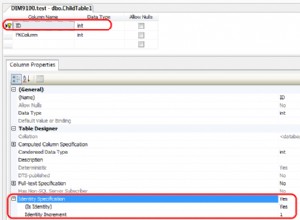
Desain DB
Sementara Anda bisa bekerja dengan date yang terpisah dan time kolom, benar-benar tidak ada keuntungan dari satu timestamp
kolom. Saya akan beradaptasi:
ALTER TABLE tbl ADD column ts timestamp;
UPDATE tbl SET ts = date + time; -- assuming actual date and time types
ALTER TABLE tbl DROP column date, DROP column time;
Jika tanggal dan waktu bukan date yang sebenarnya dan time tipe data, gunakan to_timestamp() . Terkait:
- Menghitung Jumlah Kumulatif di PostgreSQL
- Cara mengonversi "string" ke "stempel waktu tanpa zona waktu"
Kueri
Maka kuerinya sedikit lebih sederhana:
SELECT *
FROM (
SELECT sn, generate_series(min(ts), max(ts), interval '5 min') AS ts
FROM tbl
WHERE sn = '4as11111111'
AND ts >= '2018-01-01'
AND ts < '2018-01-02'
GROUP BY 1
) grid
CROSS JOIN LATERAL (
SELECT round(avg(vin1), 2) AS vin1_av
, round(avg(vin2), 2) AS vin2_av
, round(avg(vin3), 2) AS vin3_av
FROM tbl
WHERE sn = grid.sn
AND ts >= grid.ts
AND ts < grid.ts + interval '5 min'
) avg;
db<>fiddle di sini
Hasilkan kisi waktu mulai di subkueri pertama grid , berjalan dari kualifikasi pertama hingga terakhir baris dalam jangka waktu tertentu.
Gabung ke baris yang ada di setiap partisi dengan LATERAL bergabung dan segera agregat rata-rata di subkueri avg . Karena agregat, selalu mengembalikan baris bahkan jika tidak ada entri yang ditemukan. Rata-rata default ke NULL dalam hal ini.
Hasilnya mencakup semua slot waktu antara baris kualifikasi pertama dan terakhir dalam jangka waktu tertentu. Berbagai komposisi hasil lainnya juga masuk akal. Suka sertakan semua slot waktu dalam kerangka waktu tertentu atau hanya slot waktu dengan nilai aktual. Sebisa mungkin, saya harus memilih satu interpretasi.
Indeks
Setidaknya memiliki indeks multikolom ini:
CRATE INDEX foo_idx ON tbl (sn, ts);
Atau di (sn, ts, vin1, vin2, vin3) untuk mengizinkan pemindaian indeks saja - jika beberapa prasyarat terpenuhi dan terutama jika baris tabel jauh lebih lebar daripada di demo.
Berhubungan erat:
- Slow LEFT JOIN di CTE dengan interval waktu
- Cara terbaik untuk menghitung catatan dengan interval waktu sewenang-wenang di Rails+Postgres
Berdasarkan tabel asli Anda
Seperti yang diminta dan diklarifikasi di komentar
, dan kemudian diperbarui lagi dalam pertanyaan untuk memasukkan kolom mac dan loc . Saya berasumsi Anda ingin rata-rata terpisah per (mac, loc) .
date dan time masih kolom terpisah, kolom vin* adalah tipe float , dan mengecualikan slot waktu tanpa baris:
Kueri yang diperbarui juga memindahkan fungsi pengembalian set generate_series() ke FROM list, yang lebih bersih sebelum Postgres 10:
SELECT t.mac, sn.sn, t.loc, ts.ts::time AS time, ts.ts::date AS date
, t.vin1_av, t.vin2_av, t.vin3_av
FROM (SELECT text '4as11111111') sn(sn) -- provide sn here once
CROSS JOIN LATERAL (
SELECT min(date+time) AS min_ts, max(date+time) AS max_ts
FROM tbl
WHERE sn = sn.sn
AND date+time >= '2018-01-01 0:0' -- provide time frame here
AND date+time < '2018-01-02 0:0'
) grid
CROSS JOIN LATERAL generate_series(min_ts, max_ts, interval '5 min') ts(ts)
CROSS JOIN LATERAL (
SELECT mac, loc
, round(avg(vin1)::numeric, 2) AS vin1_av -- cast to numeric for round()
, round(avg(vin2)::numeric, 2) AS vin2_av -- but rounding is optional
, round(avg(vin3)::numeric, 2) AS vin3_av
FROM tbl
WHERE sn = sn.sn
AND date+time >= ts.ts
AND date+time < ts.ts + interval '5 min'
GROUP BY mac, loc
HAVING count(*) > 0 -- exclude empty slots
) t;
Buat indeks ekspresi multikolom untuk mendukung ini:
CRATE INDEX bar_idx ON tbl (sn, (date+time));
db<>fiddle di sini
Tapi saya lebih suka menggunakan timestamp selama ini.