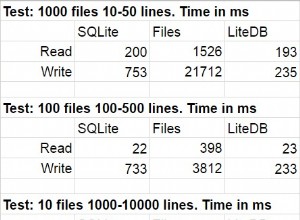
gaps-and-islands masalah memang.
Dengan asumsi:
- "Garis-garis" tidak terganggu oleh baris dari pemain lain.
- Semua kolom didefinisikan
NOT NULL. (Jika tidak, Anda harus melakukan lebih banyak.)
Ini harus paling sederhana dan tercepat karena hanya membutuhkan dua row_number() fungsi jendela
:
SELECT DISTINCT ON (player_id)
player_id, count(*) AS seq_len, min(ts) AS time_began
FROM (
SELECT player_id, points, ts
, row_number() OVER (PARTITION BY player_id ORDER BY ts)
- row_number() OVER (PARTITION BY player_id, points ORDER BY ts) AS grp
FROM tbl
) sub
WHERE points = 100
GROUP BY player_id, grp -- omit "points" after WHERE points = 100
ORDER BY player_id, seq_len DESC, time_began DESC;
db<>fiddle di sini
Menggunakan nama kolom ts bukannya time , yang merupakan kata yang dicadangkan
dalam SQL standar. Ini diperbolehkan di Postgres, tetapi dengan batasan dan masih merupakan ide yang buruk untuk menggunakannya sebagai pengenal.
"Trik"nya adalah dengan mengurangkan nomor baris sehingga baris yang berurutan termasuk dalam kelompok yang sama (grp ) per (player_id, points) . Lalu menyaring yang memiliki 100 poin, agregat per grup dan hanya mengembalikan hasil terpanjang dan terbaru per pemain.
Penjelasan dasar untuk teknik ini:
Kita dapat menggunakan GROUP BY dan DISTINCT ON dalam SELECT . yang sama , GROUP BY diterapkan sebelum DISTINCT ON . Pertimbangkan urutan kejadian dalam SELECT permintaan:
Tentang DISTINCT ON :