berada dalam rentang 1 yang terpisah, katakanlah 1-100, di mapper2 sqoop akan menjalankan kueri yang sama dengan filter untuk rentang 2, katakanlah (101-200 ) baris yang sama dapat muncul juga dalam rentang tersebut. Sqoop menjalankan kueri yang sama dalam wadah yang berbeda (pemeta) dengan kondisi berbeda untuk mendapatkan rentang terpisah secara paralel.
Jika Id adalah int (dan jauh lebih baik jika didistribusikan secara merata), gunakan ID itu. Mengapa Anda mungkin membutuhkan row_number adalah ketika STRING kolom. baca ini:https://stackoverflow.com/a/37389134/2700344 , kolom terpisah belum tentu PK