Di blog saya sebelumnya, kami membahas berbagai cara untuk memilih, atau memindai, data dari satu tabel. Namun dalam praktiknya, mengambil data dari satu tabel saja tidak cukup. Hal ini membutuhkan pemilihan data dari beberapa tabel dan kemudian mengkorelasikan di antara mereka. Korelasi data antar tabel ini disebut join table dan dapat dilakukan dengan berbagai cara. Karena penggabungan tabel memerlukan data input (misalnya dari pemindaian tabel), itu tidak akan pernah bisa menjadi simpul daun dalam rencana yang dihasilkan.
Misalnya. pertimbangkan contoh kueri sederhana sebagai SELECT * FROM TBL1, TBL2 di mana TBL1.ID> TBL2.ID; dan misalkan rencana yang dihasilkan adalah seperti di bawah ini:
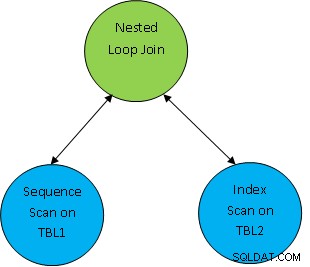
Jadi di sini pertama kedua tabel dipindai dan kemudian digabungkan menjadi satu per kondisi korelasi sebagai TBL.ID> TBL2.ID
Selain metode join, urutan join juga sangat penting. Perhatikan contoh di bawah ini:
PILIH * DARI TBL1, TBL2, TBL3 WHERE TBL1.ID=TBL2.ID AND TBL2.ID=TBL3.ID;
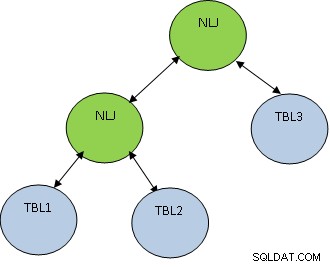
Pertimbangkan bahwa TBL1, TBL2 DAN TBL3 masing-masing memiliki 10, 100 dan 1000 record.
Kondisi TBL1.ID=TBL2.ID hanya mengembalikan 5 record, sedangkan TBL2.ID=TBL3.ID mengembalikan 100 record, maka sebaiknya gabungkan TBL1 dan TBL2 terlebih dahulu agar jumlah record yang didapat lebih sedikit bergabung dengan TBL3. Rencananya akan seperti yang ditunjukkan di bawah ini:
PostgreSQL mendukung jenis gabungan di bawah ini:
- Gabung Loop Bersarang
- Hash Gabung
- Gabung Bergabung
Masing-masing metode Gabung ini sama-sama berguna tergantung pada kueri dan parameter lainnya mis. kueri, data tabel, klausa gabungan, selektivitas, memori, dll. Metode gabungan ini diimplementasikan oleh sebagian besar database relasional.
Mari buat beberapa tabel pra-penyiapan dan isi dengan beberapa data, yang akan sering digunakan untuk menjelaskan metode pemindaian ini dengan lebih baik.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEDalam semua contoh berikutnya, kami mempertimbangkan parameter konfigurasi default kecuali ditentukan lain secara khusus.
Gabung Loop Bersarang
Nested Loop Join (NLJ) adalah algoritma join paling sederhana dimana setiap record relasi luar dicocokkan dengan setiap record relasi dalam. Gabungan antara relasi A dan B dengan kondisi A.ID Nested Loop Join (NLJ) adalah metode penggabungan yang paling umum dan dapat digunakan hampir di semua kumpulan data dengan jenis klausa gabungan apa pun. Karena algoritme ini memindai semua tupel dari relasi dalam dan luar, ini dianggap sebagai operasi join yang paling mahal. Sesuai tabel dan data di atas, query berikut akan menghasilkan Nested Loop Join seperti yang ditunjukkan di bawah ini: Karena klausa join adalah “<”, satu-satunya metode join yang mungkin di sini adalah Nested Loop Join. Perhatikan di sini satu jenis simpul baru sebagai Materialize; node ini bertindak sebagai cache hasil perantara yaitu alih-alih mengambil semua tupel dari suatu relasi beberapa kali, hasil yang diambil pertama kali disimpan dalam memori dan pada permintaan berikutnya untuk mendapatkan Tuple akan dilayani dari memori alih-alih mengambil dari halaman relasi lagi . Dalam kasus jika semua tupel tidak dapat ditampung dalam memori maka tupel spill-over pergi ke file sementara. Ini sebagian besar berguna dalam kasus Gabung Loop Bersarang dan sampai batas tertentu dalam kasus Gabung Gabung karena mereka mengandalkan pemindaian ulang hubungan batin. Materialize Node tidak hanya terbatas pada caching hasil relasi tetapi juga dapat men-cache hasil dari node manapun di bawah dalam plan tree. TIPS:Jika klausa join adalah “=” dan nested loop join dipilih di antara sebuah relasi, maka sangat penting untuk menyelidiki apakah metode join yang lebih efisien seperti hash atau merge join dapat dipilih oleh menyetel konfigurasi (mis. work_mem tetapi tidak terbatas pada ) atau dengan menambahkan indeks, dll. Beberapa kueri mungkin tidak memiliki klausa join, dalam hal ini juga satu-satunya pilihan untuk bergabung adalah Nested Loop Join. Misalnya. pertimbangkan kueri di bawah ini sesuai dengan data pra-penyiapan: Gabungan pada contoh di atas hanyalah produk Cartesian dari kedua tabel. Algoritme ini bekerja dalam dua fase: Gabungan antara relasi A dan B dengan kondisi A.ID =B.ID dapat direpresentasikan sebagai berikut: Sesuai tabel dan data pra-penyiapan di atas, kueri berikut akan menghasilkan Hash Join seperti yang ditunjukkan di bawah ini: Di sini tabel hash dibuat di atas tabel blogtable2 karena tabelnya lebih kecil sehingga memori minimal yang diperlukan untuk tabel hash dan seluruh tabel hash bisa muat di memori. Merge Join adalah algoritma dimana setiap record relasi luar dicocokkan dengan setiap record relasi dalam sampai ada kemungkinan pencocokan klausa join. Algoritma join ini hanya digunakan jika kedua relasi diurutkan dan operator klausa join adalah “=”. Gabungan antara relasi A dan B dengan kondisi A.ID =B.ID dapat direpresentasikan sebagai berikut: Contoh kueri yang menghasilkan Hash Join, seperti yang ditunjukkan di atas, dapat menghasilkan Merge Join jika indeks dibuat di kedua tabel. Ini karena data tabel dapat diambil dalam urutan yang diurutkan karena indeks, yang merupakan salah satu kriteria utama untuk metode Merge Join: Jadi, seperti yang kita lihat, kedua tabel menggunakan pemindaian indeks alih-alih pemindaian berurutan karena kedua tabel akan memancarkan catatan yang diurutkan. PostgreSQL mendukung berbagai konfigurasi terkait perencana, yang dapat digunakan untuk mengisyaratkan pengoptimal kueri agar tidak memilih beberapa jenis metode gabungan tertentu. Jika metode penggabungan yang dipilih oleh pengoptimal tidak optimal, maka parameter konfigurasi ini dapat dimatikan untuk memaksa pengoptimal kueri memilih jenis metode gabungan yang berbeda. Semua parameter konfigurasi ini "aktif" secara default. Di bawah ini adalah parameter konfigurasi perencana khusus untuk menggabungkan metode. Ada banyak parameter konfigurasi terkait rencana yang digunakan untuk berbagai tujuan. Di blog ini, tetap dibatasi hanya untuk metode bergabung. Parameter ini dapat dimodifikasi dari sesi tertentu. Jadi jika kita ingin bereksperimen dengan rencana dari sesi tertentu, maka parameter konfigurasi ini dapat dimanipulasi dan sesi lain akan tetap berfungsi sebagaimana adanya. Sekarang, perhatikan contoh gabungan gabungan dan gabungan hash di atas. Tanpa indeks, pengoptimal kueri memilih Hash Join untuk kueri di bawah ini seperti yang ditunjukkan di bawah ini, tetapi setelah menggunakan konfigurasi, pengoptimal kueri beralih untuk menggabungkan gabungan bahkan tanpa indeks: Awalnya Hash Join dipilih karena data dari tabel tidak diurutkan. Untuk memilih Merge Join Plan, pertama-tama perlu mengurutkan semua record yang diambil dari kedua tabel dan kemudian menerapkan merge join. Jadi, biaya penyortiran akan menjadi tambahan dan karenanya biaya keseluruhan akan meningkat. Jadi kemungkinan dalam hal ini total biaya (termasuk kenaikan) lebih besar dari total biaya Hash Join, maka dipilih Hash Join. Setelah parameter konfigurasi enable_hashjoin diubah menjadi “off”, ini berarti pengoptimal kueri secara langsung menetapkan biaya untuk hash join sebagai biaya penonaktifan (=1.0e10 yaitu 100000000000.00). Biaya setiap kemungkinan bergabung akan lebih rendah dari ini. Jadi, hasil kueri yang sama di Merge Join setelah enable_hashjoin diubah menjadi “off” karena bahkan termasuk biaya penyortiran, total biaya gabung gabung lebih rendah daripada biaya nonaktifkan. Sekarang perhatikan contoh di bawah ini: Seperti yang dapat kita lihat di atas, meskipun parameter konfigurasi terkait bergabung dengan loop bersarang diubah menjadi "mati" tetap saja ia memilih Gabung Loop Bersarang karena tidak ada kemungkinan alternatif dari Metode Gabung jenis lain untuk mendapatkan terpilih. Dalam istilah yang lebih sederhana, karena Nested Loop Join adalah satu-satunya kemungkinan bergabung, maka berapa pun biayanya akan selalu menjadi pemenang (Sama seperti saya dulu pemenang lomba 100m jika saya berlari sendiri…:-)). Perhatikan juga perbedaan biaya pada paket pertama dan kedua. Paket pertama menunjukkan biaya sebenarnya dari Nested Loop Join tetapi yang kedua menunjukkan biaya penonaktifan yang sama. Semua jenis metode bergabung PostgreSQL berguna dan dipilih berdasarkan sifat kueri, data, klausa gabungan, dll. Jika kueri tidak berfungsi seperti yang diharapkan, yaitu metode bergabung tidak dipilih seperti yang diharapkan, pengguna dapat bermain-main dengan parameter konfigurasi paket berbeda yang tersedia dan melihat apakah ada sesuatu yang hilang.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)Hash Gabung
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Gabung Gabung
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)Konfigurasi
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)Kesimpulan