Seperti yang mungkin telah Anda catat dari blog saya sebelumnya, beberapa bulan terakhir ini sibuk dengan Postgres-XL yang up-to-date dengan rilis PostgreSQL 9.5 terbaru. Setelah kami memiliki versi Postgres-XL 9.5 yang cukup stabil, kami mengalihkan perhatian kami untuk mengukur kinerja Postgres-XL versi baru ini. Pilihan tolok ukur kami sebagian besar dipengaruhi oleh pekerjaan yang sedang berlangsung pada proyek AXLE, yang didanai oleh Uni Eropa berdasarkan perjanjian hibah 318633. Karena kami menggunakan TPC BENCHMARK™ H untuk mengukur kinerja semua pekerjaan lain yang dilakukan di bawah proyek ini, kami memutuskan untuk gunakan tolok ukur yang sama untuk mengevaluasi Postgres-XL. Ini juga cocok untuk Postgres-XL karena TPC-H mencoba mengukur beban kerja OLAP, sesuatu yang harus dilakukan Postgres-XL dengan baik.
1. Pengaturan Cluster Postgres-XL
Setelah tolok ukur diputuskan, tantangan besar lainnya adalah menemukan sumber daya yang tepat untuk pengujian. Kami tidak memiliki akses ke sekelompok besar mesin fisik. Jadi kami melakukan apa yang kebanyakan akan dilakukan. Kami memutuskan untuk menggunakan Amazon AWS untuk menyiapkan klaster Postgres-XL. AWS menawarkan berbagai macam instans, dengan setiap jenis instans menawarkan daya komputasi atau IO yang berbeda.
Halaman ini di AWS menunjukkan berbagai jenis instans yang tersedia, sumber daya yang tersedia, dan harganya untuk wilayah yang berbeda. Perlu diperhatikan bahwa harga dan ketersediaan mungkin berbeda di setiap wilayah, jadi penting bagi Anda untuk memeriksa semua wilayah. Karena Postgres-XL memerlukan latensi rendah dan throughput tinggi di antara komponennya, penting juga untuk membuat instance semua instance di region yang sama. Untuk 3TB TPC-H kami, kami memutuskan untuk menggunakan klaster 16-dataanode dari instans AWS i2.xlarge. Instans ini masing-masing memiliki 4 vCPU, 30GB RAM, dan 800GB SSD, penyimpanan yang cukup untuk menyimpan semua tabel terdistribusi, tabel yang direplikasi (yang membutuhkan lebih banyak ruang dengan bertambahnya ukuran cluster), indeks di dalamnya dan masih menyisakan cukup ruang kosong di tablespace sementara untuk CREATE INDEX dan kueri lainnya.
2. Penyiapan Tolok Ukur
2.1 TPC Benchmark™ H
Benchmark berisi 22 kueri dengan tujuan untuk memeriksa volume data yang besar, menjalankan kueri dengan tingkat kerumitan yang tinggi, dan memberikan jawaban atas pertanyaan bisnis yang penting. Kami ingin mencatat bahwa spesifikasi lengkap TPC Benchmark™ H berkaitan dengan berbagai pengujian seperti beban, daya, dan throughput tes. Untuk pengujian kami, kami hanya menjalankan kueri individual dan bukan rangkaian pengujian lengkap. TPC Benchmark™ H terdiri dari serangkaian pertanyaan bisnis yang dirancang untuk menjalankan fungsionalitas sistem dengan cara yang mewakili aplikasi analisis bisnis yang kompleks. Kueri ini diberikan konteks yang realistis, yang menggambarkan aktivitas pemasok grosir untuk membantu pembaca memahami secara intuitif komponen tolok ukur.
2.2 Entitas, Hubungan, dan Karakteristik Basis Data
Komponen database TPC-H didefinisikan terdiri dari delapan tabel terpisah dan individual (Tabel Dasar). Hubungan antar kolom tabel ini diilustrasikan dalam diagram berikut. 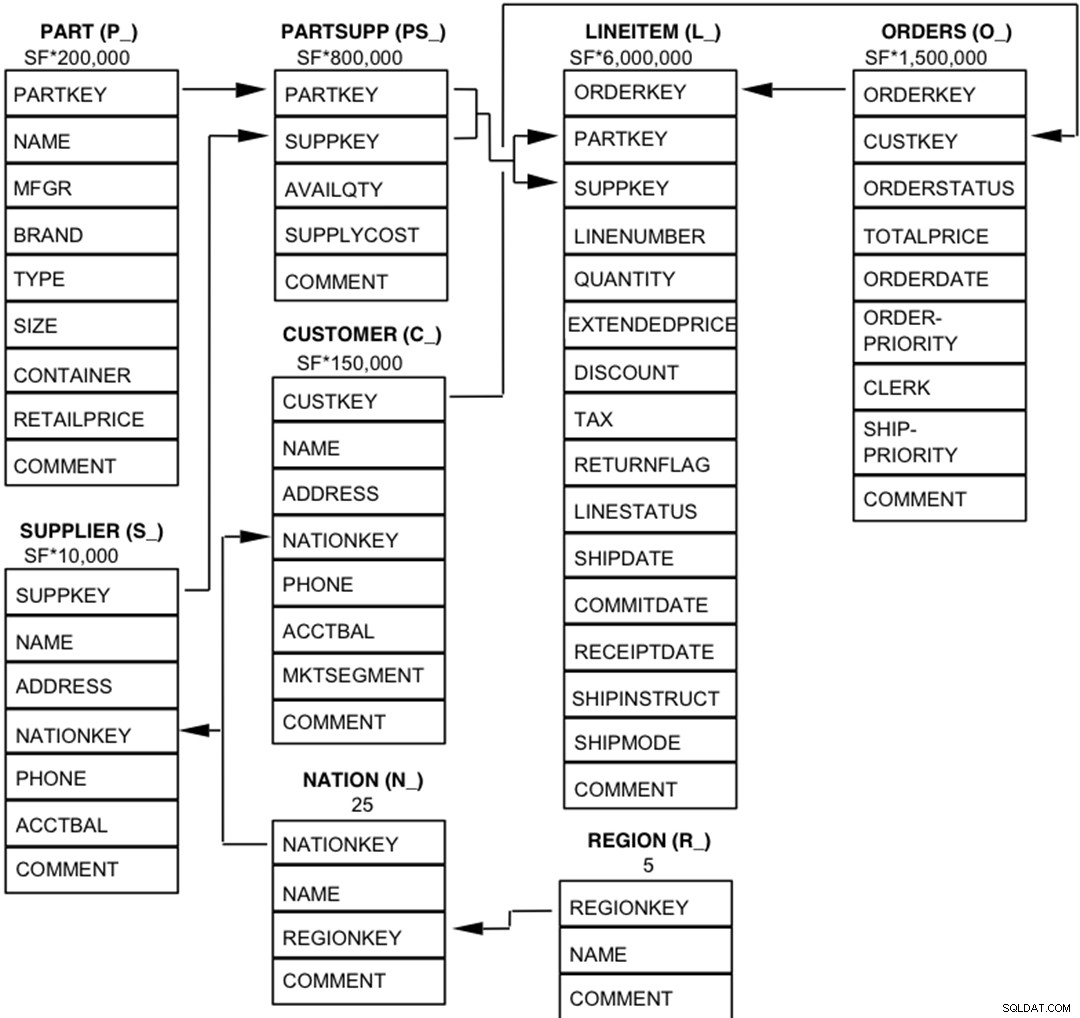 Legenda :
Legenda :
- Kurung di belakang setiap nama tabel berisi awalan nama kolom untuk tabel tersebut;
- Panah menunjuk ke arah hubungan satu-ke-banyak antar tabel
- Angka/rumus di bawah setiap nama tabel mewakili kardinalitas (jumlah baris) tabel. Beberapa difaktorkan oleh SF, Scale Factor, untuk mendapatkan ukuran database yang dipilih. Kardinalitas untuk tabel LINEITEM adalah perkiraan
2.3 Distribusi Data untuk Postgres-XL
Kami menganalisis semua 22 kueri dalam tolok ukur dan menghasilkan strategi distribusi data berikut untuk berbagai tabel dalam tolok ukur.
| Nama Tabel | Strategi Distribusi |
| LINEITEM | HASH (l_orderkey) |
| PESAN | HASH (o_orderkey) |
| BAGIAN | HASH (p_partkey) |
| PARTSUPP | HASH (ps_partkey) |
| PELANGGAN | DIREPLIKASI |
| PEMASOK | DIREPLIKASI |
| BANGSA | DIREPLIKASI |
| WILAYAH | REPLIKASI |
Perhatikan bahwa LINEITEM dan ORDERS yang merupakan tabel terbesar dalam benchmark sering digabungkan pada ORDERKEY. Jadi, sangat masuk akal untuk menempatkan tabel ini di ORDERKEY. Demikian pula, PART dan PARTSUPP sering digabungkan di PARTKEY dan karenanya mereka ditempatkan di kolom PARTKEY. Tabel lainnya direplikasi untuk memastikan bahwa tabel tersebut dapat digabungkan secara lokal, bila diperlukan.
3. Hasil Tolok Ukur
3.1 Uji Beban
Kami membandingkan hasil yang diperoleh dengan menjalankan Uji Beban TPC-H 3TB pada PostgreSQL 9.6 dengan klaster Postgres-XL 16-node. Bagan berikut menunjukkan karakteristik kinerja Postgres-XL.
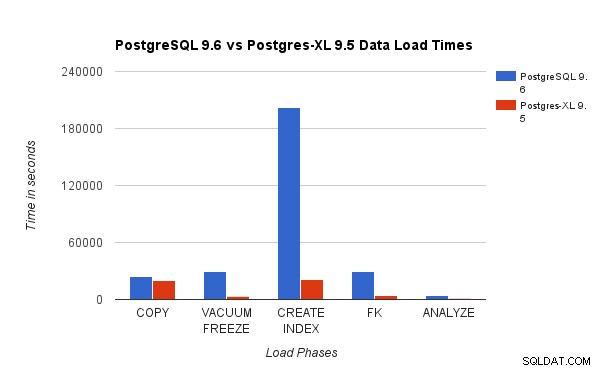 Bagan di atas menunjukkan waktu yang dibutuhkan untuk menyelesaikan berbagai fase Uji Beban dengan PostgreSQL dan Postgres-XL. Seperti yang terlihat, Postgres-XL berkinerja sedikit lebih baik untuk COPY dan jauh lebih baik untuk semua kasus lainnya. Catatan :Kami mengamati bahwa koordinator membutuhkan banyak daya komputasi selama fase SALIN, terutama ketika lebih dari satu aliran SALIN berjalan secara bersamaan. Untuk mengatasinya, koordinator dijalankan pada instans AWS yang dioptimalkan untuk komputasi dengan 16 vCPU. Atau, kita juga bisa menjalankan beberapa koordinator dan mendistribusikan beban komputasi di antara mereka.
Bagan di atas menunjukkan waktu yang dibutuhkan untuk menyelesaikan berbagai fase Uji Beban dengan PostgreSQL dan Postgres-XL. Seperti yang terlihat, Postgres-XL berkinerja sedikit lebih baik untuk COPY dan jauh lebih baik untuk semua kasus lainnya. Catatan :Kami mengamati bahwa koordinator membutuhkan banyak daya komputasi selama fase SALIN, terutama ketika lebih dari satu aliran SALIN berjalan secara bersamaan. Untuk mengatasinya, koordinator dijalankan pada instans AWS yang dioptimalkan untuk komputasi dengan 16 vCPU. Atau, kita juga bisa menjalankan beberapa koordinator dan mendistribusikan beban komputasi di antara mereka.
3.2 Uji Daya
Kami juga membandingkan waktu berjalan kueri untuk benchmark 3TB pada PostgreSQL 9.6 dan Postgres-XL 9.5. Bagan berikut menunjukkan karakteristik kinerja dari eksekusi kueri pada dua penyiapan.
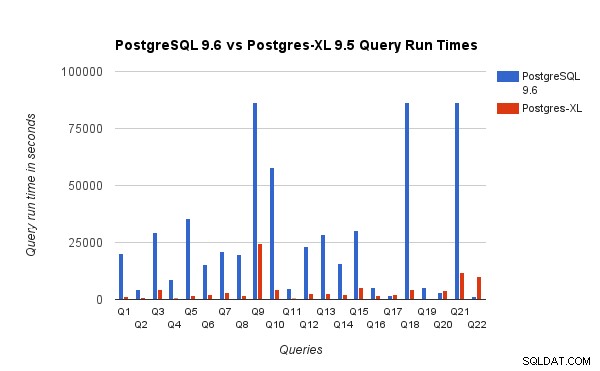 Kami mengamati bahwa rata-rata kueri berjalan sekitar 6,4 kali lebih cepat di Postgres-XL dan setidaknya 25% kueri menunjukkan peningkatan kinerja yang hampir linier, dengan kata lain kinerjanya hampir 16 kali lebih cepat pada klaster Postgres-XL 16-node ini. Selanjutnya setidaknya 50% dari kueri menunjukkan peningkatan kinerja 10 kali lipat. Kami menganalisis lebih lanjut kinerja kueri dan menyimpulkan bahwa kueri yang dipartisi dengan baik di semua node data yang tersedia, sehingga, ada sedikit pertukaran data antar node dan tanpa panggilan eksekusi jarak jauh berulang, skala sangat baik di Postgres-XL. Kueri semacam itu biasanya memiliki node Pemindaian Subquery Jarak Jauh di bagian atas dan subpohon di bawah node dieksekusi pada satu atau lebih node secara paralel. Juga umum untuk memiliki beberapa node lain seperti node Limit atau node Agregat di atas node Remote Subquery Scan. Bahkan kueri semacam itu berkinerja sangat baik di Postgres-XL. Kueri Q1 adalah contoh kueri yang harus diskalakan dengan sangat baik dengan Postgres-XL. Di sisi lain, kueri yang membutuhkan banyak pertukaran tupel antara datanode-datanode dan/atau koordinator-datanode mungkin tidak berjalan dengan baik di Postgres-XL. Demikian pula, kueri yang memerlukan banyak koneksi lintas simpul, juga dapat menunjukkan kinerja yang buruk. Misalnya, Anda akan melihat bahwa kinerja Q22 buruk dibandingkan dengan server PostgreSQL node tunggal. Ketika kami menganalisis rencana kueri untuk Q22, kami mengamati bahwa ada tiga tingkat node Pemindaian Subkueri Jarak Jauh bersarang dalam rencana kueri, di mana setiap node membuka jumlah koneksi yang sama ke node data. Lebih lanjut, Nest Loop Anti Join memiliki relasi dalam dengan node Pemindaian Subquery Jarak Jauh tingkat atas dan karenanya untuk setiap tupel relasi luar ia harus mengeksekusi subkueri jarak jauh. Ini menghasilkan kinerja eksekusi kueri yang buruk.
Kami mengamati bahwa rata-rata kueri berjalan sekitar 6,4 kali lebih cepat di Postgres-XL dan setidaknya 25% kueri menunjukkan peningkatan kinerja yang hampir linier, dengan kata lain kinerjanya hampir 16 kali lebih cepat pada klaster Postgres-XL 16-node ini. Selanjutnya setidaknya 50% dari kueri menunjukkan peningkatan kinerja 10 kali lipat. Kami menganalisis lebih lanjut kinerja kueri dan menyimpulkan bahwa kueri yang dipartisi dengan baik di semua node data yang tersedia, sehingga, ada sedikit pertukaran data antar node dan tanpa panggilan eksekusi jarak jauh berulang, skala sangat baik di Postgres-XL. Kueri semacam itu biasanya memiliki node Pemindaian Subquery Jarak Jauh di bagian atas dan subpohon di bawah node dieksekusi pada satu atau lebih node secara paralel. Juga umum untuk memiliki beberapa node lain seperti node Limit atau node Agregat di atas node Remote Subquery Scan. Bahkan kueri semacam itu berkinerja sangat baik di Postgres-XL. Kueri Q1 adalah contoh kueri yang harus diskalakan dengan sangat baik dengan Postgres-XL. Di sisi lain, kueri yang membutuhkan banyak pertukaran tupel antara datanode-datanode dan/atau koordinator-datanode mungkin tidak berjalan dengan baik di Postgres-XL. Demikian pula, kueri yang memerlukan banyak koneksi lintas simpul, juga dapat menunjukkan kinerja yang buruk. Misalnya, Anda akan melihat bahwa kinerja Q22 buruk dibandingkan dengan server PostgreSQL node tunggal. Ketika kami menganalisis rencana kueri untuk Q22, kami mengamati bahwa ada tiga tingkat node Pemindaian Subkueri Jarak Jauh bersarang dalam rencana kueri, di mana setiap node membuka jumlah koneksi yang sama ke node data. Lebih lanjut, Nest Loop Anti Join memiliki relasi dalam dengan node Pemindaian Subquery Jarak Jauh tingkat atas dan karenanya untuk setiap tupel relasi luar ia harus mengeksekusi subkueri jarak jauh. Ini menghasilkan kinerja eksekusi kueri yang buruk.
4. Beberapa Pelajaran AWS
Saat membandingkan Postgres-XL, kami mempelajari beberapa pelajaran tentang penggunaan AWS. Kami pikir mereka akan berguna bagi siapa saja yang ingin menggunakan/menguji Postgres-XL di AWS.
- AWS menawarkan beberapa jenis instans yang berbeda. Anda harus hati-hati mengevaluasi beban kerja dan jumlah penyimpanan yang diperlukan sebelum memilih jenis instans tertentu.
- Sebagian besar instance dengan penyimpanan yang dioptimalkan memiliki disk ephemeral yang terpasang padanya. Anda tidak perlu membayar tambahan apa pun untuk disk tersebut, disk tersebut terpasang ke instans dan sering kali berkinerja lebih baik daripada EBS. Tetapi Anda harus memasangnya secara eksplisit untuk dapat menggunakannya. Perlu diingat, data yang disimpan di disk ini tidak permanen dan akan dihapus jika instance dihentikan. Jadi pastikan Anda siap untuk menangani situasi itu. Karena kami menggunakan AWS sebagian besar untuk benchmarking, kami memutuskan untuk menggunakan disk ephemeral ini.
- Jika Anda menggunakan EBS, pastikan Anda memilih IOPS yang Disediakan yang sesuai. Nilai yang terlalu rendah akan menyebabkan IO yang sangat lambat, tetapi nilai yang sangat tinggi dapat meningkatkan tagihan AWS Anda secara substansial, terutama saat menangani sejumlah besar node.
- Pastikan Anda memulai instance di zona yang sama untuk mengurangi latensi dan meningkatkan throughput untuk koneksi di antara mereka.
- Pastikan Anda mengonfigurasi instance sehingga mereka menggunakan jaringan pribadi untuk berbicara satu sama lain.
- Lihat contoh tempat. Mereka relatif lebih murah. Karena AWS dapat menghentikan instans spot sesuka hati, misalnya, jika harga spot menjadi lebih dari harga bid maks Anda, bersiaplah untuk itu. Postgres-XL dapat menjadi tidak dapat digunakan sebagian atau seluruhnya tergantung pada node mana yang dihentikan. AWS mendukung konsep launch_group. Jika beberapa instance dikelompokkan dalam launch_group yang sama, jika AWS memutuskan untuk menghentikan satu instans, semua instans akan dihentikan.
5. Kesimpulan
Kami dapat menunjukkan, melalui berbagai tolok ukur, bahwa Postgres-XL dapat menskalakan dengan sangat baik untuk sekumpulan besar dunia nyata, kueri kompleks. Tolok ukur ini membantu kami menunjukkan kemampuan Postgres-XL sebagai solusi efektif untuk beban kerja OLAP. Eksperimen kami juga menunjukkan bahwa ada beberapa masalah kinerja dengan Postgres-XL, terutama untuk kluster yang sangat besar dan ketika perencana membuat pilihan rencana yang buruk. Kami juga mengamati bahwa ketika ada sejumlah besar koneksi bersamaan ke datanode, kinerjanya memburuk. Kami akan terus bekerja pada masalah kinerja ini. Kami juga ingin menguji kemampuan Postgres-XL sebagai solusi OLTP dengan menggunakan beban kerja yang sesuai.