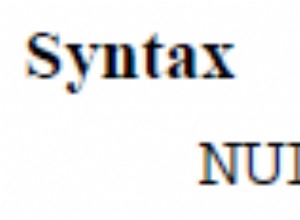Setelah banyak menggali kode sumber Hibernate dan driver PostgreSQL JDBC, saya berhasil menemukan akar penyebab masalahnya. Pada akhirnya metode write() dari BlobOutputStream (disediakan oleh driver JDBC) dipanggil untuk menulis konten Clob ke dalam database. Metode ini terlihat seperti ini:
public void write(int b) throws java.io.IOException
{
checkClosed();
try
{
if (bpos >= bsize)
{
lo.write(buf);
bpos = 0;
}
buf[bpos++] = (byte)b;
}
catch (SQLException se)
{
throw new IOException(se.toString());
}
}
Metode ini menggunakan 'int' (32 bit/4 byte) sebagai argumen dan mengubahnya menjadi 'byte' (8 bit/1 byte) secara efektif kehilangan 3 byte informasi. Representasi string dalam Java dikodekan dengan UTF-16, artinya setiap karakter diwakili oleh 16 bit/2 byte. Tanda Euro memiliki nilai int 8364. Setelah konversi ke byte, nilai tetap 172 (dalam representasi oktet 254).
Saya tidak yakin apa sekarang resolusi terbaik untuk masalah ini. IMHO driver JDBC harus bertanggung jawab untuk encoding/decoding karakter Java UTF-16 ke pengkodean apa pun yang dibutuhkan database. Namun, saya tidak melihat kemungkinan penyesuaian dalam kode driver JDBC untuk mengubah perilakunya (dan saya tidak ingin menulis dan memelihara kode driver JDBC saya sendiri).
Oleh karena itu, saya memperluas Hibernate dengan ClobType khusus dan berhasil mengonversi karakter UTF-16 ke UTF-8 sebelum menulis ke database dan sebaliknya saat mengambil Clob.
Solusinya terlalu besar untuk hanya ditempelkan di jawaban ini. Jika Anda tertarik, hubungi saya, dan saya akan mengirimkannya kepada Anda.
Salam, Franck