Di salah satu mesin basis data relasional, diperlukan untuk menghasilkan rencana terbaik yang sesuai dengan eksekusi kueri dengan waktu dan sumber daya paling sedikit. Umumnya, semua database menghasilkan rencana dalam format struktur pohon, di mana simpul daun dari setiap pohon rencana disebut simpul pemindaian tabel. Node khusus dari rencana ini sesuai dengan algoritme yang akan digunakan untuk mengambil data dari tabel dasar.
Misalnya, pertimbangkan contoh kueri sederhana sebagai SELECT * FROM TBL1, TBL2 di mana TBL2.ID>1000; dan misalkan rencana yang dihasilkan adalah seperti di bawah ini:
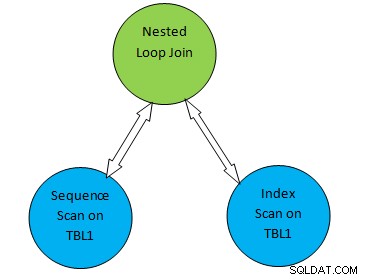
Jadi di pohon rencana di atas, “Pemindaian Berurutan pada TBL1” dan “ Pemindaian Indeks pada TBL2” sesuai dengan metode pemindaian tabel pada tabel TBL1 dan TBL2 masing-masing. Jadi sesuai rencana ini, TBL1 akan diambil secara berurutan dari halaman terkait dan TBL2 dapat diakses menggunakan INDEX Scan.
Memilih metode pemindaian yang tepat sebagai bagian dari rencana sangat penting dalam hal kinerja kueri secara keseluruhan.
Sebelum masuk ke semua jenis metode pemindaian yang didukung oleh PostgreSQL, mari kita merevisi beberapa poin utama yang akan sering digunakan saat kita menjelajahi blog.
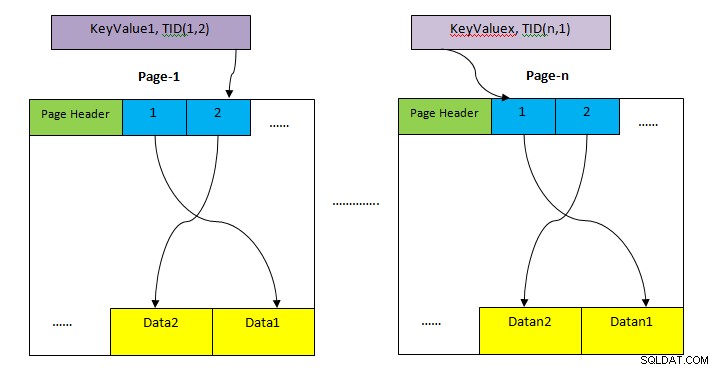
- TUMBUHAN: Area penyimpanan untuk menyimpan seluruh baris meja. Ini dibagi menjadi beberapa halaman (seperti yang ditunjukkan pada gambar di atas) dan setiap ukuran halaman secara default 8KB. Dalam setiap halaman, setiap penunjuk item (misalnya 1, 2, ….) menunjuk ke data di dalam halaman.
- Penyimpanan Indeks: Penyimpanan ini hanya menyimpan nilai kunci yaitu nilai kolom yang dikandung oleh indeks. Ini juga dibagi menjadi beberapa halaman dan setiap ukuran halaman secara default 8 KB.
- Pengidentifikasi Tuple (TID): TID adalah angka 6 byte yang terdiri dari dua bagian. Bagian pertama adalah nomor halaman 4-byte dan sisa 2 byte indeks tuple di dalam halaman. Kombinasi dua angka ini secara unik menunjuk ke lokasi penyimpanan untuk tupel tertentu.
Saat ini, PostgreSQL mendukung metode pemindaian di bawah ini yang dengannya semua data yang diperlukan dapat dibaca dari tabel:
- Pemindaian Berurutan
- Pemindaian Indeks
- Pemindaian Indeks Saja
- Pemindaian Bitmap
- Pemindaian TID
Masing-masing metode pemindaian ini sama-sama berguna bergantung pada kueri dan parameter lainnya, mis. kardinalitas tabel, selektivitas tabel, biaya I/O disk, biaya I/O acak, biaya I/O urutan, dll. Mari buat beberapa tabel pra-penyiapan dan isi dengan beberapa data, yang akan sering digunakan untuk menjelaskan metode pemindaian ini dengan lebih baik .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEJadi dalam contoh ini, satu juta catatan dimasukkan dan kemudian tabel dianalisis sehingga semua statistik mutakhir.
Pemindaian Berurutan
Seperti namanya, Pemindaian berurutan tabel dilakukan dengan memindai semua pointer item secara berurutan dari semua halaman tabel terkait. Jadi jika ada 100 halaman untuk tabel tertentu dan kemudian ada 1000 catatan di setiap halaman, sebagai bagian dari pemindaian sekuensial itu akan mengambil 100*1000 catatan dan memeriksa apakah cocok dengan tingkat isolasi dan juga sesuai dengan klausa predikat. Jadi, meskipun hanya 1 record yang dipilih sebagai bagian dari seluruh pemindaian tabel, ia harus memindai 100 ribu record untuk menemukan record yang memenuhi syarat sesuai ketentuan.
Sesuai tabel dan data di atas, kueri berikut akan menghasilkan pemindaian berurutan karena sebagian besar data dipilih.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)CATATAN
Meskipun tanpa menghitung dan membandingkan biaya paket, hampir tidak mungkin untuk mengetahui jenis pemindaian yang akan digunakan. Tetapi agar pemindaian sekuensial dapat digunakan, setidaknya kriteria di bawah ini harus cocok:
- Tidak ada Indeks yang tersedia pada kunci, yang merupakan bagian dari predikat.
- Mayoritas baris diambil sebagai bagian dari kueri SQL.
TIPS
Jika hanya sedikit % baris yang diambil dan predikatnya ada di satu (atau lebih) kolom, coba evaluasi kinerja dengan atau tanpa indeks.
Pemindaian Indeks
Tidak seperti Pemindaian Berurutan, Pemindaian indeks tidak mengambil semua catatan secara berurutan. Melainkan menggunakan struktur data yang berbeda (tergantung pada jenis indeks) yang sesuai dengan indeks yang terlibat dalam kueri dan menemukan klausa data yang diperlukan (sesuai predikat) dengan pemindaian yang sangat minimal. Kemudian entri yang ditemukan menggunakan pemindaian indeks menunjuk langsung ke data di area heap (seperti yang ditunjukkan pada gambar di atas), yang kemudian diambil untuk memeriksa visibilitas sesuai dengan tingkat isolasi. Jadi ada dua langkah untuk pemindaian indeks:
- Ambil data dari struktur data terkait indeks. Ini mengembalikan TID dari data yang sesuai di heap.
- Kemudian halaman heap terkait langsung diakses untuk mendapatkan seluruh data. Langkah tambahan ini diperlukan untuk alasan di bawah ini:
- Kueri mungkin meminta untuk mengambil kolom lebih dari apa pun yang tersedia di indeks yang sesuai.
- Informasi visibilitas tidak dipertahankan bersama dengan data indeks. Jadi untuk memeriksa visibilitas data sesuai tingkat isolasi, perlu mengakses data heap.
Sekarang kita mungkin bertanya-tanya mengapa tidak selalu menggunakan Pemindaian Indeks jika sangat efisien. Jadi seperti yang kita tahu semuanya datang dengan beberapa biaya. Di sini biaya yang terlibat terkait dengan jenis I/O yang kita lakukan. Dalam kasus Pemindaian Indeks, I/O Acak terlibat karena untuk setiap catatan yang ditemukan dalam penyimpanan indeks, ia harus mengambil data yang sesuai dari penyimpanan HEAP sedangkan dalam Pemindaian Sekuensial, I/O Urutan terlibat yang memakan waktu kira-kira hanya 25% waktu I/O acak.
Jadi, pemindaian Indeks harus dipilih hanya jika perolehan keseluruhan melebihi biaya overhead yang dikeluarkan karena biaya I/O Acak.
Sesuai tabel dan data di atas, kueri berikut akan menghasilkan pemindaian indeks karena hanya satu catatan yang dipilih. Jadi I/O acak lebih sedikit serta pencarian catatan yang sesuai menjadi cepat.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Pemindaian Indeks Saja
Index Only Scan mirip dengan Index Scan kecuali untuk langkah kedua yaitu seperti namanya hanya memindai struktur data indeks. Ada dua prasyarat tambahan untuk memilih Pemindaian Hanya Indeks dibandingkan dengan Pemindaian Indeks:
- Kueri harus mengambil hanya kolom kunci yang merupakan bagian dari indeks.
- Semua tupel (rekaman) pada halaman heap yang dipilih akan terlihat. Seperti yang dibahas di bagian sebelumnya, struktur data indeks tidak mempertahankan informasi visibilitas sehingga untuk memilih data hanya dari indeks, kita harus menghindari pemeriksaan visibilitas dan ini bisa terjadi jika semua data halaman itu dianggap terlihat.
Kueri berikut akan menghasilkan pemindaian indeks saja. Meskipun kueri ini hampir serupa dalam hal memilih jumlah catatan tetapi karena hanya bidang kunci (yaitu "num") yang dipilih, itu akan memilih Pemindaian Hanya Indeks.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Pemindaian Bitmap
Pemindaian bitmap adalah campuran Pemindaian Indeks dan Pemindaian Sekuensial. Ia mencoba untuk mengatasi kelemahan pemindaian Indeks tetapi tetap mempertahankan keuntungan penuhnya. Seperti dibahas di atas untuk setiap data yang ditemukan dalam struktur data indeks, perlu menemukan data yang sesuai di halaman heap. Jadi alternatifnya perlu mengambil halaman indeks sekali dan kemudian diikuti oleh halaman tumpukan, yang menyebabkan banyak I/O acak. Jadi metode pemindaian bitmap memanfaatkan manfaat pemindaian indeks tanpa I/O acak. Ini bekerja dalam dua tingkat seperti di bawah ini:
- Pemindaian Indeks Bitmap:Pertama ia mengambil semua data indeks dari struktur data indeks dan membuat peta bit semua TID. Untuk pemahaman sederhana, Anda dapat menganggap bitmap ini berisi hash dari semua halaman (hash berdasarkan no halaman) dan setiap entri halaman berisi larik semua offset di dalam halaman tersebut.
- Pemindaian Heap Bitmap:Sesuai dengan namanya, ia membaca bitmap halaman dan kemudian memindai data dari tumpukan yang sesuai dengan halaman dan offset yang disimpan. Pada akhirnya, ia memeriksa visibilitas dan predikat dll dan mengembalikan tupel berdasarkan hasil dari semua pemeriksaan ini.
Kueri di bawah ini akan menghasilkan pemindaian Bitmap karena tidak memilih sangat sedikit catatan (yaitu terlalu banyak untuk pemindaian indeks) dan pada saat yang sama tidak memilih sejumlah besar catatan (yaitu terlalu sedikit untuk berurutan pindai).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Sekarang pertimbangkan kueri di bawah ini, yang memilih jumlah catatan yang sama tetapi hanya bidang utama (yaitu hanya kolom indeks). Karena itu hanya memilih kunci, itu tidak perlu merujuk halaman tumpukan untuk bagian data lain dan karenanya tidak ada I/O acak yang terlibat. Jadi kueri ini akan memilih Pemindaian Hanya Indeks daripada Pemindaian Bitmap.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)Pemindaian TID
TID, sebagaimana disebutkan di atas, adalah 6 byte nomor yang terdiri dari 4-byte nomor halaman dan sisa 2 byte indeks tuple di dalam halaman. Pemindaian TID adalah jenis pemindaian yang sangat spesifik di PostgreSQL dan dipilih hanya jika ada TID dalam predikat kueri. Pertimbangkan kueri di bawah ini yang menunjukkan Pemindaian TID:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Jadi di sini di predikat, alih-alih memberikan nilai kolom yang tepat sebagai kondisi, TID disediakan. Ini mirip dengan pencarian berbasis ROWID di Oracle.
Bonus
Semua metode pemindaian digunakan secara luas dan terkenal. Juga, metode pemindaian ini tersedia di hampir semua basis data relasional. Tetapi ada metode pemindaian lain baru-baru ini dalam diskusi di komunitas PostgreSQL dan juga baru-baru ini ditambahkan di database relasional lainnya. Ini disebut "Loose IndexScan" di MySQL, "Index Skip Scan" di Oracle dan "Jump Scan" di DB2.
Metode pemindaian ini digunakan untuk skenario tertentu di mana nilai yang berbeda dari kolom kunci utama indeks B-Tree dipilih. Sebagai bagian dari pemindaian ini, ia menghindari melintasi semua nilai kolom kunci yang sama daripada hanya melintasi nilai unik pertama dan kemudian melompat ke yang besar berikutnya.
Pekerjaan ini masih berlangsung di PostgreSQL dengan nama tentatif sebagai "Index Skip Scan" dan kami mungkin berharap untuk melihatnya di rilis mendatang.