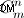Untuk lebih memahami apa yang terjadi, coba ini:
explain plan set statement_id = 'query1' for
SELECT count(ck.id)
FROM claim_key ck
WHERE (ck.dte_of_srvce > (SYSDATE - INTERVAL '30' DAY))
AND ck.clm_type = 5
AND ck.prgrm_id = 1;
lalu:
select *
from table(dbms_xplan.display(statement_id=>'query1'));
Saya rasa Anda akan melihat baris yang menunjukkan AKSES TABEL PENUH di claim_key.
Kemudian coba:
explain plan set statement_id = 'query2' for
SELECT count(ck.id)
FROM claim_key ck
WHERE (ck.dte_of_srvce > (SYSDATE - INTERVAL '30' DAY))
AND ck.clm_type = 5;
select *
from table(dbms_xplan.display(statement_id=>'query2'));
dan periksa untuk melihat indeks apa yang (mungkin) gunakan. Itu akan memberi Anda gambaran tentang apa yang dilakukan database yang membantu untuk mengetahui mengapa itu melakukannya.
Oke, mengingat rencana penjelasan Anda, ini adalah contoh klasik dari "indeks tidak selalu baik, pemindaian tabel tidak selalu buruk".
INDEX SKIP SCAN adalah tempat database dapat mencoba menggunakan indeks meskipun kolom utama indeks bahkan tidak digunakan. Pada dasarnya jika indeks Anda terlihat seperti ini (terlalu disederhanakan):
COL1 COL2 ROWID
A X 1 <--
A Y 2
A Z 3
B X 4 <--
B Y 5
B Z 6
dan kondisi Anda WHERE col2 ='X' indeks lewati scan mengatakan melihat melalui setiap kombinasi di COL1 untuk di mana col2 ='X'. Ini "melewati" nilai dalam col1 setelah ditemukan kecocokan (mis. col1 =A, col2 =X) ke tempat nilai berubah (col1 =B, lalu col1 =C, dll.) dan mencari lebih banyak kecocokan.
Tangkapannya adalah bahwa indeks (umumnya!) bekerja seperti ini:1) temukan rowid berikutnya dalam indeks di mana nilainya ditemukan 2) buka blok tabel dengan rowid itu (TABLE ACCESS BY INDEX ROWID) 3) ulangi sampai tidak ada lagi yang cocok ditemukan.
(Untuk pemindaian lewati, juga akan dikenakan biaya untuk mencari tahu di mana perubahan nilai berikutnya untuk kolom-kolom terdepan.)
Ini semua baik dan bagus untuk sejumlah kecil baris, tetapi menderita hukum hasil yang semakin berkurang; itu tidak terlalu bagus ketika Anda memiliki banyak baris. Itu karena ia harus membaca blok indeks, lalu blok tabel, lalu blok indeks, blok tabel (bahkan jika blok tabel sudah dibaca sebelumnya.)
Pemindaian tabel lengkap hanya "membajak" data sebagian berkat ... pembacaan multiblok. Basis data dapat membaca banyak blok dari disk dalam sekali baca dan tidak membaca blok yang sama lebih dari sekali.
INDEX FAST FULL SCAN pada dasarnya memperlakukan I_CLAIM_KEY_002 sebagai tabel. Semua yang Anda butuhkan dalam kueri dapat dijawab oleh indeks saja; tidak diperlukan AKSES TABEL. (Saya menduga I_CLAIM_KEY_002 didefinisikan sebagai clnt_id, dte_of_srvce dan clnt_id atau dte_of_srvce tidak dapat dibatalkan. Karena ck.id seharusnya bukan atribut nol, hitungan ck.id sama dengan hitungan ck.clnt_id.)
Jadi untuk kueri awal Anda, kecuali jika Anda ingin mengatur ulang indeks Anda, coba ini:
SELECT /*+ FULL(ck) */ count(ck.id)
FROM claim_key ck
WHERE (ck.dte_of_srvce > (SYSDATE - INTERVAL '30' DAY))
AND ck.clm_type = 5
AND ck.prgrm_id = 1
yang akan memaksa pemindaian tabel penuh pada claim_key (ck) dan Anda dapat melihat kinerja yang serupa dengan dua lainnya. (Periksa apakah ini masalahnya, pertama-tama awali kueri dengan "explain plan set statement_id ='query_hint' for" dan jalankan kueri dbms_xplan sebelum Anda menjalankannya.)
(Sekarang Anda akan bertanya "apakah saya ingin memasukkan petunjuk seperti itu sepanjang waktu"? Tolong jangan. Ini hanya untuk tes. Ini hanya untuk memeriksa apakah FTS lebih baik daripada INDEX SKIP SCAN . Jika ya, maka Anda perlu mencari tahu alasannya. :)
Anyways...Saya harap itu masuk akal..Maksud saya masuk akal.