Mengelola instalasi PostgreSQL melibatkan inspeksi dan kontrol atas berbagai aspek dalam tumpukan perangkat lunak/infrastruktur tempat PostgreSQL berjalan. Ini harus mencakup:
- Penyetelan aplikasi terkait penggunaan/transaksi/koneksi basis data
- Kode basis data (kueri, fungsi)
- Sistem basis data (kinerja, HA, pencadangan)
- Perangkat Keras/Infrastruktur (disk, CPU/Memori)
Inti PostgreSQL menyediakan lapisan basis data tempat kami memercayai data kami untuk disimpan, diproses, dan disajikan. Ini juga menyediakan semua teknologi untuk memiliki sistem yang benar-benar modern, efisien, andal, dan aman. Namun seringkali teknologi ini tidak tersedia sebagai produk kelas bisnis/perusahaan yang disempurnakan dan siap pakai dalam distribusi inti PostgreSQL. Sebaliknya, ada banyak produk/solusi baik oleh komunitas PostgreSQL atau penawaran komersial yang memenuhi kebutuhan tersebut. Solusi tersebut datang baik sebagai penyempurnaan yang ramah pengguna untuk teknologi inti, atau ekstensi dari teknologi inti atau bahkan sebagai integrasi antara komponen PostgreSQL dan komponen lain dari sistem. Di blog kami sebelumnya yang berjudul Sepuluh Tip untuk Memasuki Produksi dengan PostgreSQL, kami melihat beberapa alat yang dapat membantu mengelola instalasi PostgreSQL dalam produksi. Di blog ini kita akan mengeksplorasi secara lebih rinci aspek-aspek yang harus dicakup saat mengelola instalasi PostgreSQL dalam produksi, dan alat yang paling umum digunakan untuk tujuan itu. Kami akan membahas topik-topik berikut:
- Penerapan
- Manajemen
- Penskalaan
- Pemantauan
Penerapan
Di masa lalu, orang-orang biasa mengunduh dan mengkompilasi PostgreSQL dengan tangan, dan kemudian mengonfigurasi parameter runtime dan kontrol akses pengguna. Masih ada beberapa kasus di mana ini mungkin diperlukan, tetapi seiring dengan semakin matangnya sistem dan mulai berkembang, muncul kebutuhan akan cara yang lebih terstandarisasi untuk menerapkan dan mengelola Postgresql. Sebagian besar OS menyediakan paket untuk menginstal, menyebarkan, dan mengelola cluster PostgreSQL. Debian telah menstandarisasi tata letak sistem mereka sendiri yang mendukung banyak versi Postgresql, dan banyak cluster per versi pada saat yang bersamaan. paket debian postgresql-common menyediakan alat yang dibutuhkan. Misalnya untuk membuat cluster baru (disebut i18n_cluster) untuk PostgreSQL versi 10 di Debian, kita dapat melakukannya dengan memberikan perintah berikut:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsKemudian segarkan systemd:
$ sudo systemctl daemon-reloaddan akhirnya mulai dan gunakan cluster baru:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(perhatikan bahwa Debian menangani cluster yang berbeda dengan menggunakan port yang berbeda 5432, 5433 dan seterusnya)
Seiring meningkatnya kebutuhan akan penerapan yang lebih otomatis dan masif, semakin banyak instalasi yang menggunakan alat otomatisasi seperti Ansible, Chef, dan Puppet. Selain otomatisasi dan reproduktifitas penerapan, alat otomatisasi sangat bagus karena merupakan cara yang bagus untuk mendokumentasikan penerapan dan konfigurasi cluster. Di sisi lain, otomatisasi telah berkembang menjadi bidang besar tersendiri, membutuhkan orang yang terampil untuk menulis, mengelola, dan menjalankan skrip otomatis. Info lebih lanjut tentang penyediaan PostgreSQL dapat ditemukan di blog ini:Menjadi DBA PostgreSQL:Penyediaan dan Penerapan.
Manajemen
Mengelola sistem langsung melibatkan tugas-tugas sebagai:menjadwalkan pencadangan dan memantau statusnya, pemulihan bencana, manajemen konfigurasi, manajemen ketersediaan tinggi, dan penanganan failover otomatis. Mencadangkan cluster Postgresql dapat dilakukan dengan berbagai cara. Alat tingkat rendah:
- pg_dump tradisional (cadangan logis)
- pencadangan tingkat sistem file (pencadangan fisik)
- pg_basebackup (cadangan fisik)
Atau tingkat yang lebih tinggi:
- Pelayan Bar
- PgBackRest
Masing-masing cara tersebut mencakup kasus penggunaan dan skenario pemulihan yang berbeda, dan kompleksitasnya bervariasi. Pencadangan PostgreSQL terkait erat dengan gagasan PITR, pengarsipan WAL, dan replikasi. Selama bertahun-tahun prosedur pengambilan, pengujian dan akhirnya (semoga saja!) menggunakan backup dengan PostgreSQL telah berkembang menjadi tugas yang kompleks. Orang dapat menemukan gambaran umum yang bagus tentang solusi pencadangan untuk PostgreSQL di blog ini:Alat Cadangan Teratas untuk PostgreSQL.
Mengenai ketersediaan tinggi dan failover otomatis, minimal yang harus dimiliki penginstalan untuk mengimplementasikannya adalah:
- Dasar yang berfungsi
- Siaga panas yang menerima WAL yang dialirkan dari primer
- Jika primer gagal, metode untuk memberi tahu primer bahwa itu bukan lagi primer (kadang disebut sebagai STONITH)
- Mekanisme detak jantung untuk memeriksa konektivitas antara dua server dan kesehatan server utama
- Metode untuk melakukan failover (misalnya melalui pg_ctl promote, atau file pemicu)
- Prosedur otomatis untuk membuat ulang primer lama sebagai siaga baru:Setelah gangguan atau kegagalan pada primer terdeteksi, maka siaga harus dipromosikan sebagai primer baru. Primer lama tidak lagi valid atau dapat digunakan. Jadi sistem harus memiliki cara untuk menangani keadaan ini antara failover dan pembuatan ulang server utama lama sebagai siaga baru. Status ini disebut status degenerasi, dan PostgreSQL menyediakan alat yang disebut pg_rewind untuk mempercepat proses mengembalikan primer lama ke status dapat disinkronkan dari primer baru.
- Metode untuk melakukan peralihan sesuai permintaan/terencana
Alat yang banyak digunakan untuk menangani semua hal di atas adalah Repmgr. Kami akan menjelaskan pengaturan minimal yang memungkinkan peralihan yang berhasil. Kita mulai dengan PostgreSQL 10.4 utama yang berjalan di FreeBSD 11.1, dibuat dan diinstal secara manual, dan repmgr 4.0 juga dibuat dan diinstal secara manual untuk versi ini (10.4). Kami akan menggunakan dua host bernama fbsd (192.168.1.80) dan fbsdclone (192.168.1.81) dengan versi PostgreSQL dan repmgr yang identik. Pada primer (awalnya fbsd , 192.168.1.80) kami memastikan parameter PostgreSQL berikut disetel:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Kemudian kita buat user repmgr (sebagai superuser) dan database:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgrdan atur kontrol akses berbasis host di pg_hba.conf dengan meletakkan baris berikut di atas:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustKami memastikan bahwa kami mengatur login tanpa kata sandi untuk repmgr pengguna di semua node cluster, dalam kasus kami fbsd dan fbsdclone dengan mengatur otor_keys di .ssh dan kemudian berbagi .ssh. Kemudian kita buat repmrg.conf di primary sebagai:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Kemudian kita daftarkan yang utama:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredDan periksa status cluster:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Kami sekarang bekerja pada standby dengan mengatur repmgr.conf sebagai berikut:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Kami juga memastikan bahwa direktori data yang ditentukan tepat pada baris di atas ada, kosong dan memiliki izin yang benar:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataKami sekarang harus mengkloning ke standby baru kami:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"Dan mulai siaga:
example@sqldat.com:~ % pg_ctl -D data startPada titik ini replikasi seharusnya berfungsi seperti yang diharapkan, verifikasi ini dengan menanyakan pg_stat_replication (fbsd) dan pg_stat_wal_receiver (fbsdclone). Langkah selanjutnya adalah mendaftarkan standby:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerSekarang kita bisa mendapatkan status cluster pada standly atau primary dan memverifikasi bahwa standby terdaftar:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Sekarang misalkan kita ingin melakukan pergantian manual terjadwal secara berurutan, mis. untuk melakukan beberapa pekerjaan administrasi pada node fbsd. Pada node standby, kita jalankan perintah berikut:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyPeralihan telah berhasil dijalankan! Mari kita lihat apa yang ditampilkan cluster show:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Kedua server telah bertukar peran! Repmgr menyediakan daemon repmgrd yang menyediakan pemantauan, failover otomatis, serta notifikasi/peringatan. Menggabungkan repmgrd dengan pgbouncer, memungkinkan untuk mengimplementasikan pembaruan otomatis dari info koneksi database, sehingga menyediakan pagar untuk primer yang gagal (mencegah node yang gagal dari penggunaan apa pun oleh aplikasi) serta menyediakan waktu henti yang minimal untuk aplikasi. Dalam skema yang lebih kompleks, ide lain adalah menggabungkan Keepalive dengan HAProxy di atas pgbouncer dan repmgr, untuk mencapai:
- penyeimbangan beban (penskalaan)
- ketersediaan tinggi
Perhatikan bahwa ClusterControl juga mengelola failover dari pengaturan replikasi PostgreSQL, dan mengintegrasikan HAProxy dan VirtualIP untuk secara otomatis merutekan ulang koneksi klien ke master yang berfungsi. Informasi lebih lanjut dapat ditemukan di whitepaper ini di PostgreSQL Automation.
Unduh Whitepaper Hari Ini Pengelolaan &Otomatisasi PostgreSQL dengan ClusterControlPelajari tentang apa yang perlu Anda ketahui untuk menerapkan, memantau, mengelola, dan menskalakan PostgreSQLUnduh WhitepaperPenskalaan
Pada PostgreSQL 10 (dan 11) masih belum ada cara untuk memiliki replikasi multi-master, setidaknya tidak dari inti PostgreSQL. Ini berarti bahwa hanya aktivitas pilih (hanya baca) yang dapat ditingkatkan. Penskalaan di PostgreSQL dicapai dengan menambahkan lebih banyak hot standby, sehingga menyediakan lebih banyak sumber daya untuk aktivitas hanya-baca. Dengan repmgr, mudah untuk menambahkan standby baru seperti yang kita lihat sebelumnya melalui standby clone dan daftar siaga perintah. Siaga yang ditambahkan (atau dihapus) harus diketahui konfigurasi penyeimbang beban. HAProxy, seperti yang disebutkan di atas dalam topik manajemen, adalah penyeimbang beban yang populer untuk PostgreSQL. Biasanya ditambah dengan Keepalive yang menyediakan IP virtual melalui VRRP. Ikhtisar yang bagus tentang penggunaan HAProxy dan Keepalive bersama dengan PostgreSQL dapat ditemukan di artikel ini:PostgreSQL Load Balancing Menggunakan HAProxy &Keepalive.
Pemantauan
Ikhtisar tentang apa yang harus dipantau di PostgreSQL dapat ditemukan di artikel ini:Hal-Hal Utama yang Harus Dipantau di PostgreSQL - Menganalisis Beban Kerja Anda. Ada banyak alat yang dapat menyediakan pemantauan sistem dan postgresql melalui plugin. Beberapa alat mencakup area penyajian grafik grafik nilai sejarah (munin), alat lain mencakup area pemantauan data langsung dan memberikan peringatan langsung (nagios), sementara beberapa alat mencakup kedua area (zabbix). Daftar alat tersebut untuk PostgreSQL dapat ditemukan di sini:https://wiki.postgresql.org/wiki/Monitoring. Alat populer untuk pemantauan offline (berbasis file log) adalah pgBadger. pgBadger adalah skrip Perl yang bekerja dengan mem-parsing log PostgreSQL (yang biasanya mencakup aktivitas satu hari), mengekstrak informasi, menghitung statistik, dan akhirnya menghasilkan halaman html mewah yang menyajikan hasilnya. pgBadger tidak membatasi pengaturan log_line_prefix, mungkin menyesuaikan dengan format Anda yang sudah ada. Misalnya jika Anda telah mengatur sesuatu di postgresql.conf Anda seperti:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'maka perintah pgbadger untuk mengurai file log dan menghasilkan hasilnya mungkin terlihat seperti:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger menyediakan laporan untuk:
- Ikhtisar statistik (kebanyakan lalu lintas SQL)
- Koneksi (per detik, per database/pengguna/host)
- Sesi (jumlah, waktu sesi, per database/pengguna/host/aplikasi)
- Pos pemeriksaan (buffer, file wal, aktivitas)
- Penggunaan file sementara
- Aktivitas vakum/Analisis (per tabel, tupel/halaman dihapus)
- Kunci
- Kueri (menurut jenis/basis data/pengguna/host/aplikasi, durasi menurut pengguna)
- Atas (Kueri:paling lambat, memakan waktu, lebih sering, paling lambat dinormalisasi)
- Peristiwa (Kesalahan, Peringatan, Kematian, dll)
Layar yang menunjukkan sesi terlihat seperti:
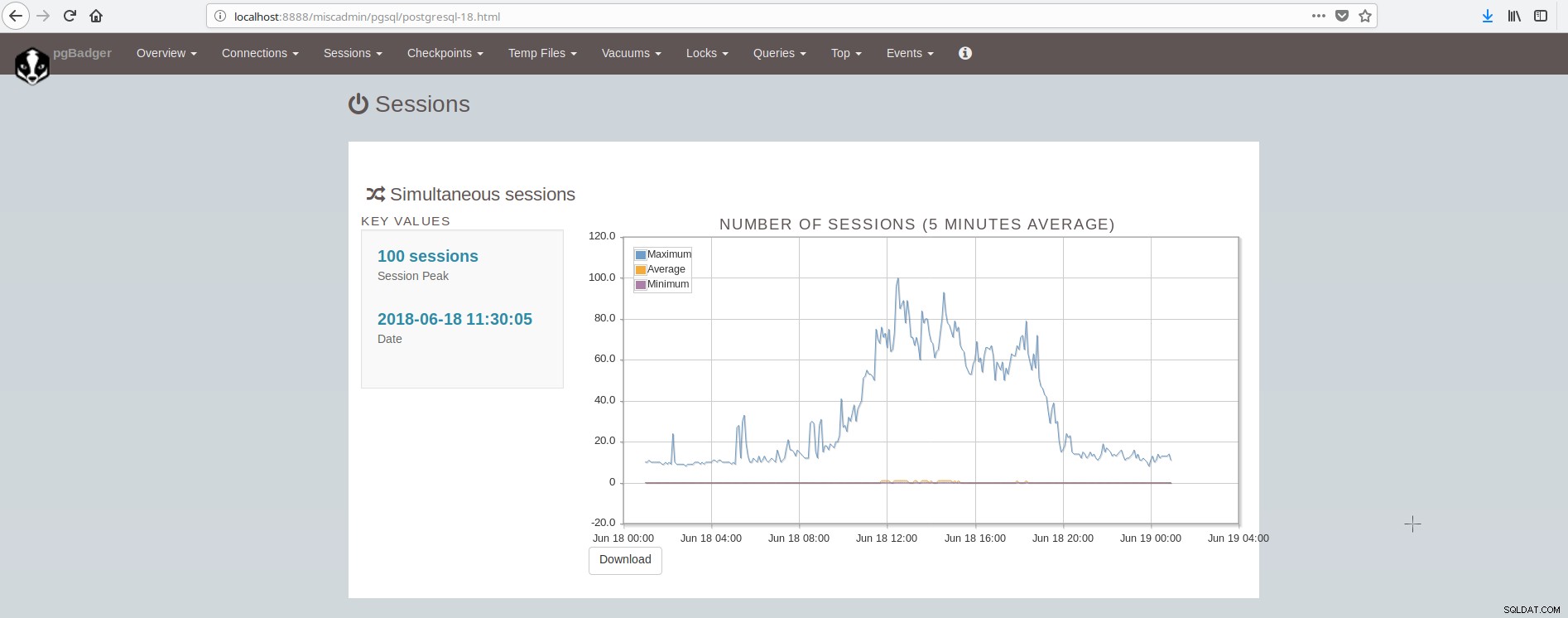
Seperti yang dapat kita simpulkan, rata-rata instalasi PostgreSQL harus mengintegrasikan dan menangani banyak alat untuk memiliki infrastruktur modern yang andal dan cepat dan ini cukup rumit untuk dicapai, kecuali jika ada tim besar yang terlibat dalam postgresql dan administrasi sistem. Sebuah suite bagus yang melakukan semua hal di atas dan lebih banyak lagi adalah ClusterControl.