Tidak ada sistem, perangkat keras, atau topologi yang sempurna untuk menghindari semua kemungkinan masalah yang dapat terjadi di lingkungan produksi. Mengatasi tantangan ini memerlukan DRP (Disaster Recovery Plan) yang efektif, yang dikonfigurasi sesuai dengan kebutuhan aplikasi, infrastruktur, dan bisnis Anda. Kunci keberhasilan dalam situasi seperti ini selalu seberapa cepat kita dapat memperbaiki atau memulihkan dari masalah.
Di blog ini kita akan melihat skenario kegagalan PostgreSQL yang paling umum dan menunjukkan kepada Anda bagaimana Anda dapat memecahkan atau mengatasi masalah tersebut. Kami juga akan melihat bagaimana ClusterControl dapat membantu kami kembali online
Topologi PostgreSQL Umum
Untuk memahami skenario kegagalan umum, Anda harus terlebih dahulu memulai dengan topologi PostgreSQL yang umum. Ini dapat berupa aplikasi apa pun yang terhubung ke Node Utama PostgreSQL yang memiliki replika yang terhubung dengannya.
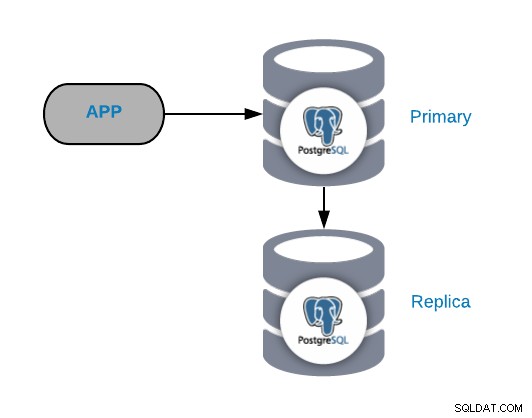
Anda selalu dapat meningkatkan atau memperluas topologi ini dengan menambahkan lebih banyak node atau penyeimbang beban , tapi ini adalah topologi dasar yang akan kita mulai.
Kegagalan Node PostgreSQL Utama
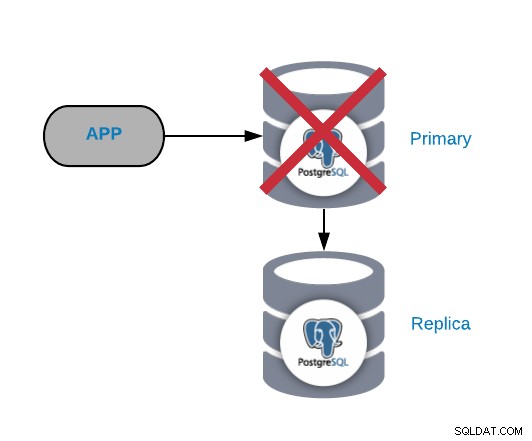
Ini adalah salah satu kegagalan paling kritis karena kami harus memperbaikinya secepatnya jika kami ingin menjaga sistem kami tetap online. Untuk jenis kegagalan ini, penting untuk memiliki semacam mekanisme failover otomatis. Setelah kegagalan, maka Anda dapat melihat alasan untuk masalah tersebut. Setelah proses failover, kami memastikan bahwa node utama yang gagal tidak masih berpikir bahwa itu adalah node utama. Ini untuk menghindari inkonsistensi data saat menulisnya.
Penyebab paling umum dari masalah semacam ini adalah kegagalan sistem operasi, kegagalan perangkat keras, atau kegagalan disk. Bagaimanapun, kita harus memeriksa database dan log sistem operasi untuk menemukan alasannya.
Solusi tercepat untuk masalah ini adalah dengan melakukan tugas failover untuk mengurangi waktu henti. Untuk mempromosikan replika kita dapat menggunakan perintah pg_ctl promote pada node database budak, dan kemudian, kita harus mengirimkan lalu lintas dari aplikasi ke node utama baru. Untuk tugas terakhir ini, kita dapat menerapkan penyeimbang beban antara aplikasi kita dan node database, untuk menghindari perubahan dari sisi aplikasi jika terjadi kegagalan. Kami juga dapat mengonfigurasi penyeimbang beban untuk mendeteksi kegagalan simpul dan alih-alih mengirimkan lalu lintas kepadanya, mengirim lalu lintas ke simpul utama yang baru.
Setelah proses failover dan memastikan sistem bekerja kembali, kita dapat melihat masalahnya, dan kami menyarankan untuk selalu menjaga setidaknya satu node slave bekerja, jadi jika terjadi kegagalan primer baru, kita dapat melakukan tugas failover lagi.
Kegagalan Node Replika PostgreSQL
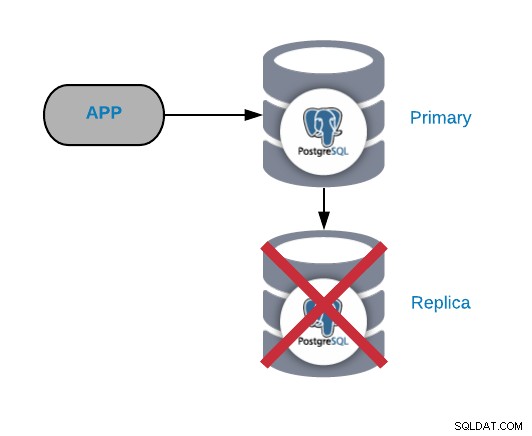
Ini biasanya bukan masalah kritis (selama Anda memiliki lebih dari satu replika dan tidak menggunakannya untuk mengirim lalu lintas produksi baca). Jika Anda mengalami masalah pada node utama, dan tidak memperbarui replika Anda, Anda akan menghadapi masalah kritis yang nyata. Jika Anda menggunakan replika kami untuk tujuan pelaporan atau data besar, Anda mungkin ingin memperbaikinya dengan cepat.
Penyebab paling umum dari masalah semacam ini sama dengan yang kita lihat untuk node utama, kegagalan sistem operasi, kegagalan perangkat keras, atau kegagalan disk. Anda harus memeriksa database dan log sistem operasi untuk menemukan alasannya.
Tidak disarankan untuk menjaga sistem tetap bekerja tanpa replika apa pun karena, jika terjadi kegagalan, Anda tidak memiliki cara cepat untuk kembali online. Jika Anda hanya memiliki satu budak, Anda harus menyelesaikan masalah ini secepatnya; cara tercepat adalah dengan membuat replika baru dari awal. Untuk ini, Anda harus mengambil cadangan yang konsisten dan memulihkannya ke node slave, lalu mengonfigurasi replikasi antara node slave ini dan node utama.
Jika Anda ingin mengetahui alasan kegagalan, Anda harus menggunakan server lain untuk membuat replika baru, lalu mencari yang lama untuk menemukannya. Setelah menyelesaikan tugas ini, Anda juga dapat mengonfigurasi ulang replika lama dan menjaga keduanya tetap berfungsi sebagai opsi failover di masa mendatang.
Jika Anda menggunakan replika untuk pelaporan atau untuk tujuan data besar, Anda harus mengubah alamat IP untuk menyambung ke yang baru. Seperti pada kasus sebelumnya, salah satu cara untuk menghindari perubahan ini adalah dengan menggunakan load balancer yang akan mengetahui status setiap server, sehingga Anda dapat menambah/menghapus replika sesuai keinginan.
Kegagalan Replikasi PostgreSQL
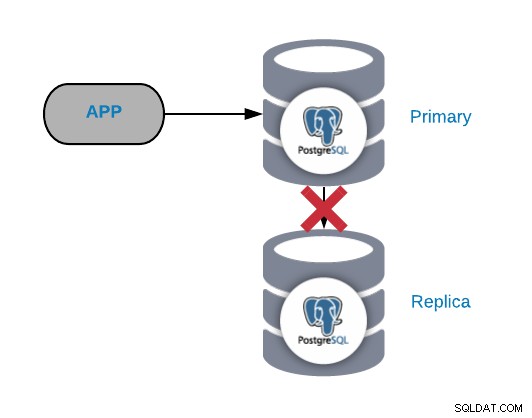
Secara umum, masalah semacam ini muncul karena jaringan atau konfigurasi isu. Ini terkait dengan hilangnya WAL (Write-Ahead Logging) di node utama dan cara PostgreSQL mengelola replikasi.
Jika Anda memiliki lalu lintas penting, Anda melakukan pos pemeriksaan terlalu sering, atau Anda menyimpan WALS hanya beberapa menit; jika Anda memiliki masalah jaringan, Anda akan memiliki sedikit waktu untuk menyelesaikannya. WAL Anda akan dihapus sebelum Anda dapat mengirim dan menerapkannya ke replika.
Jika WAL yang diperlukan replika untuk terus bekerja telah dihapus, Anda perlu membangunnya kembali, jadi untuk menghindari tugas ini, kita harus memeriksa konfigurasi database untuk meningkatkan wal_keep_segments (jumlah WALS yang harus disimpan di pg_xlog direktori) atau parameter max_wal_senders (jumlah maksimum proses pengirim WAL yang berjalan secara bersamaan).
Opsi lain yang disarankan adalah mengonfigurasi archive_mode aktif dan mengirim file WAL ke jalur lain dengan parameter archive_command. Dengan cara ini, jika PostgreSQL mencapai batas dan menghapus file WAL, kami akan tetap menyimpannya di jalur lain.
Korupsi Data PostgreSQL / Inkonsistensi Data / Penghapusan Tidak Disengaja

Ini adalah mimpi buruk bagi DBA mana pun dan mungkin masalah paling kompleks yang akan dihadapi diperbaiki, tergantung pada seberapa luas masalah tersebut.
Bila data Anda terpengaruh oleh beberapa masalah ini, cara paling umum untuk memperbaikinya (dan mungkin satu-satunya) adalah dengan memulihkan cadangan. Itulah sebabnya pencadangan adalah bentuk dasar dari rencana pemulihan bencana dan disarankan agar Anda memiliki setidaknya tiga cadangan yang disimpan di tempat fisik yang berbeda. Praktik terbaik menentukan file cadangan harus memiliki satu disimpan secara lokal di server database (untuk pemulihan yang lebih cepat), yang lain di server cadangan terpusat, dan yang terakhir di cloud.
Kami juga dapat membuat campuran cadangan penuh/tambahan/diferensial yang kompatibel dengan PITR untuk mengurangi Sasaran Titik Pemulihan kami.
Mengelola Kegagalan PostgreSQL dengan ClusterControl
Sekarang kita telah melihat skenario umum kegagalan PostgreSQL ini, mari kita lihat apa yang akan terjadi jika kita mengelola database PostgreSQL Anda dari sistem manajemen database terpusat. Salah satu yang hebat dalam mencapai cara cepat dan mudah untuk memperbaiki masalah, ASAP, jika terjadi kegagalan.
ClusterControl menyediakan otomatisasi untuk sebagian besar tugas PostgreSQL yang dijelaskan di atas; semua dalam cara yang terpusat dan mudah digunakan. Dengan sistem ini Anda akan dapat dengan mudah mengkonfigurasi hal-hal yang, secara manual, akan memakan waktu dan usaha. Kami sekarang akan meninjau beberapa fitur utamanya yang terkait dengan skenario kegagalan PostgreSQL.
Menyebarkan / Mengimpor Cluster PostgreSQL
Setelah kita memasuki antarmuka ClusterControl, hal pertama yang harus dilakukan adalah menerapkan cluster baru atau mengimpor cluster yang sudah ada. Untuk melakukan penerapan, cukup pilih opsi Deploy Database Cluster dan ikuti petunjuk yang muncul.
Menskalakan Cluster PostgreSQL Anda
Jika Anda membuka Cluster Actions dan memilih Add Replication Slave, Anda dapat membuat replika baru dari awal atau menambahkan database PostgreSQL yang ada sebagai replika. Dengan cara ini, Anda dapat menjalankan replika baru Anda dalam beberapa menit dan kami dapat menambahkan replika sebanyak yang kami inginkan; menyebarkan lalu lintas baca di antara mereka menggunakan penyeimbang beban (yang juga dapat kita terapkan dengan ClusterControl).
Kegagalan Otomatis PostgreSQL
ClusterControl mengelola failover pada penyiapan replikasi Anda. Ini mendeteksi kegagalan master dan mempromosikan budak dengan data terbaru sebagai master baru. Itu juga secara otomatis gagal-atas sisa budak untuk mereplikasi dari master baru. Untuk koneksi klien, ini memanfaatkan dua alat untuk tugas:HAProxy dan Keepalive.
HAProxy adalah penyeimbang beban yang mendistribusikan lalu lintas dari satu asal ke satu atau beberapa tujuan dan dapat menentukan aturan dan/atau protokol khusus untuk tugas tersebut. Jika salah satu tujuan berhenti merespons, itu ditandai sebagai offline, dan lalu lintas dikirim ke salah satu tujuan yang tersedia. Ini mencegah lalu lintas dikirim ke tujuan yang tidak dapat diakses dan hilangnya informasi ini dengan mengarahkannya ke tujuan yang valid.
Keepalived memungkinkan Anda mengonfigurasi IP virtual dalam grup server aktif/pasif. IP virtual ini ditetapkan ke server "Utama" yang aktif. Jika server ini gagal, IP secara otomatis dimigrasikan ke server “Sekunder” yang ternyata pasif, memungkinkannya untuk terus bekerja dengan IP yang sama secara transparan untuk sistem kami.
Menambahkan Penyeimbang Beban PostgreSQL
Jika Anda membuka Cluster Actions dan memilih Add Load Balancer (atau dari tampilan cluster - buka Manage -> Load Balancer), Anda dapat menambahkan load balancer ke topologi database kami.
Konfigurasi yang diperlukan untuk membuat penyeimbang beban baru Anda cukup sederhana. Anda hanya perlu menambahkan IP/Hostname, port, policy, dan node yang akan kita gunakan. Anda dapat menambahkan dua penyeimbang beban dengan Keepalive di antaranya, yang memungkinkan kami untuk memiliki failover otomatis penyeimbang beban kami jika terjadi kegagalan. Keepalive menggunakan alamat IP virtual, dan memigrasikannya dari satu penyeimbang beban ke penyeimbang beban lainnya jika terjadi kegagalan, sehingga penyiapan kami dapat terus berfungsi secara normal.
Cadangan PostgreSQL
Kita telah membahas pentingnya memiliki cadangan. ClusterControl menyediakan fungsionalitas baik untuk membuat cadangan langsung atau menjadwalkannya.
Anda dapat memilih di antara tiga metode pencadangan yang berbeda, pgdump, pg_basebackup, atau pgBackRest. Anda juga dapat menentukan tempat untuk menyimpan cadangan (di server database, di server ClusterControl, atau di cloud), tingkat kompresi, enkripsi yang diperlukan, dan periode penyimpanan.
Pemantauan &Peringatan PostgreSQL
Sebelum dapat mengambil tindakan, Anda perlu mengetahui apa yang terjadi, jadi Anda perlu memantau cluster database Anda. ClusterControl memungkinkan Anda untuk memantau server kami secara real-time. Ada grafik dengan data dasar seperti CPU, Jaringan, Disk, RAM, IOPS, serta metrik khusus basis data yang dikumpulkan dari instans PostgreSQL. Kueri basis data juga dapat dilihat dari Monitor Kueri.
Dengan cara yang sama seperti Anda mengaktifkan pemantauan dari ClusterControl, Anda juga dapat menyiapkan peringatan yang memberi tahu Anda tentang peristiwa di cluster Anda. Lansiran ini dapat dikonfigurasi, dan dapat dipersonalisasi sesuai kebutuhan.
Kesimpulan
Setiap orang pada akhirnya harus mengatasi masalah dan kegagalan PostgreSQL. Dan karena Anda tidak dapat menghindari masalah ini, Anda harus dapat memperbaikinya secepatnya dan menjaga sistem tetap berjalan. Kami juga melihat bagaimana menggunakan ClusterControl dapat membantu dengan masalah ini; semua dari satu platform yang mudah digunakan.
Inilah yang kami pikir sebagai beberapa skenario kegagalan paling umum untuk PostgreSQL. Kami akan senang mendengar tentang pengalaman Anda sendiri dan bagaimana Anda memperbaikinya.