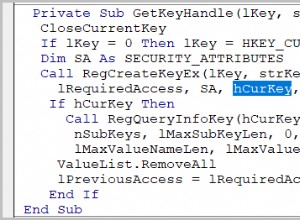
Hitung semua baris
SELECT date, '1_D' AS time_series, count(DISTINCT user_id) AS cnt
FROM uniques
GROUP BY 1
UNION ALL
SELECT DISTINCT ON (1)
date, '2_W', count(*) OVER (PARTITION BY week_beg ORDER BY date)
FROM uniques
UNION ALL
SELECT DISTINCT ON (1)
date, '3_M', count(*) OVER (PARTITION BY month_beg ORDER BY date)
FROM uniques
ORDER BY 1, time_series
-
Kolom Anda
week_begdanmonth_beg100% berlebihan dan dapat dengan mudah diganti dengandate_trunc('week', date + 1) - 1dandate_trunc('month', date)masing-masing. -
Minggu Anda sepertinya dimulai pada hari Minggu (mati satu per satu), oleh karena itu
+ 1 .. - 1. -
Frame default fungsi jendela dengan
ORDER BYdiOVERpenggunaan klausa adalahRANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Itulah yang Anda butuhkan. -
Gunakan
UNION ALL, bukanUNION. -
Pilihan malang Anda untuk
time_series(D, W, M) tidak terurut dengan baik, saya mengganti namanya menjadiORDER BYterakhir lebih mudah. -
Kueri ini dapat menangani beberapa baris per hari. Hitungan mencakup semua rekan selama sehari.
-
Selengkapnya tentang
DISTINCT ON:
Pengguna BERBEDA per hari
Untuk menghitung setiap pengguna hanya sekali per hari, gunakan CTE dengan DISTINCT ON :
WITH x AS (SELECT DISTINCT ON (1,2) date, user_id FROM uniques)
SELECT date, '1_D' AS time_series, count(user_id) AS cnt
FROM x
GROUP BY 1
UNION ALL
SELECT DISTINCT ON (1)
date, '2_W'
,count(*) OVER (PARTITION BY (date_trunc('week', date + 1)::date - 1)
ORDER BY date)
FROM x
UNION ALL
SELECT DISTINCT ON (1)
date, '3_M'
,count(*) OVER (PARTITION BY date_trunc('month', date) ORDER BY date)
FROM x
ORDER BY 1, 2
Pengguna BERBEDA selama periode waktu yang dinamis
Anda selalu dapat menggunakan subkueri berkorelasi . Cenderung lambat dengan tabel besar!
Membangun kueri sebelumnya:
WITH du AS (SELECT date, user_id FROM uniques GROUP BY 1,2)
,d AS (
SELECT date
,(date_trunc('week', date + 1)::date - 1) AS week_beg
,date_trunc('month', date)::date AS month_beg
FROM uniques
GROUP BY 1
)
SELECT date, '1_D' AS time_series, count(user_id) AS cnt
FROM du
GROUP BY 1
UNION ALL
SELECT date, '2_W', (SELECT count(DISTINCT user_id) FROM du
WHERE du.date BETWEEN d.week_beg AND d.date )
FROM d
GROUP BY date, week_beg
UNION ALL
SELECT date, '3_M', (SELECT count(DISTINCT user_id) FROM du
WHERE du.date BETWEEN d.month_beg AND d.date)
FROM d
GROUP BY date, month_beg
ORDER BY 1,2;
SQL Fiddle untuk ketiga solusi.
Lebih cepat dengan dense_rank()
@Clodoaldo
datang dengan peningkatan besar:gunakan fungsi jendela dense_rank()
. Berikut adalah ide lain untuk versi yang dioptimalkan. Seharusnya lebih cepat untuk mengecualikan duplikat harian segera. Peningkatan performa meningkat seiring dengan jumlah baris per hari.
Membangun model data yang disederhanakan dan disanitasi - tanpa kolom yang berlebihan- day sebagai nama kolom alih-alih date
date adalah kata yang dicadangkan dalam SQL standar
dan nama tipe dasar di PostgreSQL dan tidak boleh digunakan sebagai pengenal.
CREATE TABLE uniques(
day date -- instead of "date"
,user_id int
);
Kueri yang ditingkatkan:
WITH du AS (
SELECT DISTINCT ON (1, 2)
day, user_id
,date_trunc('week', day + 1)::date - 1 AS week_beg
,date_trunc('month', day)::date AS month_beg
FROM uniques
)
SELECT day, count(user_id) AS d, max(w) AS w, max(m) AS m
FROM (
SELECT user_id, day
,dense_rank() OVER(PARTITION BY week_beg ORDER BY user_id) AS w
,dense_rank() OVER(PARTITION BY month_beg ORDER BY user_id) AS m
FROM du
) s
GROUP BY day
ORDER BY day;
SQL Fiddle
mendemonstrasikan performa 4 varian yang lebih cepat. Itu tergantung pada distribusi data Anda yang tercepat untuk Anda.
Semuanya sekitar 10x lebih cepat dari versi subkueri berkorelasi (yang tidak buruk untuk subkueri berkorelasi).