Data mungkin merupakan salah satu aset paling berharga dalam sebuah perusahaan. Karena itu kita harus selalu memiliki Disaster Recovery Plan (DRP) untuk mencegah kehilangan data jika terjadi kecelakaan atau kegagalan perangkat keras.
Cadangan adalah bentuk DR yang paling sederhana, namun mungkin tidak selalu cukup untuk menjamin Tujuan Titik Pemulihan (RPO) yang dapat diterima. Disarankan agar Anda memiliki setidaknya tiga cadangan yang disimpan di tempat fisik yang berbeda.
Praktik terbaik menentukan file cadangan harus disimpan secara lokal di server database (untuk pemulihan yang lebih cepat), yang lain di server cadangan terpusat, dan yang terakhir di cloud.
Untuk blog ini, kita akan melihat opsi yang disediakan Amazon AWS untuk penyimpanan cadangan PostgreSQL di cloud dan kami akan menunjukkan beberapa contoh tentang cara melakukannya.
Tentang Amazon AWS
Amazon AWS adalah salah satu penyedia cloud tercanggih di dunia dalam hal fitur dan layanan, dengan jutaan pelanggan. Jika kami ingin menjalankan database PostgreSQL kami di Amazon AWS, kami memiliki beberapa opsi...
-
Amazon RDS:Ini memungkinkan kita untuk membuat, mengelola, dan menskalakan database PostgreSQL (atau teknologi database yang berbeda) di cloud dengan cara yang mudah dan cepat.
-
Amazon Aurora:Ini adalah database yang kompatibel dengan PostgreSQL yang dibuat untuk cloud. Menurut situs web AWS, ini tiga kali lebih cepat daripada database PostgreSQL standar.
-
Amazon EC2:Ini adalah layanan web yang menyediakan kapasitas komputasi yang dapat diubah ukurannya di cloud. Ini memberi Anda kendali penuh atas sumber daya komputasi Anda dan memungkinkan Anda menyiapkan dan mengonfigurasi segala sesuatu tentang instans Anda dari sistem operasi hingga aplikasi Anda.
Namun, pada kenyataannya, kami tidak perlu menjalankan database kami di Amazon untuk menyimpan cadangan kami di sini.
Menyimpan Cadangan di Amazon AWS
Ada berbagai opsi untuk menyimpan cadangan PostgreSQL kami di AWS. Jika kami menjalankan database PostgreSQL kami di AWS, kami memiliki lebih banyak opsi dan (karena kami berada di jaringan yang sama) itu juga bisa lebih cepat. Mari kita lihat bagaimana AWS dapat membantu kami menyimpan cadangan kami.
AWS CLI
Pertama, mari siapkan lingkungan kita untuk menguji berbagai opsi AWS. Sebagai contoh, kami akan menggunakan server PostgreSQL 11 lokal, yang berjalan di CentOS 7. Di sini, kami perlu menginstal AWS CLI dengan mengikuti petunjuk dari situs ini.
Setelah AWS CLI kami terinstal, kami dapat mengujinya dari baris perintah:
[example@sqldat.com ~]# aws --version
aws-cli/1.16.225 Python/2.7.5 Linux/4.15.18-14-pve botocore/1.12.215Sekarang, langkah selanjutnya adalah mengonfigurasi klien baru kami yang menjalankan perintah aws dengan opsi konfigurasi.
[example@sqldat.com ~]# aws configure
AWS Access Key ID [None]: AKIA7TMEO21BEBR1A7HR
AWS Secret Access Key [None]: SxrCECrW/RGaKh2FTYTyca7SsQGNUW4uQ1JB8hRp
Default region name [None]: us-east-1
Default output format [None]:Untuk mendapatkan informasi ini, Anda dapat membuka Bagian IAM AWS dan memeriksa pengguna saat ini, atau jika mau, Anda dapat membuat yang baru untuk tugas ini.
Setelah ini, kami siap menggunakan AWS CLI untuk mengakses layanan Amazon AWS kami.
Amazon S3
Ini mungkin opsi yang paling umum digunakan untuk menyimpan cadangan di awan. Amazon S3 dapat menyimpan dan mengambil data dalam jumlah berapa pun dari mana saja di Internet. Ini adalah layanan penyimpanan sederhana yang menawarkan infrastruktur penyimpanan data yang sangat tahan lama, sangat tersedia, dan dapat diskalakan tanpa batas dengan biaya rendah.
Amazon S3 menyediakan antarmuka layanan web sederhana yang dapat Anda gunakan untuk menyimpan dan mengambil data dalam jumlah berapa pun, kapan saja, dari mana saja di web, dan (dengan AWS CLI atau AWS SDK) Anda dapat mengintegrasikannya dengan sistem dan bahasa pemrograman yang berbeda.
Cara menggunakannya
Amazon S3 menggunakan Bucket. Mereka adalah wadah unik untuk semua yang Anda simpan di Amazon S3. Jadi, langkah pertama adalah mengakses Konsol Manajemen Amazon S3 dan membuat Bucket baru.
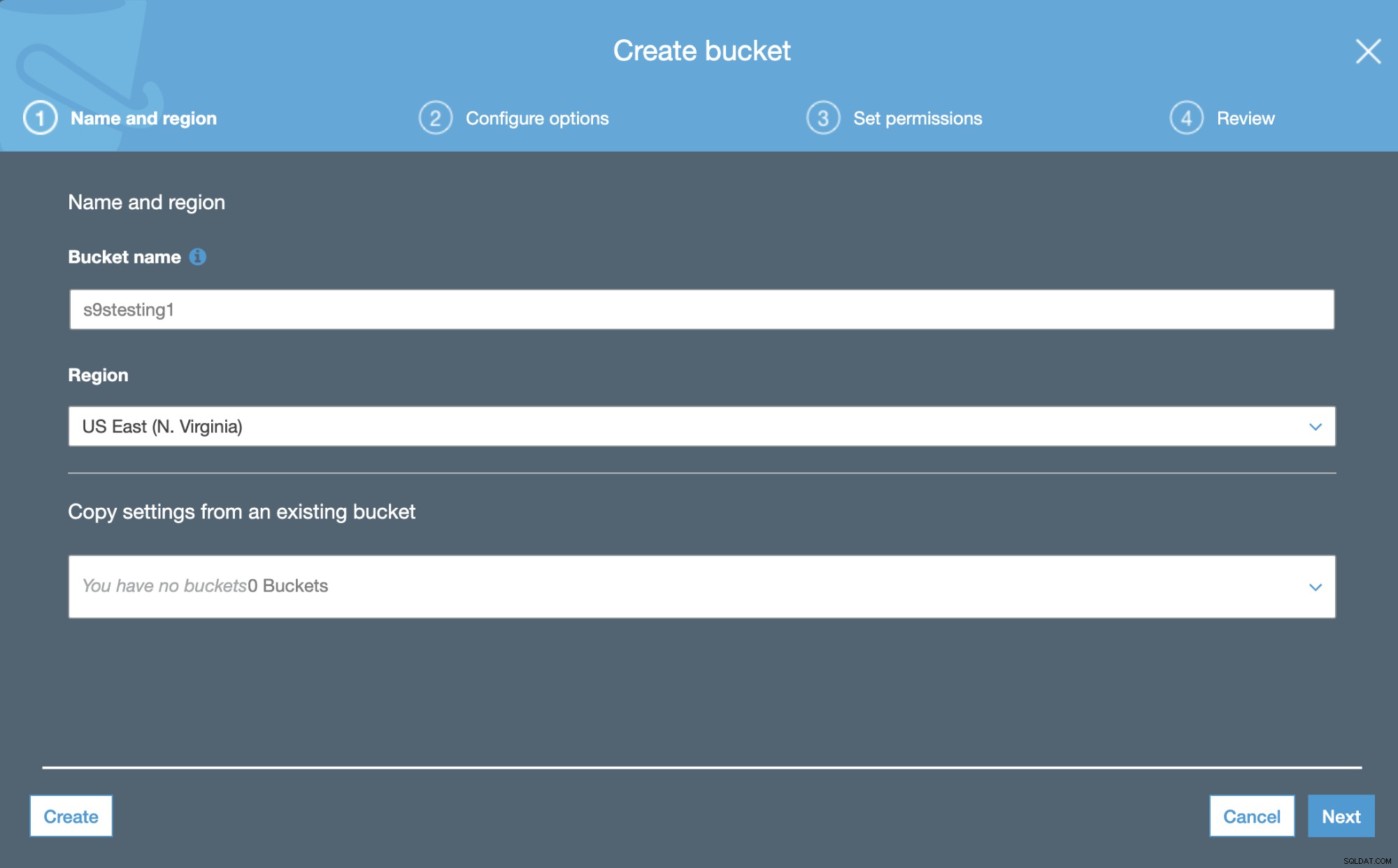
Pada langkah pertama, kita hanya perlu menambahkan nama Bucket dan Wilayah AWS.
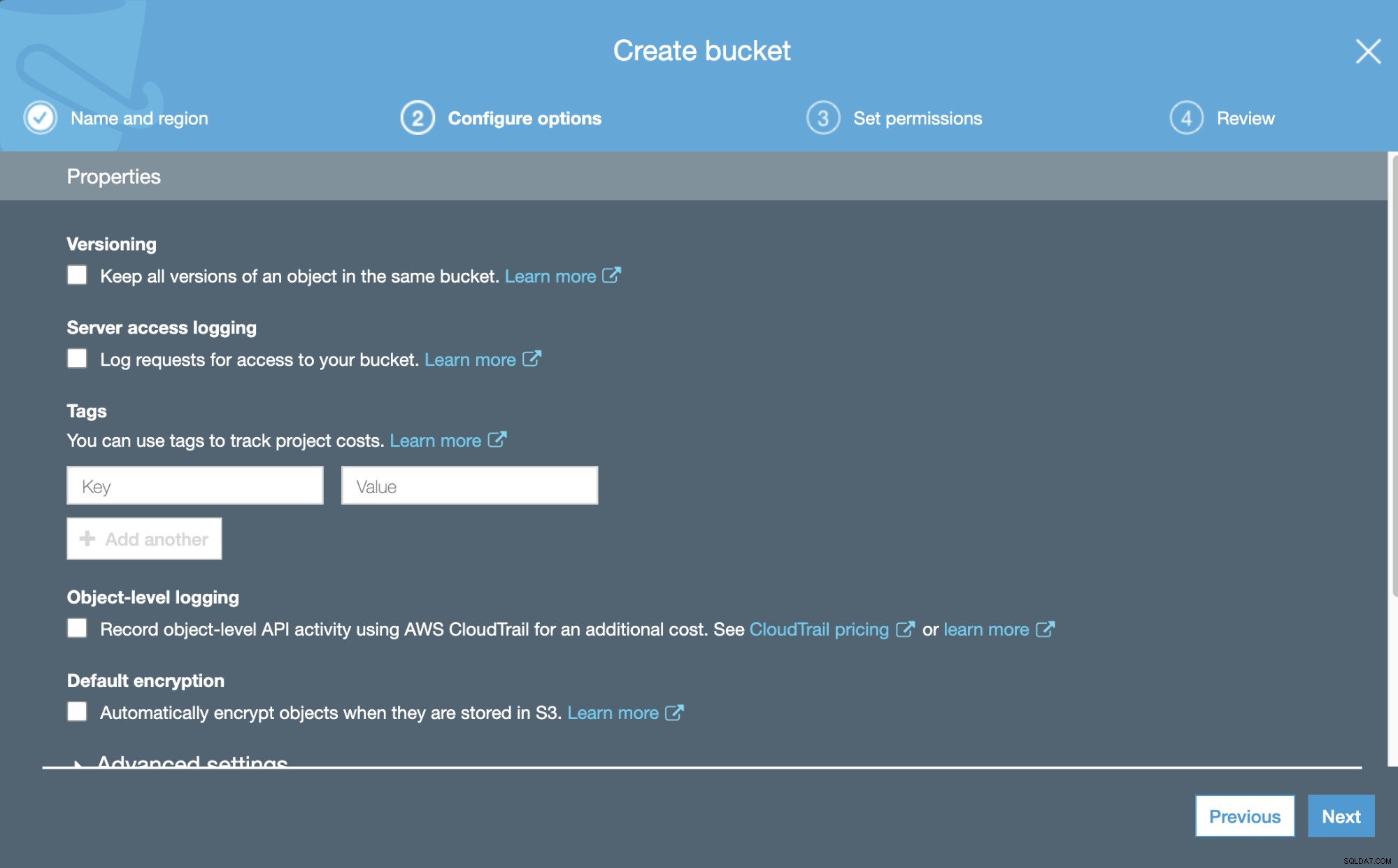
Sekarang, kita dapat mengonfigurasi beberapa detail tentang Bucket baru kita, seperti pembuatan versi dan masuk.

Kemudian, kita dapat menentukan izin untuk Bucket baru ini.
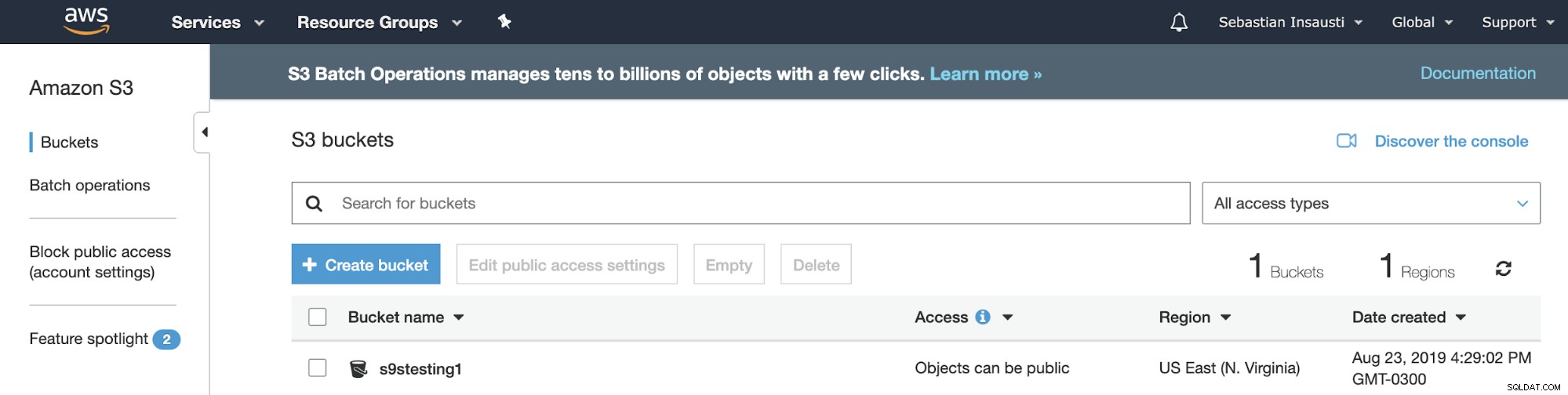
Sekarang Bucket kita telah dibuat, mari kita lihat bagaimana kita dapat menggunakannya untuk simpan cadangan PostgreSQL kami.
Pertama, mari kita uji klien kita menghubungkannya ke S3.
[example@sqldat.com ~]# aws s3 ls
2019-08-23 19:29:02 s9stesting1Berhasil! Dengan perintah sebelumnya, kami mencantumkan Bucket yang dibuat saat ini.
Jadi, sekarang, kita tinggal mengupload backup ke layanan S3. Untuk ini, kita dapat menggunakan perintah aws sync atau aws cp.
[example@sqldat.com ~]# aws s3 sync /root/backups/BACKUP-5/ s3://s9stesting1/backups/
upload: backups/BACKUP-5/cmon_backup.metadata to s3://s9stesting1/backups/cmon_backup.metadata
upload: backups/BACKUP-5/cmon_backup.log to s3://s9stesting1/backups/cmon_backup.log
upload: backups/BACKUP-5/base.tar.gz to s3://s9stesting1/backups/base.tar.gz
[example@sqldat.com ~]#
[example@sqldat.com ~]# aws s3 cp /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz s3://s9stesting1/backups/
upload: backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz to s3://s9stesting1/backups/pg_dump_2019-08-23_205919.sql.gz
[example@sqldat.com ~]# Kami dapat memeriksa konten Bucket dari situs web AWS.
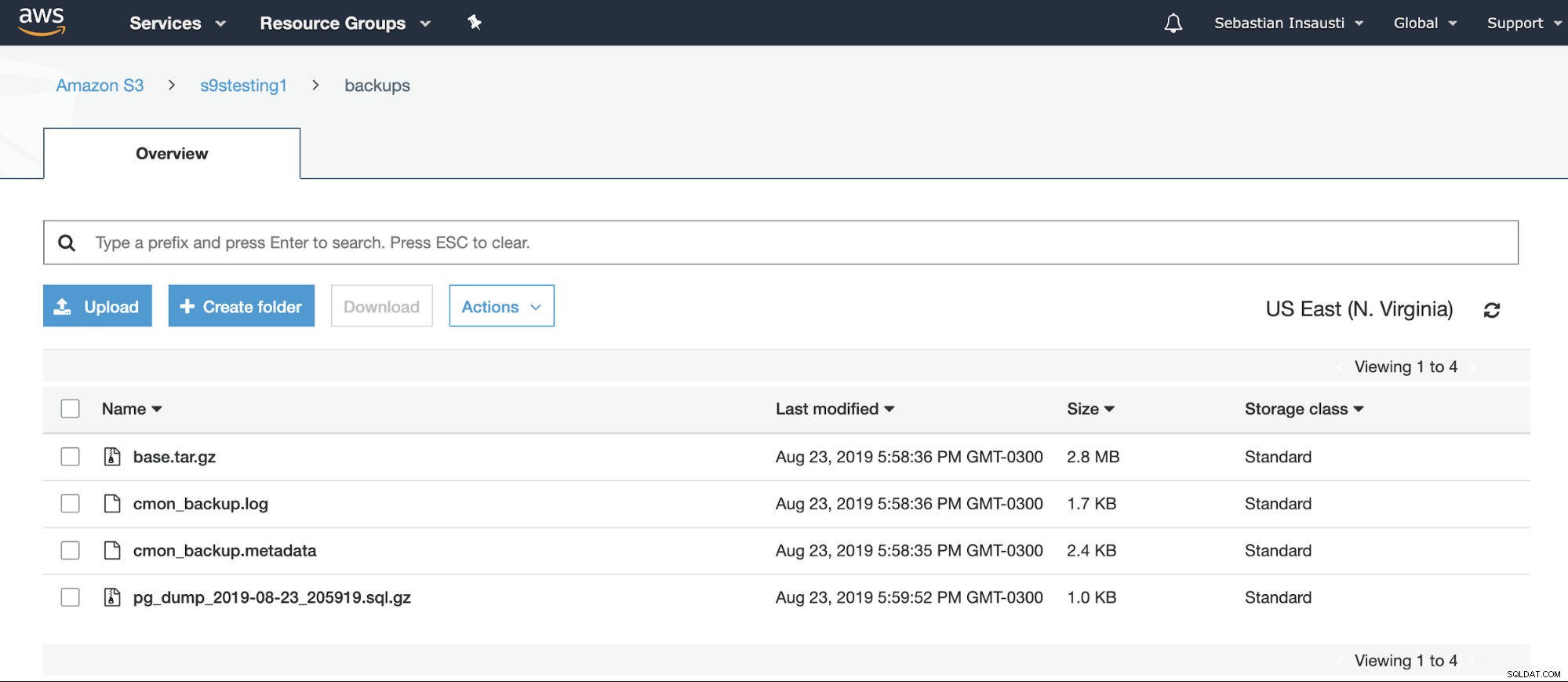
Atau bahkan dengan menggunakan AWS CLI.
[example@sqldat.com ~]# aws s3 ls s3://s9stesting1/backups/
2019-08-23 19:29:31 0
2019-08-23 20:58:36 2974633 base.tar.gz
2019-08-23 20:58:36 1742 cmon_backup.log
2019-08-23 20:58:35 2419 cmon_backup.metadata
2019-08-23 20:59:52 1028 pg_dump_2019-08-23_205919.sql.gzUntuk informasi selengkapnya tentang AWS S3 CLI, Anda dapat memeriksa dokumentasi resmi AWS.
Gletser Amazon S3
Ini adalah versi Amazon S3 yang lebih murah. Perbedaan utama di antara mereka adalah kecepatan dan aksesibilitas. Anda dapat menggunakan Amazon S3 Glacier jika biaya penyimpanan harus tetap rendah dan Anda tidak memerlukan akses milidetik ke data Anda. Penggunaan adalah perbedaan penting lainnya di antara keduanya.
Cara menggunakannya
Sebagai ganti Bucket, Amazon S3 Glacier menggunakan Vault. Ini adalah wadah untuk menyimpan objek apa pun. Jadi, langkah pertama adalah mengakses Amazon S3 Glacier Management Console dan membuat Vault baru.
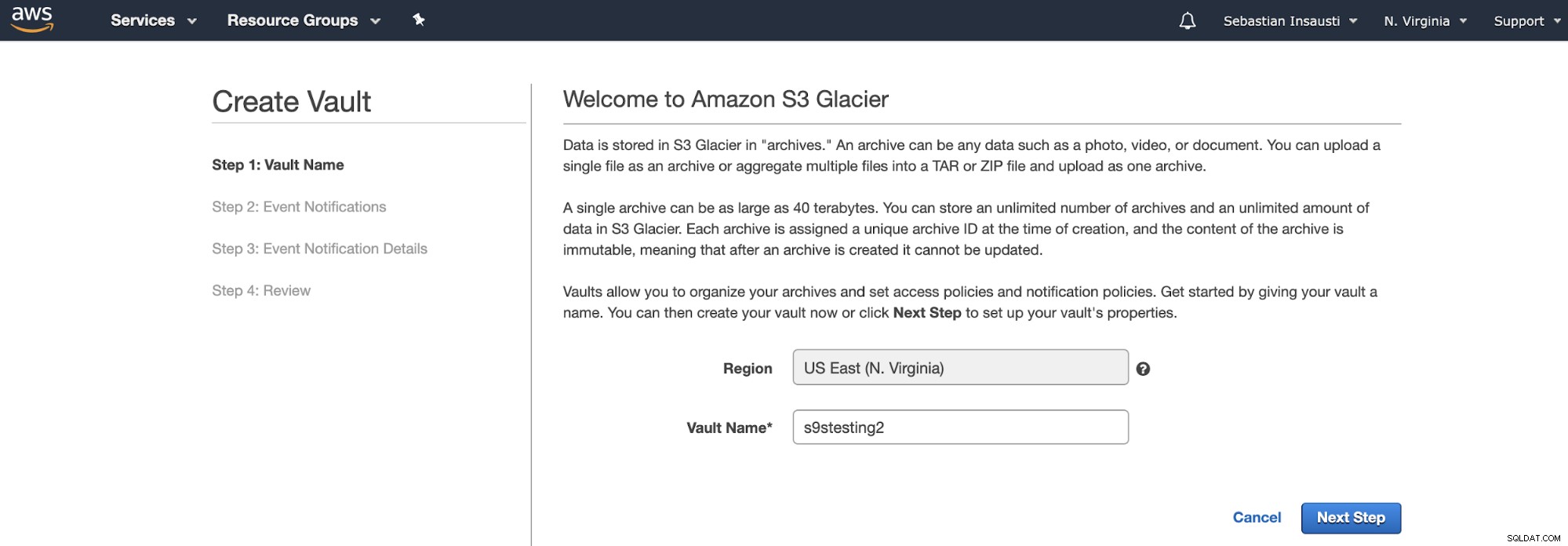
Di sini, kita perlu menambahkan Nama Vault dan Wilayah dan, di langkah selanjutnya, kita bisa mengaktifkan notifikasi event yang menggunakan Amazon Simple Notification Service (Amazon SNS).
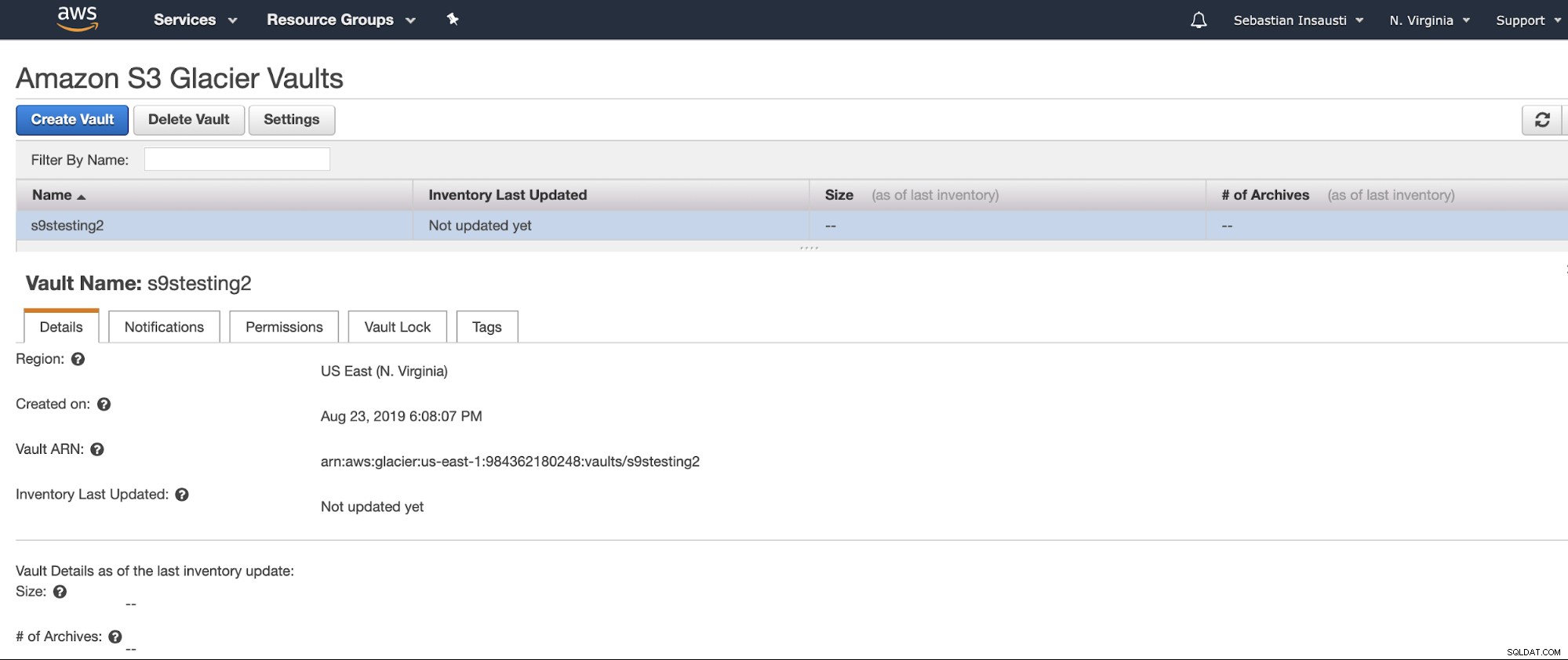
Sekarang kami telah membuat Vault, kami dapat mengaksesnya dari AWS CLI .
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 0,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"NumberOfArchives": 0,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Berhasil. Jadi sekarang, kami dapat mengunggah cadangan kami di sini.
[example@sqldat.com ~]# aws glacier upload-archive --body /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz --account-id - --archive-description "Backup upload test" --vault-name s9stesting2
{
"archiveId": "ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg",
"checksum": "258faaa90b5139cfdd2fb06cb904fe8b0c0f0f80cba9bb6f39f0d7dd2566a9aa",
"location": "/984227183428/vaults/s9stesting2/archives/ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg"
}Satu hal yang penting adalah status Vault diperbarui sekitar satu kali per hari, jadi kami harus menunggu untuk melihat file yang diunggah.
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 33796,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"LastInventoryDate": "2019-08-24T06:37:02.598Z",
"NumberOfArchives": 1,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Di sini kami memiliki file yang diunggah di S3 Glacier Vault kami.
Untuk informasi selengkapnya tentang AWS Glacier CLI, Anda dapat memeriksa dokumentasi resmi AWS.
EC2
Opsi penyimpanan cadangan ini lebih mahal dan memakan waktu, tetapi ini berguna jika Anda ingin memiliki kontrol penuh atas lingkungan penyimpanan cadangan dan ingin melakukan tugas khusus pada cadangan (mis. .)
Amazon EC2 (Elastic Compute Cloud) adalah layanan web yang menyediakan kapasitas komputasi yang dapat diubah ukurannya di cloud. Ini memberi Anda kendali penuh atas sumber daya komputasi Anda dan memungkinkan Anda mengatur dan mengonfigurasi segala sesuatu tentang instans Anda dari sistem operasi hingga aplikasi Anda. Ini juga memungkinkan Anda menskalakan kapasitas dengan cepat, baik ke atas maupun ke bawah, saat persyaratan komputasi Anda berubah.
Amazon EC2 mendukung berbagai sistem operasi seperti Amazon Linux, Ubuntu, Windows Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Fedora, Debian, CentOS, Gentoo Linux, Oracle Linux, dan FreeBSD.
Cara menggunakannya
Buka bagian Amazon EC2, dan tekan Launch Instance. Pada langkah pertama, Anda harus memilih sistem operasi instans EC2.
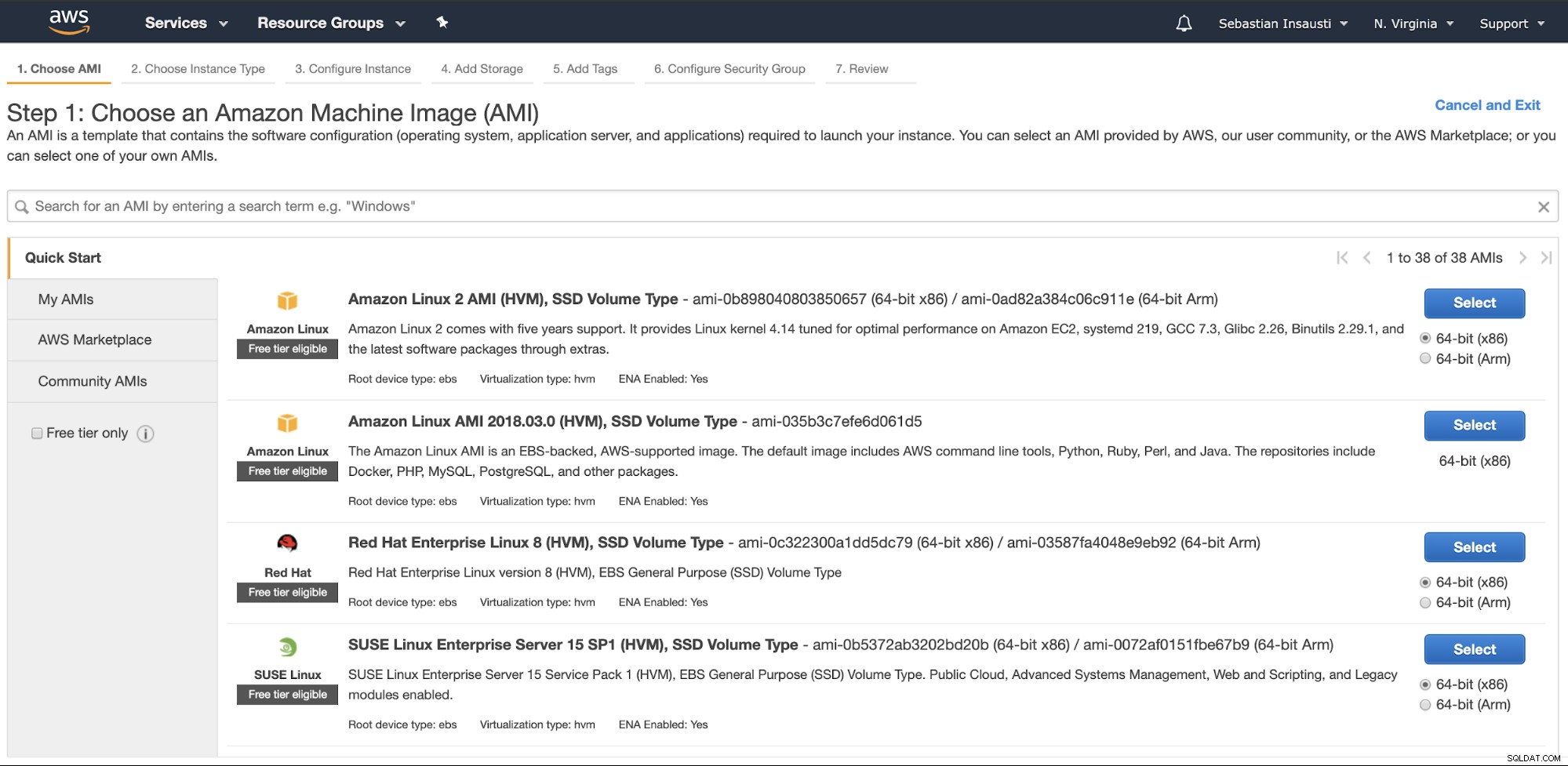
Pada langkah berikutnya, Anda harus memilih sumber daya untuk instance baru.
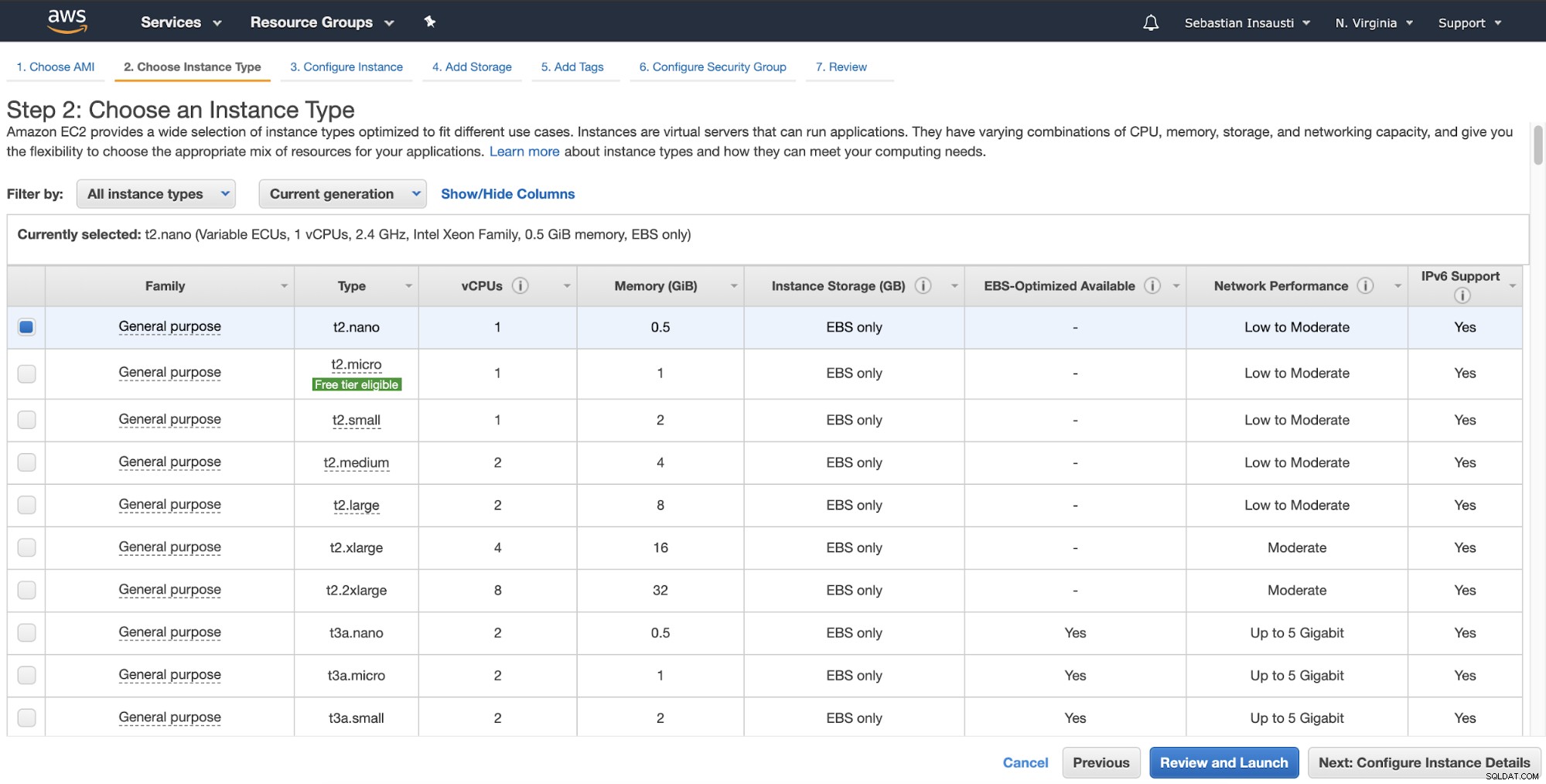
Kemudian, Anda dapat menentukan konfigurasi yang lebih detail seperti jaringan, subnet, dan lainnya .
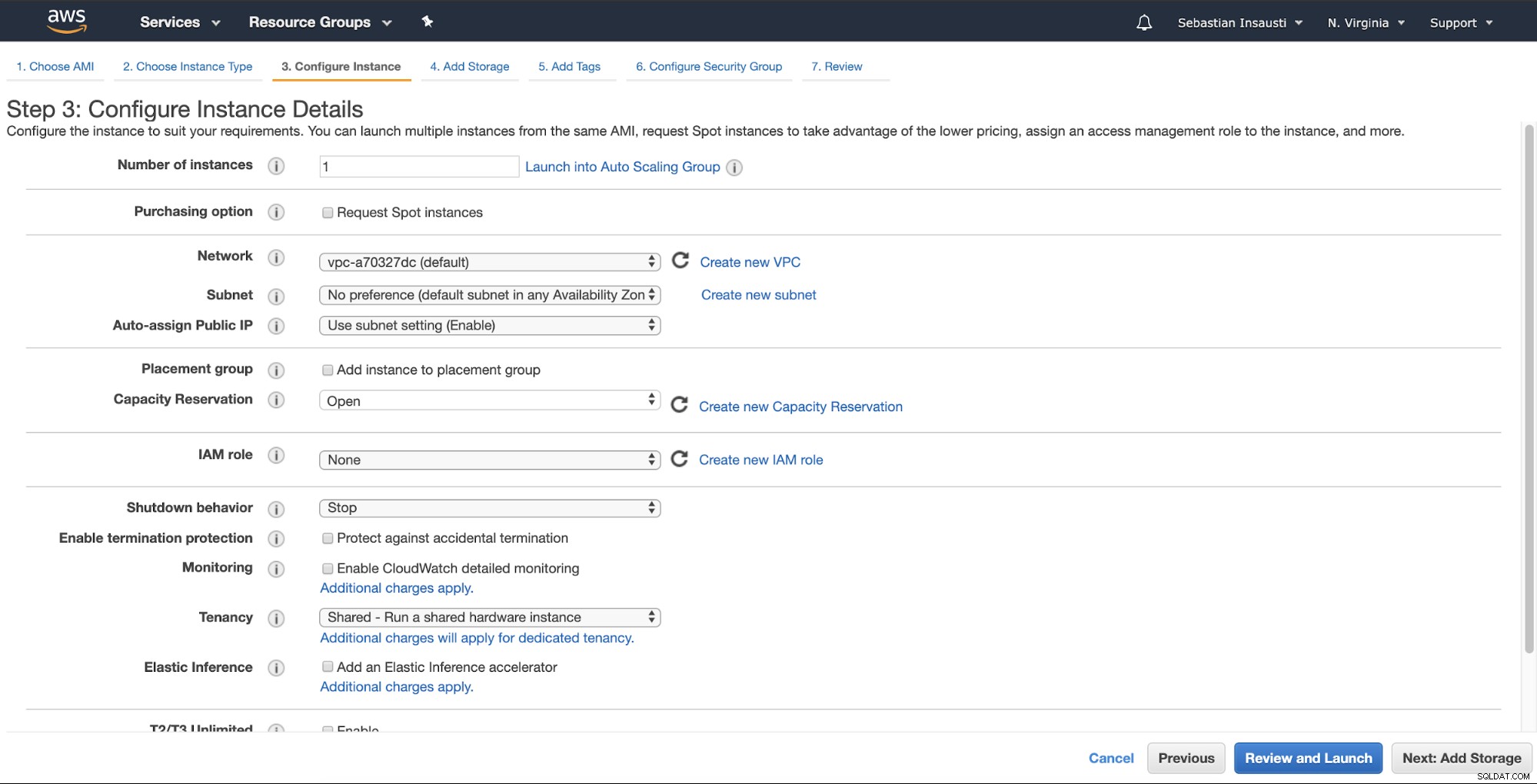
Sekarang, kita dapat menambahkan lebih banyak kapasitas penyimpanan pada instance baru ini, dan sebagai server cadangan, kita harus melakukannya.
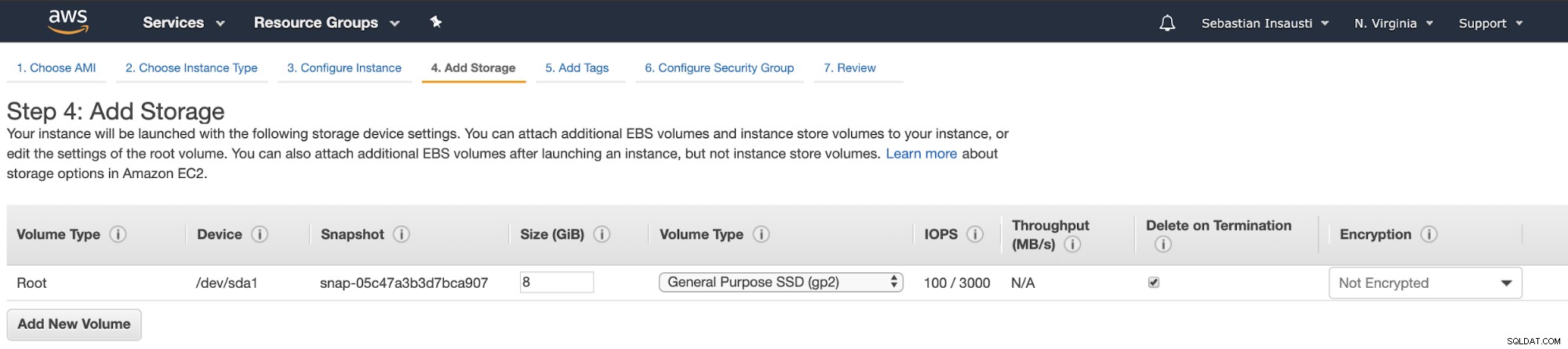
Setelah menyelesaikan tugas pembuatan, kita dapat membuka bagian Instances untuk lihat instans EC2 baru kami.
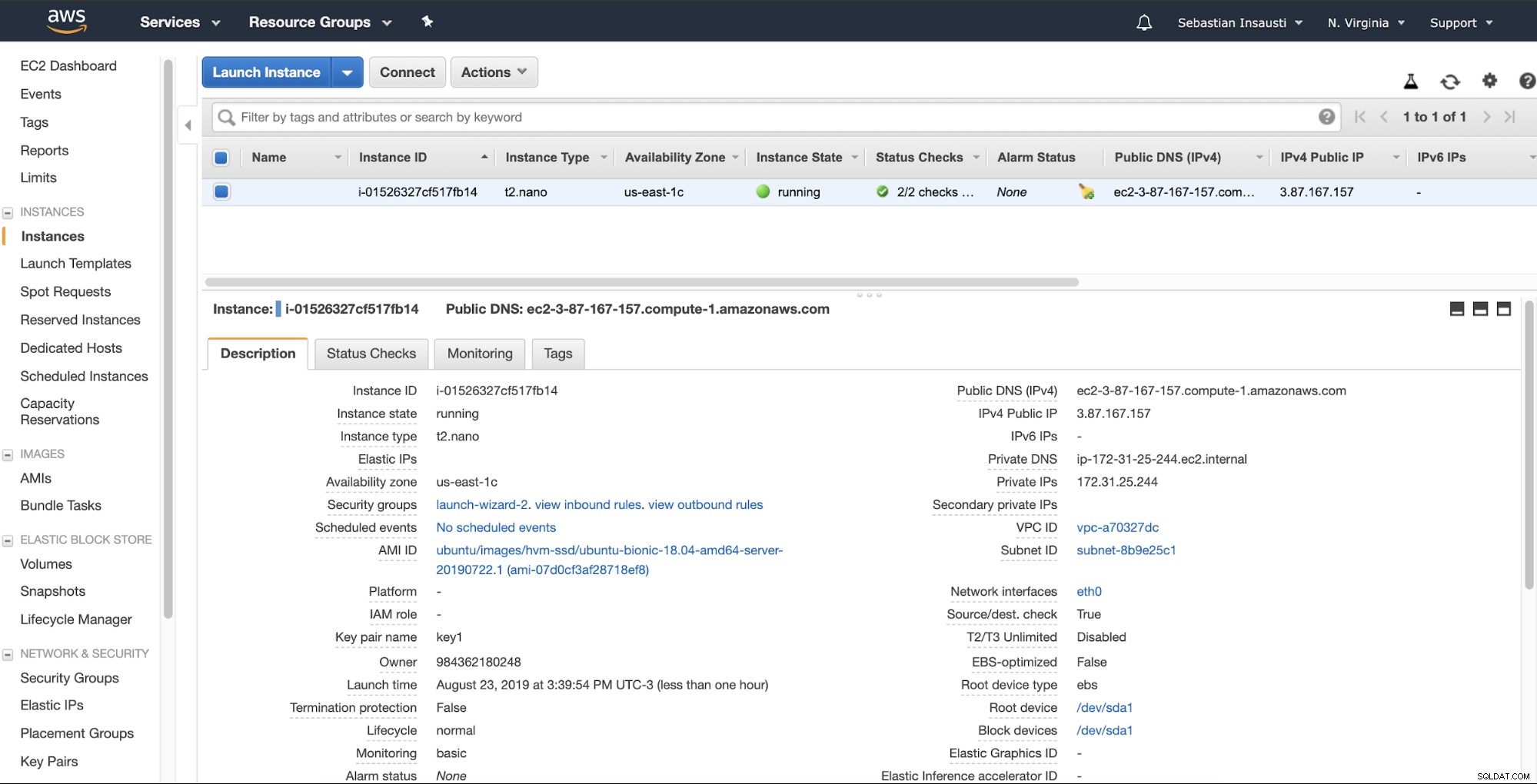
Saat instans siap (Status Instans berjalan), Anda dapat menyimpan backup di sini, misalnya, mengirimkannya melalui SSH atau FTP menggunakan DNS Publik yang dibuat oleh AWS. Mari kita lihat contoh dengan Rsync dan satu lagi dengan perintah SCP Linux.
[example@sqldat.com ~]# rsync -avzP -e "ssh -i /home/user/key1.pem" /root/backups/BACKUP-11/base.tar.gz example@sqldat.com:/backups/20190823/
sending incremental file list
base.tar.gz
4,091,563 100% 2.18MB/s 0:00:01 (xfr#1, to-chk=0/1)
sent 3,735,675 bytes received 35 bytes 574,724.62 bytes/sec
total size is 4,091,563 speedup is 1.10
[example@sqldat.com ~]#
[example@sqldat.com ~]# scp -i /tmp/key1.pem /root/backups/BACKUP-12/pg_dump_2019-08-25_211903.sql.gz example@sqldat.com:/backups/20190823/
pg_dump_2019-08-25_211903.sql.gz 100% 24KB 76.4KB/s 00:00Cadangan AWS
AWS Backup adalah layanan pencadangan terpusat yang memberi Anda kemampuan manajemen pencadangan, seperti penjadwalan pencadangan, pengelolaan retensi, dan pemantauan pencadangan, serta fitur tambahan, seperti daur ulang pencadangan ke biaya rendah tingkat penyimpanan, penyimpanan cadangan, dan enkripsi yang independen dari data sumbernya, dan kebijakan akses cadangan.
Anda dapat menggunakan AWS Backup untuk mengelola cadangan volume EBS, database RDS, tabel DynamoDB, sistem file EFS, dan volume Storage Gateway.
Cara menggunakannya
Buka bagian AWS Backup di AWS Management Console.
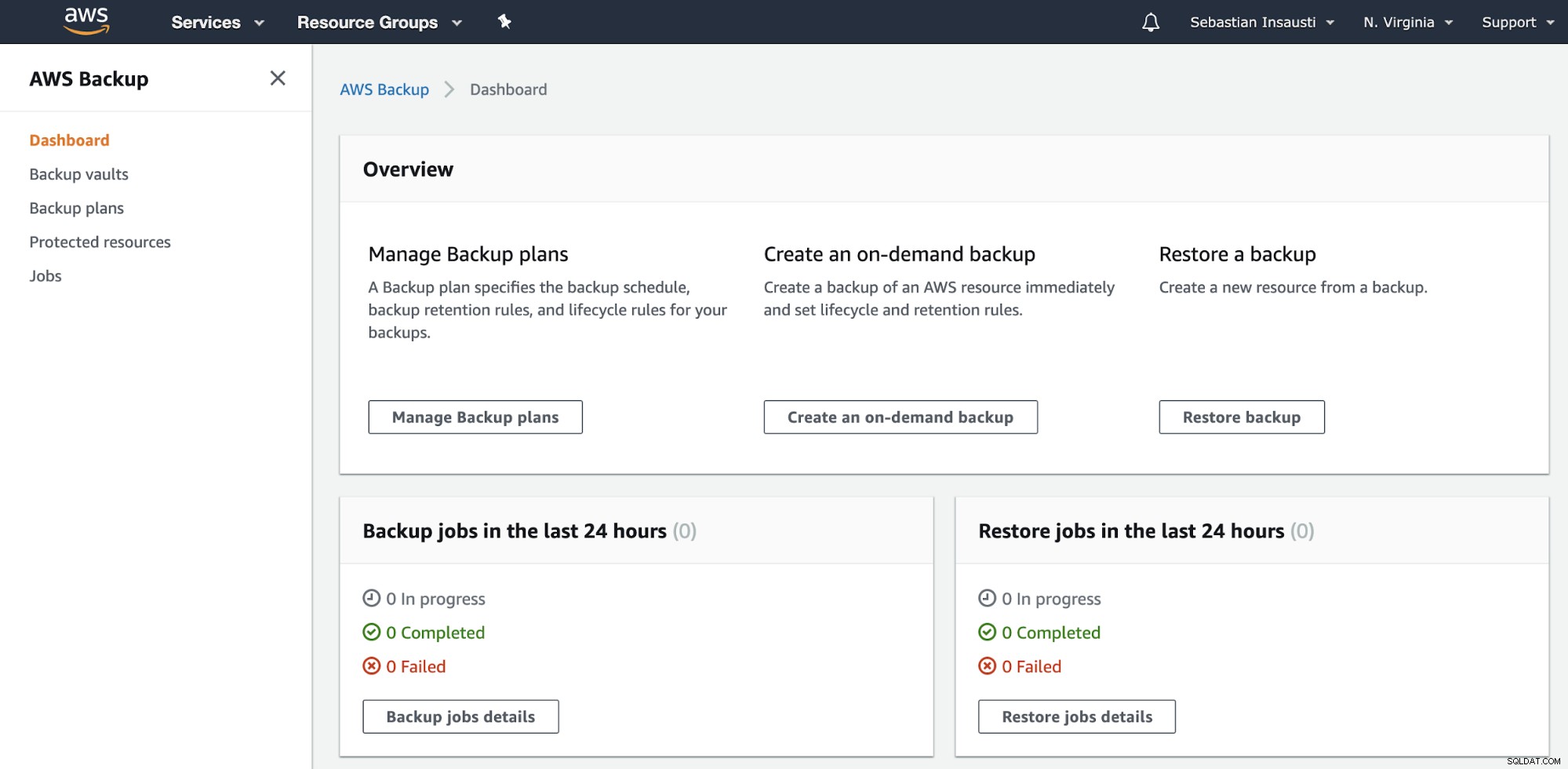
Di sini Anda memiliki opsi yang berbeda, seperti Jadwalkan, Buat, atau Pulihkan cadangan . Mari kita lihat cara membuat cadangan baru.
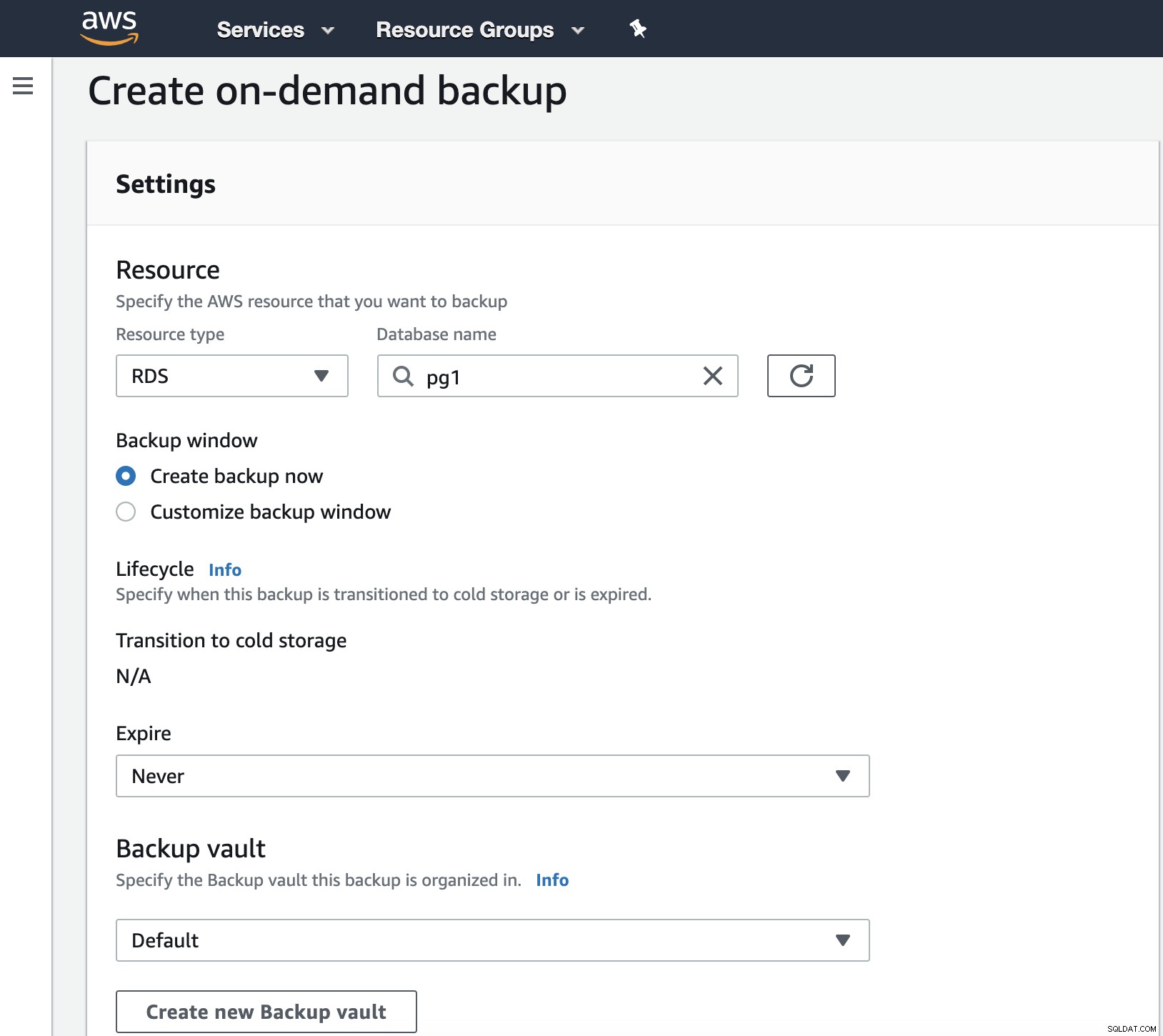
Pada langkah ini kita harus memilih Resource Type yang bisa DynamoDB, RDS, EBS, EFS atau Storage Gateway, dan detail lainnya seperti tanggal kedaluwarsa, brankas cadangan, dan Peran IAM.
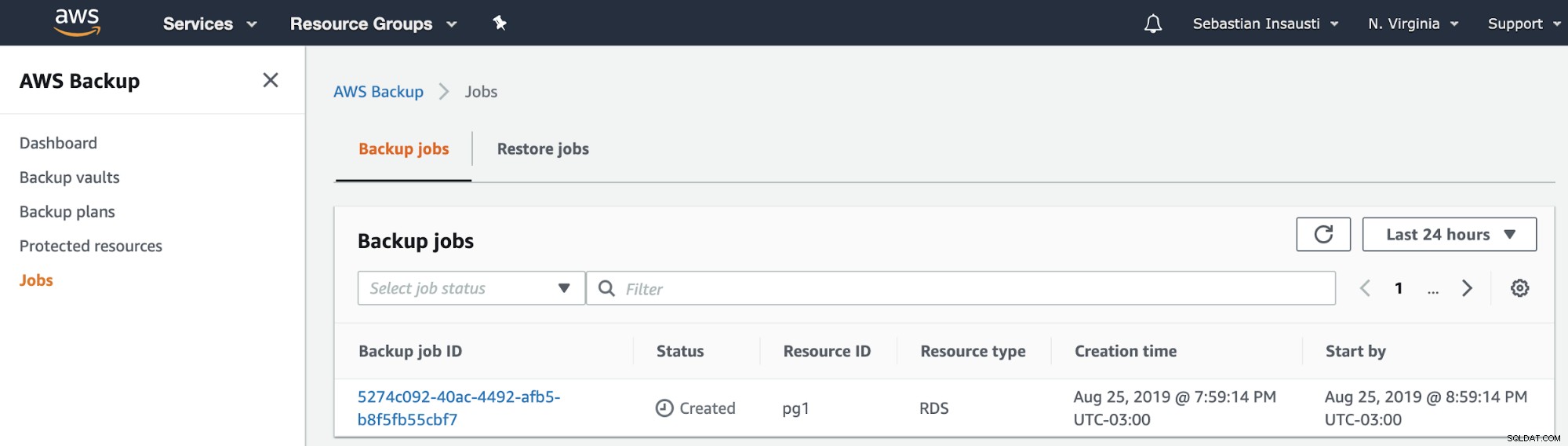
Kemudian, kita dapat melihat pekerjaan baru yang dibuat di bagian Pekerjaan Cadangan AWS .
Snapshot
Sekarang, kita dapat menyebutkan opsi yang dikenal ini di semua lingkungan virtualisasi. Snapshot adalah cadangan yang diambil pada titik waktu tertentu, dan AWS memungkinkan kami menggunakannya untuk produk AWS. Mari kita contoh snapshot RDS.
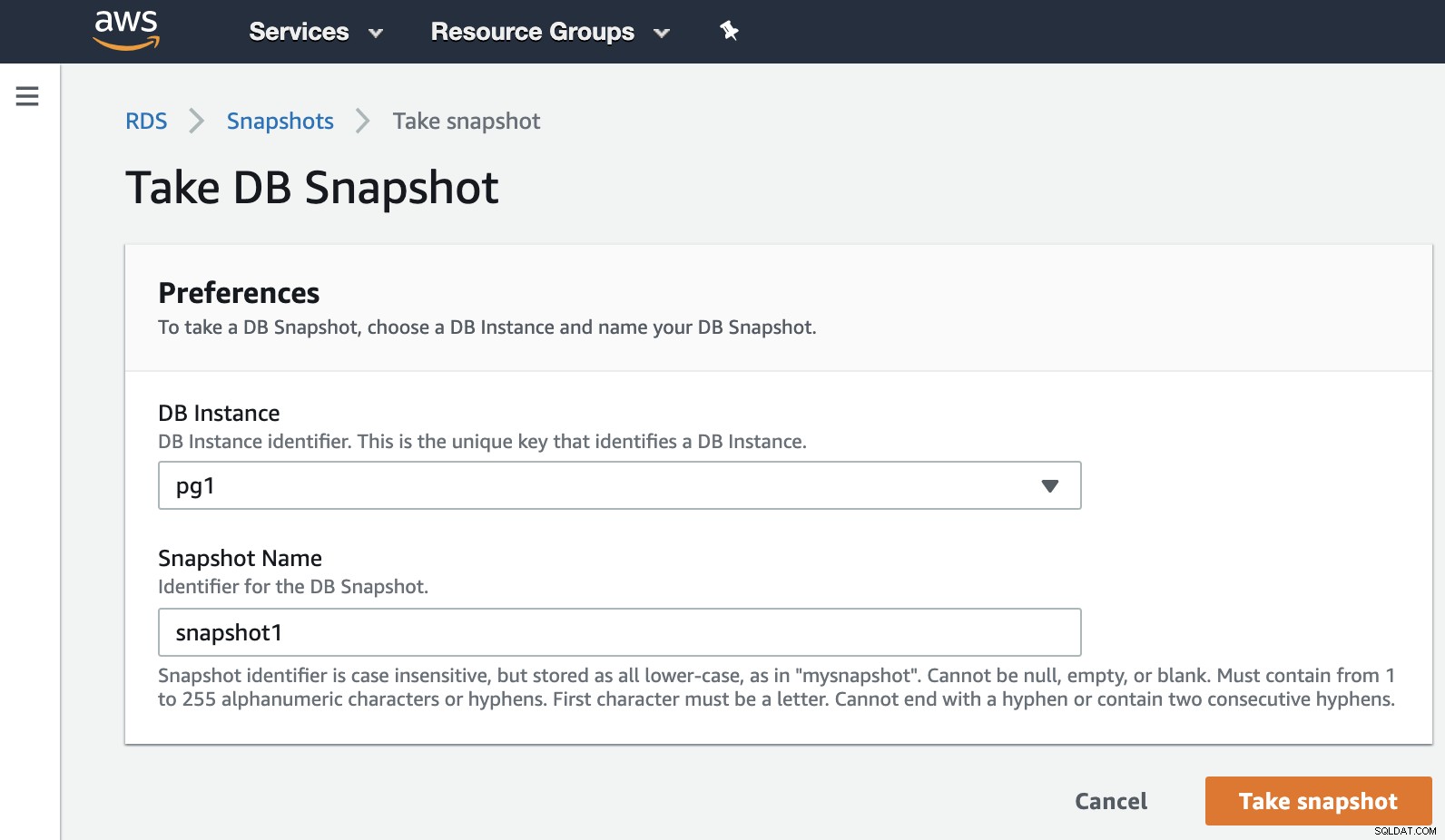
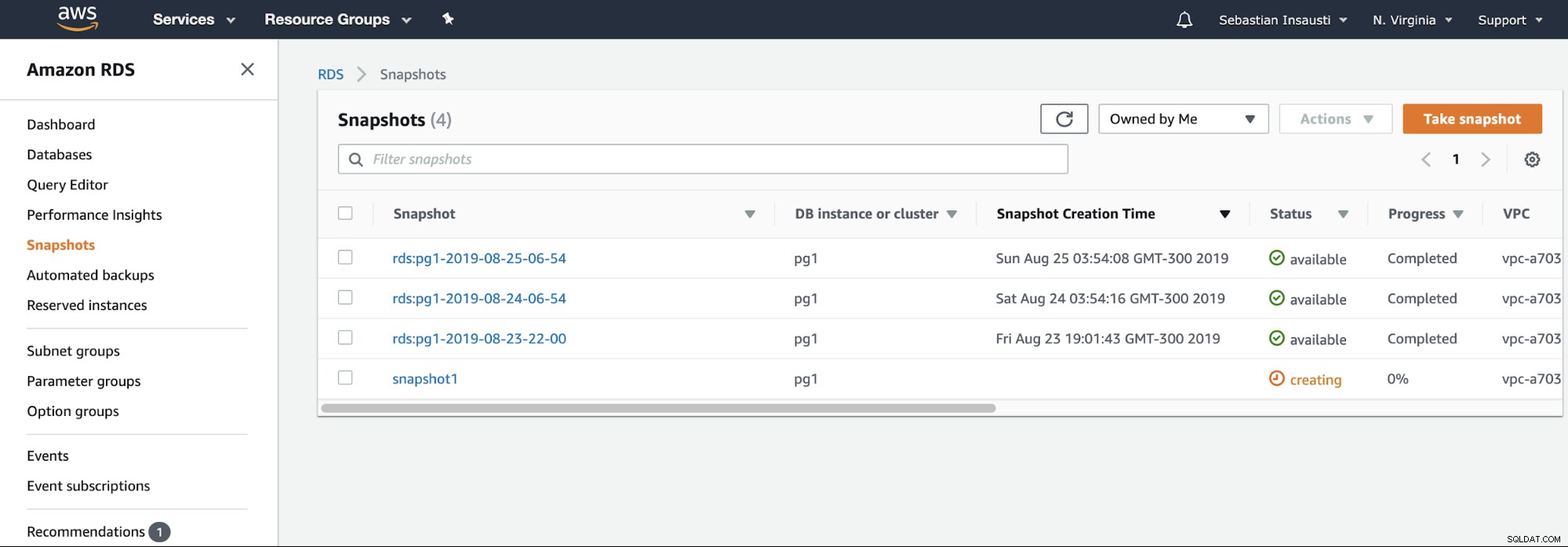
Kita hanya perlu memilih instance dan menambahkan nama snapshot, dan itu dia. Kita dapat melihat ini dan snapshot sebelumnya di bagian Snapshot RDS.
Mengelola Cadangan Anda dengan ClusterControl
ClusterControl adalah sistem manajemen komprehensif untuk database open source yang mengotomatiskan fungsi penerapan dan manajemen, serta pemantauan kesehatan dan kinerja. ClusterControl mendukung penerapan, manajemen, pemantauan, dan penskalaan untuk berbagai teknologi dan lingkungan basis data, termasuk EC2. Jadi, kita dapat, misalnya, membuat instans EC2 di AWS, dan menerapkan/mengimpor layanan database dengan ClusterControl.

Membuat Cadangan
Untuk tugas ini, buka ClusterControl -> Pilih Cluster -> Backup -> Create Backup.
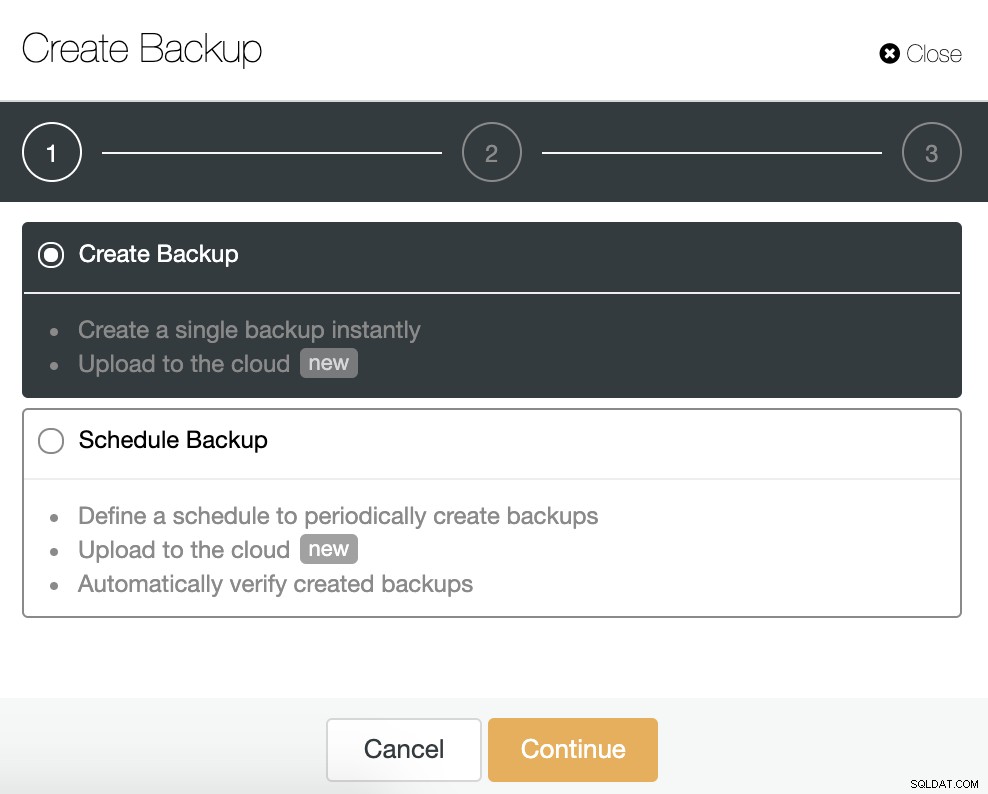
Kita dapat membuat cadangan baru atau mengonfigurasi yang dijadwalkan. Sebagai contoh, kami akan membuat satu cadangan secara instan.
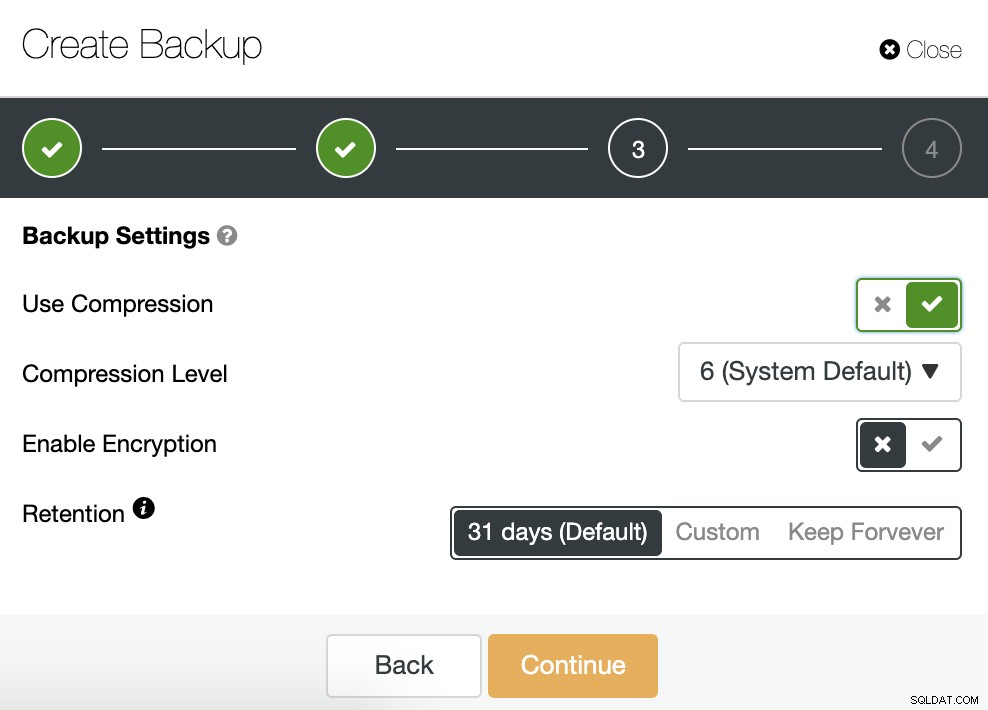
Kita harus memilih satu metode, server dari mana backup akan diambil , dan di mana kita ingin menyimpan cadangan. Kami juga dapat mengunggah cadangan kami ke cloud (AWS, Google, atau Azure) dengan mengaktifkan tombol yang sesuai.
Kemudian kita tentukan penggunaan kompresi, level kompresi, enkripsi dan retensi periode untuk cadangan kami.
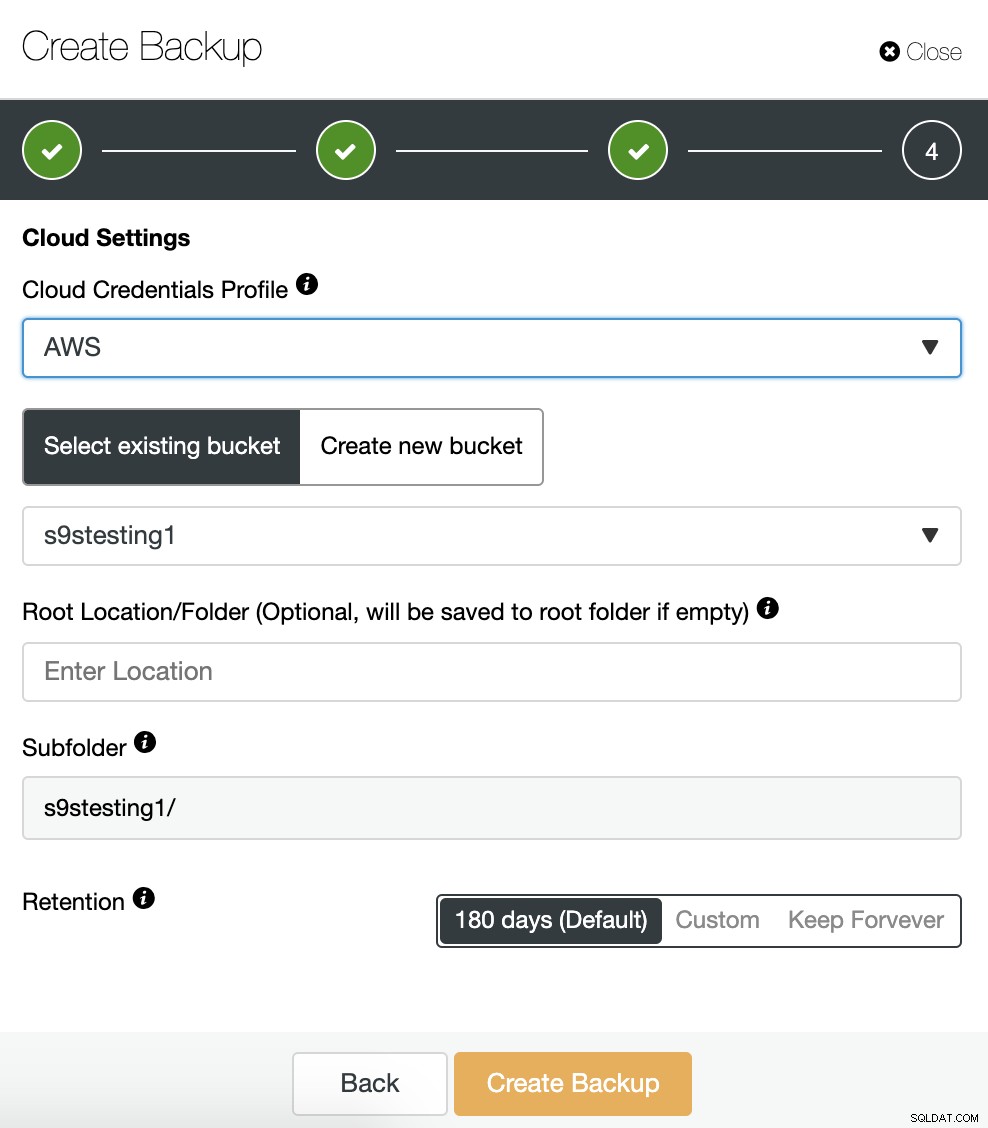
Jika kami mengaktifkan opsi unggah cadangan ke awan, kami akan melihat bagian untuk menentukan penyedia cloud (dalam hal ini AWS) dan kredensial (ClusterControl -> Integrations -> Cloud Providers). Untuk AWS, ini menggunakan layanan S3, jadi kami harus memilih Bucket atau bahkan membuat Bucket baru untuk menyimpan cadangan kami.
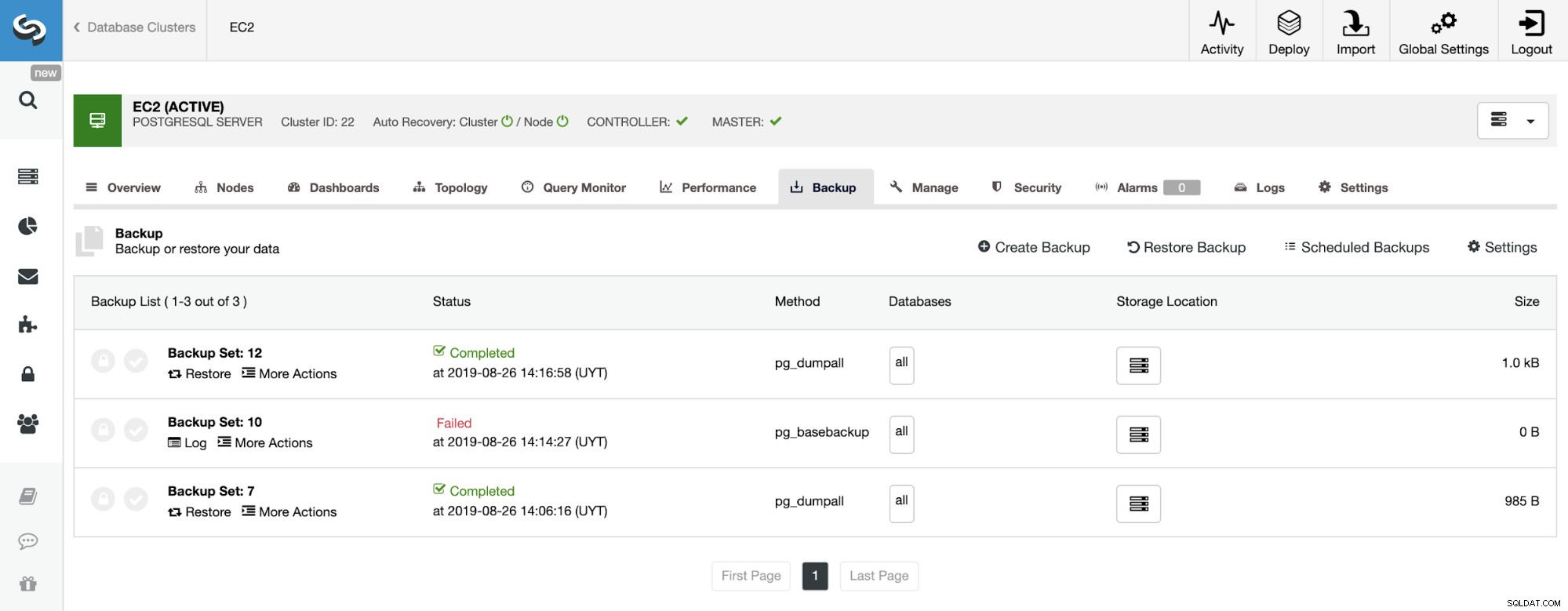
Pada bagian pencadangan, kita dapat melihat kemajuan pencadangan, dan informasi seperti metode, ukuran, lokasi, dan lainnya.
Kesimpulan
Amazon AWS memungkinkan kami untuk menyimpan cadangan PostgreSQL kami, baik kami menggunakannya sebagai penyedia cloud database atau tidak. Untuk memiliki rencana pencadangan yang efektif, Anda harus mempertimbangkan untuk menyimpan setidaknya satu salinan cadangan basis data di cloud untuk menghindari kehilangan data jika terjadi kegagalan perangkat keras di penyimpanan cadangan lain. Cloud memungkinkan Anda menyimpan cadangan sebanyak yang ingin Anda simpan atau bayar.