Ringkasan singkat
- Kinerja metode subquery bergantung pada distribusi data.
- Kinerja agregasi bersyarat tidak bergantung pada distribusi data.
Metode subqueries bisa lebih cepat atau lebih lambat dari agregasi bersyarat, itu tergantung pada distribusi data.
Secara alami, jika tabel memiliki indeks yang sesuai, maka subquery kemungkinan akan mendapat manfaat darinya, karena indeks akan memungkinkan untuk memindai hanya bagian yang relevan dari tabel, bukan pemindaian penuh. Memiliki indeks yang sesuai tidak mungkin secara signifikan menguntungkan metode agregasi Bersyarat, karena tetap akan memindai indeks penuh. Satu-satunya keuntungan adalah jika indeks lebih sempit dari tabel dan mesin harus membaca lebih sedikit halaman ke dalam memori.
Mengetahui hal ini, Anda dapat memutuskan metode mana yang akan dipilih.
Tes pertama
Saya membuat tabel pengujian yang lebih besar, dengan 5 juta baris. Tidak ada indeks di atas meja. Saya mengukur statistik IO dan CPU menggunakan SQL Sentry Plan Explorer. Saya menggunakan SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64-bit untuk pengujian ini.
Memang, kueri asli Anda berperilaku seperti yang Anda jelaskan, yaitu subkueri lebih cepat meskipun pembacaannya 3 kali lebih tinggi.
Setelah beberapa percobaan pada tabel tanpa indeks, saya menulis ulang agregat bersyarat Anda dan menambahkan variabel untuk menyimpan nilai DATEADD ekspresi.
Secara keseluruhan waktu menjadi jauh lebih cepat.
Kemudian saya mengganti SUM dengan COUNT dan menjadi sedikit lebih cepat lagi.
Bagaimanapun, agregasi bersyarat menjadi secepat subquery.
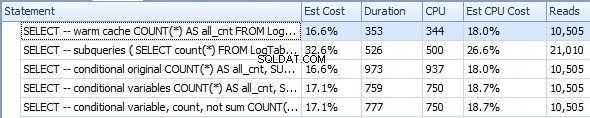
Hangatkan cache (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Subkueri (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Agregasi bersyarat asli (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregasi bersyarat dengan variabel (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregasi bersyarat dengan variabel dan COUNT, bukan SUM (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Berdasarkan hasil ini, tebakan saya adalah CASE dipanggil DATEADD untuk setiap baris, sedangkan WHERE cukup pintar untuk menghitungnya sekali. Ditambah COUNT sedikit lebih efisien daripada SUM .
Pada akhirnya, agregasi bersyarat hanya sedikit lebih lambat dari subquery (1062 vs 1031), mungkin karena WHERE sedikit lebih efisien daripada CASE itu sendiri, dan selain itu, WHERE menyaring beberapa baris, jadi COUNT harus memproses lebih sedikit baris.
Dalam praktiknya saya akan menggunakan agregasi bersyarat, karena menurut saya jumlah bacaan lebih penting. Jika tabel Anda kecil agar muat dan tetap berada di kumpulan buffer, maka kueri apa pun akan cepat untuk pengguna akhir. Namun, jika tabel lebih besar dari memori yang tersedia, maka saya berharap membaca dari disk akan memperlambat subkueri secara signifikan.
Ujian kedua
Di sisi lain, memfilter baris sedini mungkin juga penting.
Berikut adalah sedikit variasi dari tes, yang menunjukkannya. Di sini saya menetapkan ambang batas menjadi GETDATE() + 100 tahun, untuk memastikan tidak ada baris yang memenuhi kriteria filter.
Hangatkan cache (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Subkueri (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Agregasi bersyarat asli (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregasi bersyarat dengan variabel (CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregasi bersyarat dengan variabel dan COUNT, bukan SUM (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Di bawah ini adalah rencana dengan subquery. Anda dapat melihat bahwa 0 baris masuk ke Agregat Aliran di subkueri kedua, semuanya disaring pada langkah Pemindaian Tabel.
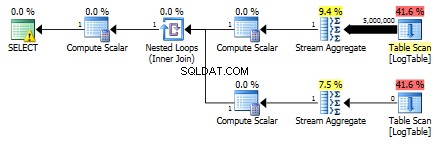
Hasilnya, subquery kembali lebih cepat.
Tes ketiga
Di sini saya mengubah kriteria penyaringan dari tes sebelumnya:semua > diganti dengan < . Akibatnya, COUNT bersyarat menghitung semua baris, bukan tidak ada. Kejutan kejutan! Kueri agregasi bersyarat membutuhkan waktu 750 mdtk yang sama, sedangkan subkueri menjadi 813, bukan 500.

Berikut adalah rencana untuk subquery:
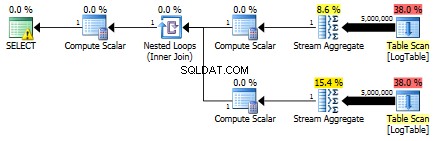
Bisakah Anda memberi saya sebuah contoh, di mana agregasi bersyarat terutama mengungguli solusi subquery?
Ini dia. Kinerja metode subqueries tergantung pada distribusi data. Performa agregasi bersyarat tidak bergantung pada distribusi data.
Metode subqueries bisa lebih cepat atau lebih lambat dari agregasi bersyarat, itu tergantung pada distribusi data.
Mengetahui hal ini, Anda dapat memutuskan metode mana yang akan dipilih.
Detail bonus
Jika Anda mengarahkan mouse ke Table Scan operator Anda dapat melihat Actual Data Size dalam berbagai varian.
- Sederhana
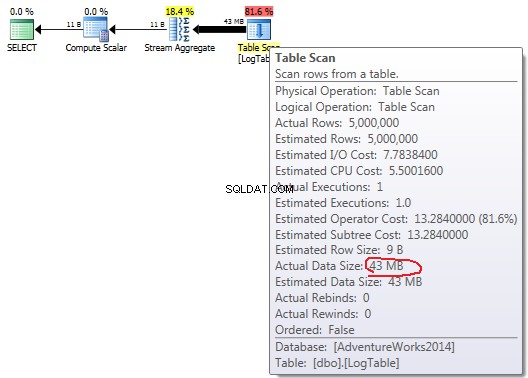
COUNT(*):
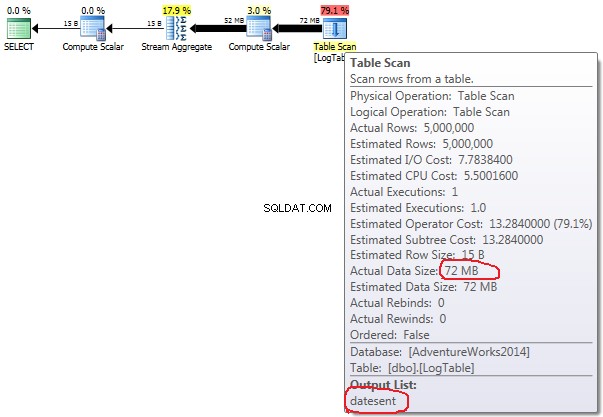
- Agregasi bersyarat:
- Subquery dalam pengujian 2:
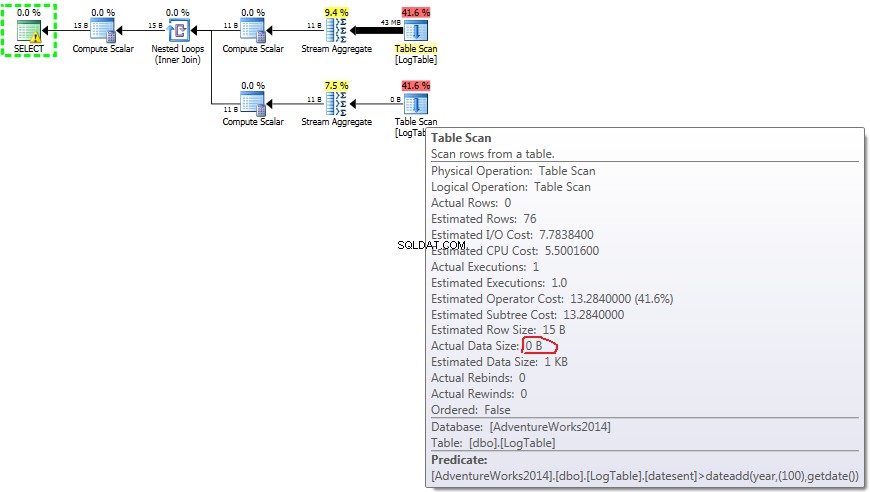
- Subquery dalam pengujian 3:
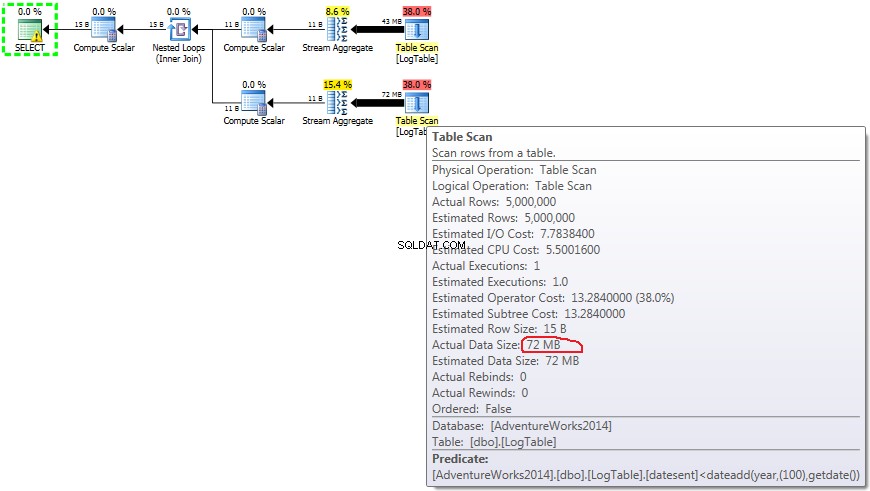
Sekarang menjadi jelas bahwa perbedaan kinerja kemungkinan disebabkan oleh perbedaan jumlah data yang mengalir melalui rencana.
Dalam kasus COUNT(*) simple sederhana tidak ada Output list (tidak diperlukan nilai kolom) dan ukuran data terkecil (43MB).
Dalam hal agregasi bersyarat, jumlah ini tidak berubah antara pengujian 2 dan 3, selalu 72MB. Output list memiliki satu kolom datesent .
Dalam hal subkueri, jumlah ini tidak berubah tergantung pada distribusi data.