Di bagian ke-3 dari Solusi Cloud PostgreSQL Terkelola Benchmarking , saya memanfaatkan penawaran tingkat gratis GCP Google. Ini merupakan pengalaman yang berharga dan sebagai sysadmin menghabiskan sebagian besar waktunya di konsol, saya tidak dapat melewatkan kesempatan untuk mencoba cloud shell, salah satu fitur konsol yang membedakan Google dari penyedia cloud yang lebih saya kenal , Layanan Web Amazon.
Untuk rekap cepat, di Bagian 1 saya melihat alat tolok ukur yang tersedia dan menjelaskan mengapa saya memilih Prosedur Tolok Ukur AWS untuk Aurora. Saya juga membandingkan Amazon Aurora untuk PostgreSQL versi 10.6. Di Bagian 2 saya meninjau AWS RDS untuk PostgreSQL versi 11.1.
Selama putaran ini, pengujian berdasarkan Prosedur Tolok Ukur AWS untuk Aurora akan dijalankan terhadap Google Cloud SQL untuk PostgreSQL 9.6 karena versi 11.1 masih dalam versi beta.
Instance Cloud
Prasyarat
Seperti yang disebutkan dalam dua artikel sebelumnya, saya memilih untuk meninggalkan pengaturan PostgreSQL di default cloud GUC mereka, kecuali jika mereka mencegah pengujian berjalan (lihat lebih lanjut di bawah). Ingat dari artikel sebelumnya bahwa asumsinya adalah bahwa penyedia cloud harus memiliki instance database yang dikonfigurasi untuk memberikan kinerja yang wajar.
Patch waktu pgbench AWS untuk PostgreSQL 9.6.5 diterapkan dengan rapi ke versi Google Cloud dari PostgreSQL 9.6.10.
Dengan menggunakan informasi yang dikeluarkan Google di blog mereka Google Cloud for AWS Professionals, saya mencocokkan spesifikasi untuk klien dan instance target sehubungan dengan komponen Compute, Storage, dan Networking. Misalnya, Google Cloud yang setara dengan AWS Enhanced Networking dicapai dengan mengukur node komputasi berdasarkan rumus:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Dalam hal menyiapkan instans database target, mirip dengan AWS, Google Cloud tidak mengizinkan replika, namun, penyimpanan dienkripsi saat istirahat dan tidak ada opsi untuk menonaktifkannya.
Terakhir, untuk mencapai kinerja jaringan terbaik, klien dan instans target harus ditempatkan di zona ketersediaan yang sama.
Klien
Spesifikasi instans klien yang cocok dengan instans AWS terdekat, adalah:
- vCPU:32 (16 Core x 2 Thread/Core)
- RAM:208 GiB (maksimum untuk instance vCPU 32)
- Penyimpanan:Persistent disk Compute Engine
- Jaringan:16 Gbps (maks [32 vCPU x 2 Gbps/vCPU] dan 16 Gbps)
Detail instance setelah inisialisasi:
 Contoh klien:Komputasi dan Jaringan
Contoh klien:Komputasi dan Jaringan Catatan:Instans secara default dibatasi hingga 24 vCPU. Dukungan Teknis Google harus menyetujui peningkatan kuota menjadi 32 vCPU per instance.

Meskipun permintaan seperti itu biasanya ditangani dalam 2 hari kerja, saya harus mengacungkan jempol kepada Layanan Dukungan Google untuk menyelesaikan permintaan saya hanya dalam 2 jam.
Bagi yang penasaran, rumus kecepatan jaringan didasarkan pada dokumentasi mesin komputasi yang dirujuk di blog GCP ini.
Kluster DB
Di bawah ini adalah spesifikasi instance database:
- vCPU:8
- RAM:52 GiB (maksimum)
- Penyimpanan:144 MB/dtk, 9.000 IOPS
- Jaringan:2.000 MB/dtk
Perhatikan bahwa memori maksimum yang tersedia untuk instans 8 vCPU adalah 52 GiB. Lebih banyak memori dapat dialokasikan dengan memilih instance yang lebih besar (lebih banyak vCPU):
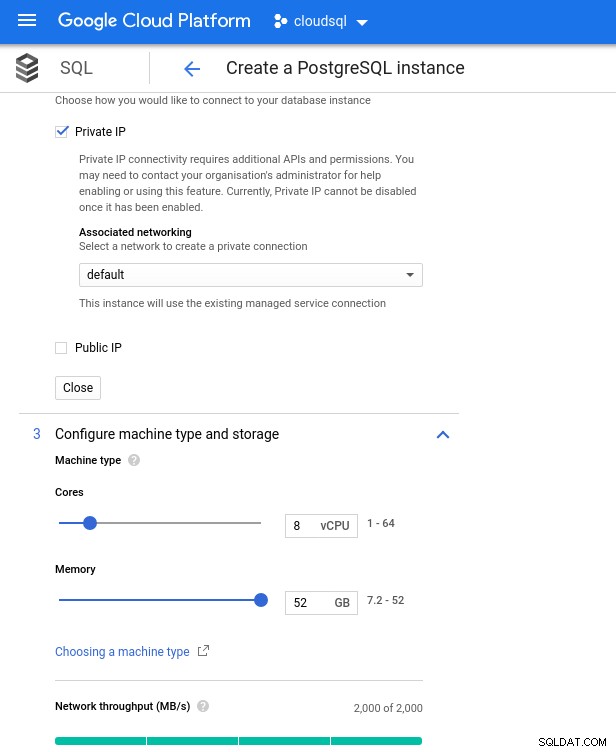 Pengukuran CPU dan Memori Basis Data
Pengukuran CPU dan Memori Basis Data Sementara Google SQL dapat secara otomatis memperluas penyimpanan yang mendasarinya, yang merupakan fitur yang sangat keren, saya memilih untuk menonaktifkan opsi agar konsisten dengan rangkaian fitur AWS, dan menghindari potensi dampak I/O selama operasi pengubahan ukuran. (“potensial”, karena seharusnya tidak berdampak negatif sama sekali, namun menurut pengalaman saya, mengubah ukuran semua jenis penyimpanan yang mendasarinya meningkatkan I/O, meskipun selama beberapa detik).
Ingatlah bahwa instans database AWS dicadangkan oleh penyimpanan EBS yang dioptimalkan yang menyediakan maksimum:
- Bandwidth 1.700 Mbps
- Troughput 212,5 MB/dtk
- 12.000 IOPS
Dengan Google Cloud, kami mencapai konfigurasi serupa dengan menyesuaikan jumlah vCPU (lihat di atas) dan kapasitas penyimpanan:
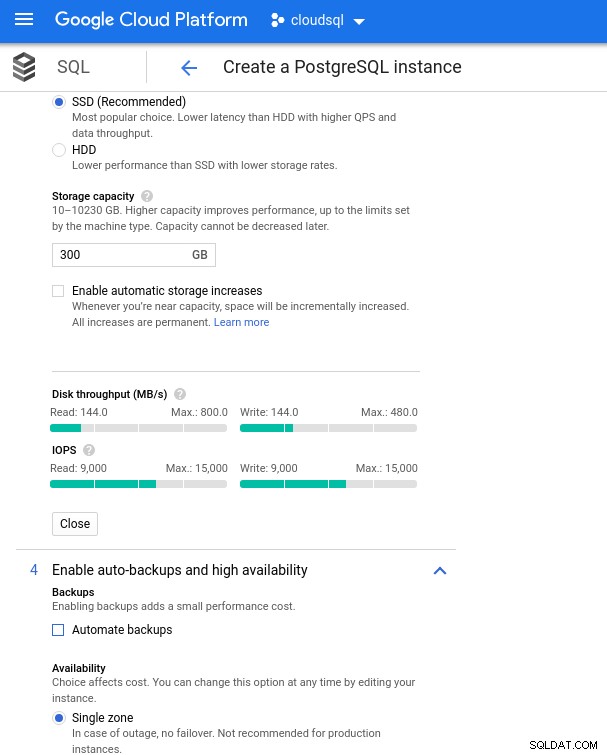 Konfigurasi penyimpanan database dan pengaturan pencadangan
Konfigurasi penyimpanan database dan pengaturan pencadangan Menjalankan Tolok Ukur
Penyiapan
Selanjutnya, instal alat benchmark, pgbench, dan sysbench dengan mengikuti instruksi di panduan Amazon yang disesuaikan dengan PostgreSQL versi 9.6.10.
Inisialisasi variabel lingkungan PostgreSQL di .bashrc dan setel jalur ke biner dan pustaka PostgreSQL:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libDaftar periksa sebelum penerbangan:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)Dan kami siap untuk lepas landas:
pgbench
Inisialisasi database pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…dan beberapa menit kemudian:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Seperti yang biasa kita lakukan, ukuran database harus 160GB. Mari kita verifikasi bahwa:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)Setelah semua persiapan selesai, mulailah tes baca/tulis:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsUps! Berapa maksimumnya?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Jadi, meskipun AWS menetapkan max_connections yang cukup besar karena saya tidak mengalami masalah itu, Google Cloud memerlukan sedikit penyesuaian...Kembali ke cloud console, perbarui parameter database, tunggu beberapa menit, lalu periksa:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Memulai ulang pengujian, semuanya tampak berfungsi dengan baik:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998...tapi ada tangkapan lain. Saya terkejut ketika mencoba membuka sesi psql baru untuk menghitung jumlah koneksi:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsMungkinkah superuser_reserved_connections tidak pada defaultnya?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)Itu defaultnya, lalu apa lagi?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Bingo! Benjolan max_connections lain menanganinya, namun, saya harus memulai ulang tes pgbench. Dan itulah cerita di balik lari duplikat yang tampak pada grafik di bawah ini.
Dan akhirnya, hasilnya ada di:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)sysbench
Isi database:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareKeluaran:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...Dan sekarang jalankan tes:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runDan hasilnya:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Metrik Tolok Ukur
Plugin PostgreSQL untuk Stackdriver tidak digunakan lagi mulai 28 Februari 2019. Meskipun Google merekomendasikan Blue Medora, untuk tujuan artikel ini saya memilih untuk tidak membuat akun dan mengandalkan metrik Stackdriver yang tersedia.
- Penggunaan CPU:
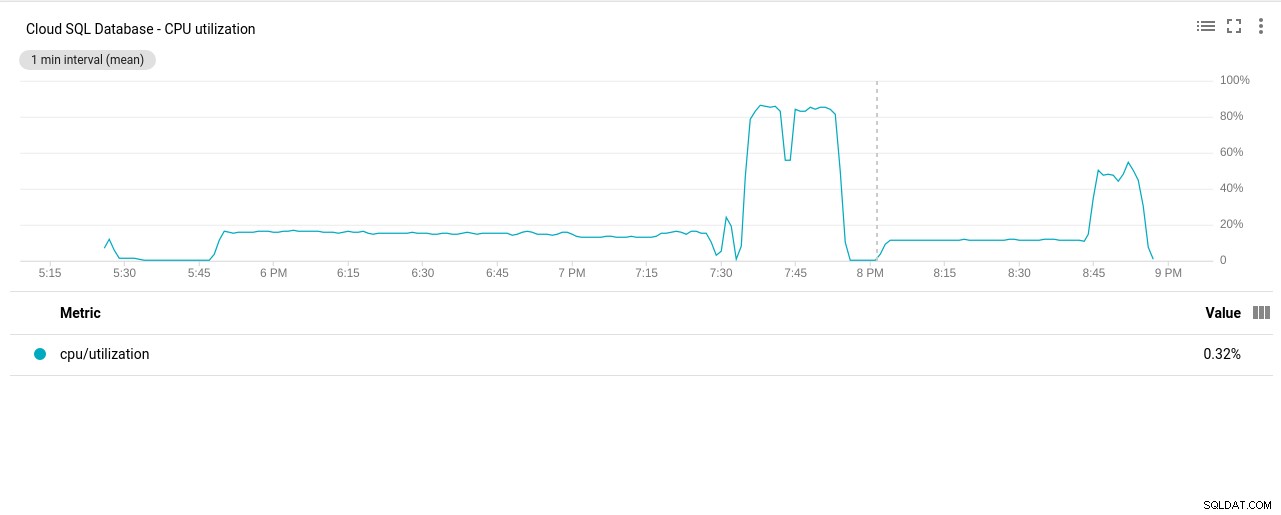 Penulis foto Google Cloud SQL:Pemanfaatan CPU PostgreSQL
Penulis foto Google Cloud SQL:Pemanfaatan CPU PostgreSQL - Operasi Baca/Tulis Disk:
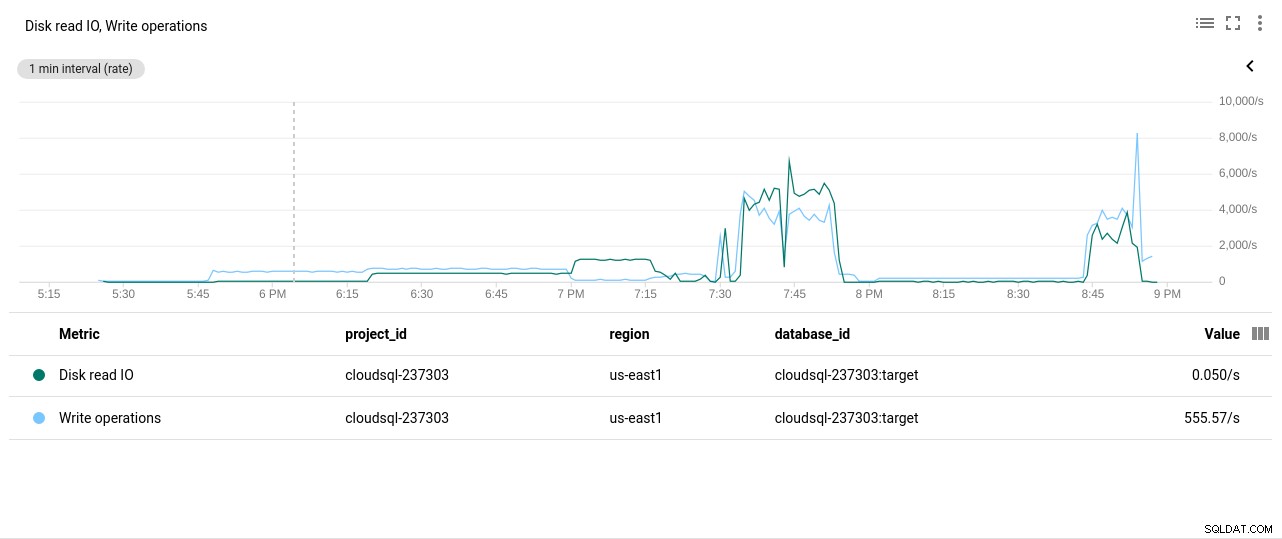 Penulis foto Google Cloud SQL:Operasi Baca/Tulis Disk PostgreSQL
Penulis foto Google Cloud SQL:Operasi Baca/Tulis Disk PostgreSQL - Byte yang Dikirim/Diterima Jaringan:
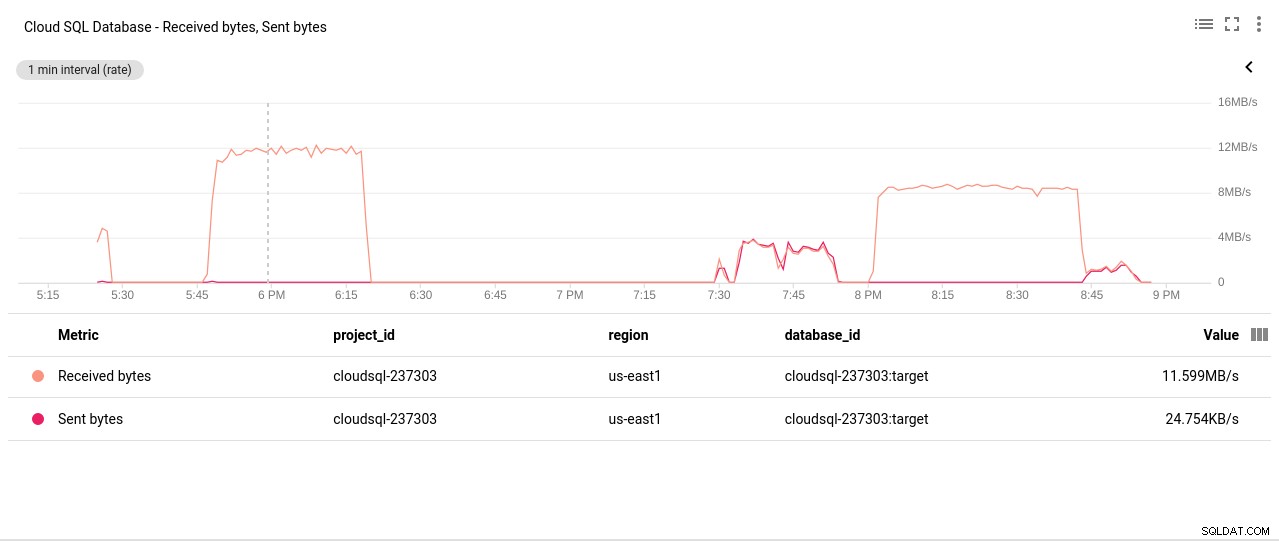 Penulis foto Google Cloud SQL:PostgreSQL Network Sent/Received bytes
Penulis foto Google Cloud SQL:PostgreSQL Network Sent/Received bytes - Jumlah Koneksi PostgreSQL:
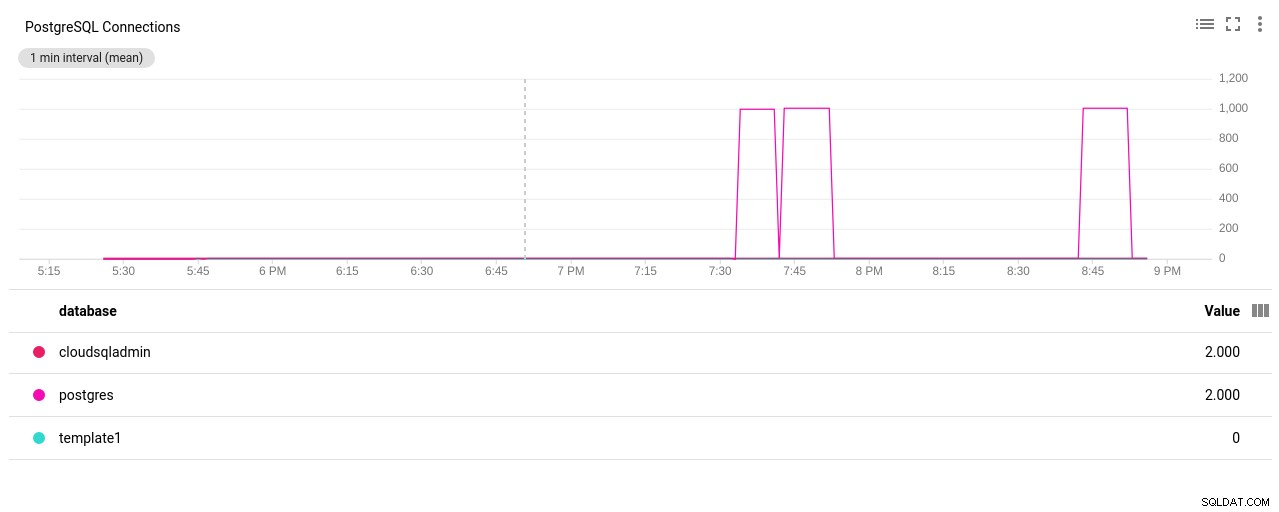 Penulis foto Google Cloud SQL:Jumlah Koneksi PostgreSQL
Penulis foto Google Cloud SQL:Jumlah Koneksi PostgreSQL
Hasil Tolok Ukur
Inisialisasi pgbench
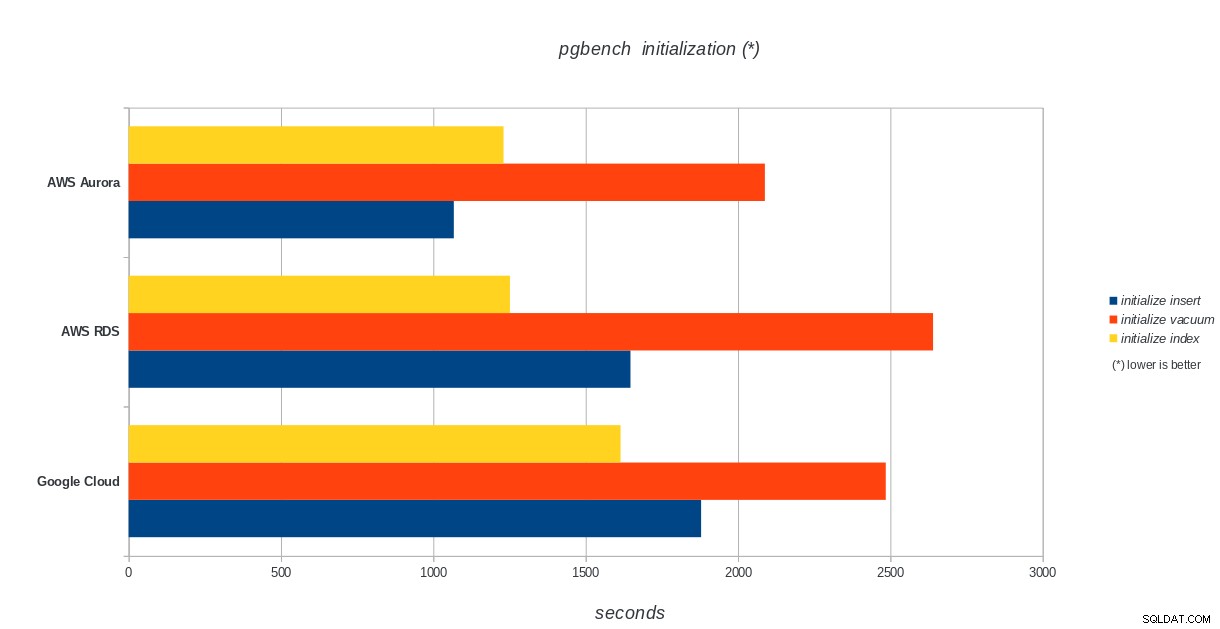 AWS Aurora, AWS RDS, Google Cloud SQL:Hasil inisialisasi pgbench PostgreSQL
AWS Aurora, AWS RDS, Google Cloud SQL:Hasil inisialisasi pgbench PostgreSQL jalankan pgbench
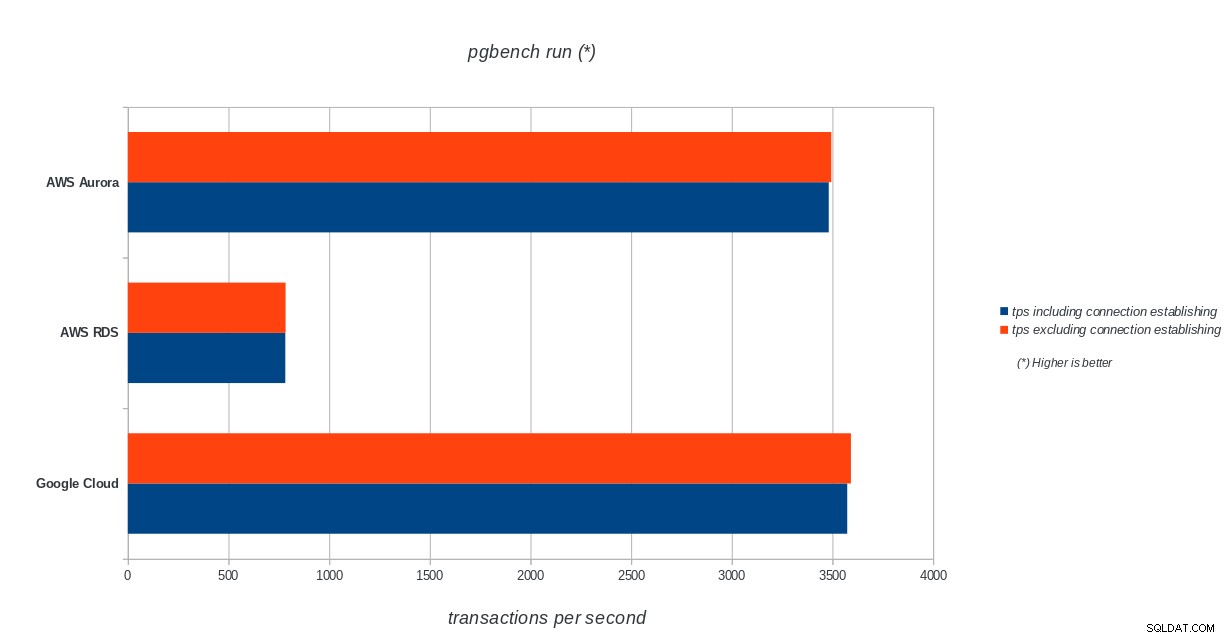 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench menjalankan hasil
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench menjalankan hasil sysbench
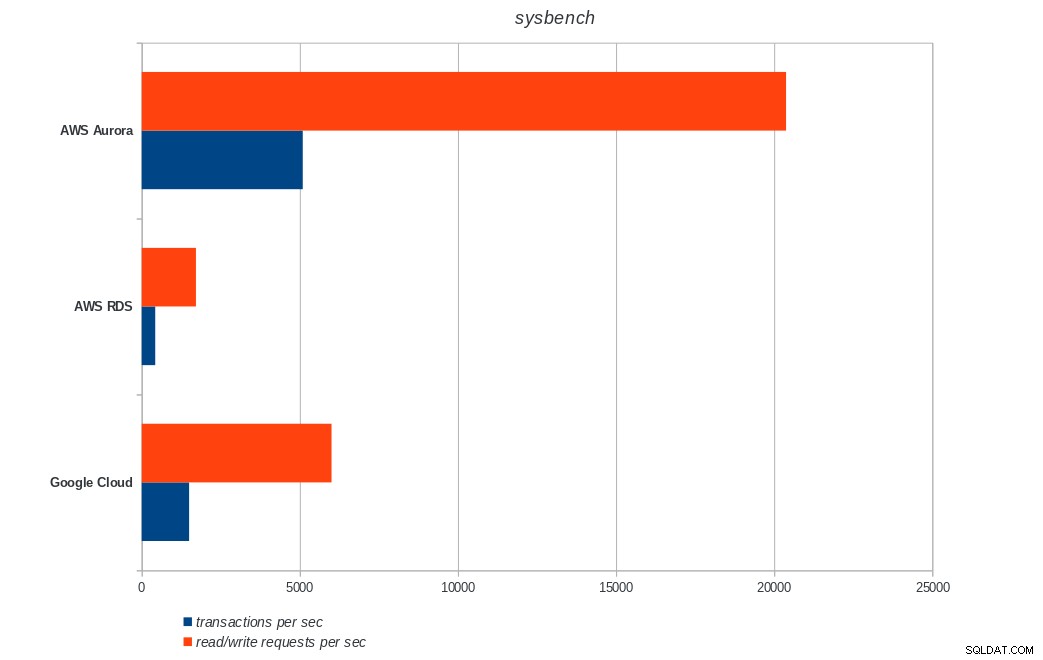 AWS Aurora, AWS RDS, Google Cloud SQL:Hasil sysbench PostgreSQL
AWS Aurora, AWS RDS, Google Cloud SQL:Hasil sysbench PostgreSQL Kesimpulan
Amazon Aurora sejauh ini menjadi yang pertama dalam pengujian berat tulis (sysbench), sementara setara dengan Google Cloud SQL dalam pengujian baca/tulis pgbench. Uji beban (inisialisasi pgbench) menempatkan Google Cloud SQL di tempat pertama, diikuti oleh Amazon RDS. Berdasarkan pandangan sepintas pada model penetapan harga untuk AWS Aurora dan Google Cloud SQL, saya berani mengatakan bahwa Google Cloud adalah pilihan yang lebih baik untuk rata-rata pengguna, sementara AWS Aurora lebih cocok untuk lingkungan kinerja tinggi. Analisis lebih lanjut akan menyusul setelah menyelesaikan semua tolok ukur.
Bagian berikutnya dan terakhir dari seri benchmark ini akan ada di Microsoft Azure PostgreSQL.
Terima kasih telah membaca dan beri komentar di bawah jika Anda memiliki umpan balik.