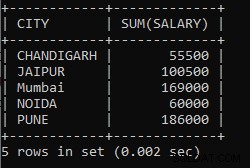
Mengapa?
mengapa versi C jauh lebih cepat?
Array PostgreSQL sendiri merupakan struktur data yang tidak efisien. Itu bisa berisi apa saja tipe data dan mampu menjadi multi-dimensi, jadi banyak pengoptimalan tidak mungkin dilakukan. Namun, seperti yang Anda lihat, mungkin untuk bekerja dengan array yang sama lebih cepat di C.
Itu karena akses array di C dapat menghindari banyak pekerjaan berulang yang terlibat dalam akses array PL/PgSQL. Lihat saja src/backend/utils/adt/arrayfuncs.c , array_ref . Sekarang lihat bagaimana itu dipanggil dari src/backend/executor/execQual.c di ExecEvalArrayRef . Yang berjalan untuk setiap akses larik individu dari PL/PgSQL, seperti yang Anda lihat dengan melampirkan gdb ke pid yang ditemukan dari select pg_backend_pid() , menyetel breakpoint di ExecEvalArrayRef , melanjutkan, dan menjalankan fungsi Anda.
Lebih penting lagi, di PL/PgSQL setiap pernyataan yang Anda jalankan dijalankan melalui mesin eksekutor kueri. Ini membuat pernyataan kecil dan murah cukup lambat bahkan memungkinkan fakta bahwa mereka sudah disiapkan sebelumnya. Sesuatu seperti:
a := b + c
sebenarnya dieksekusi oleh PL/PgSQL lebih seperti:
SELECT b + c INTO a;
Anda dapat mengamati ini jika Anda mengubah level debug cukup tinggi, memasang debugger dan memecahkannya pada titik yang sesuai, atau menggunakan auto_explain modul dengan analisis pernyataan bersarang. Untuk memberi Anda gambaran tentang berapa banyak overhead yang dikenakan ketika Anda menjalankan banyak pernyataan sederhana kecil (seperti akses array), lihat contoh ini backtrace dan catatan saya di atasnya.
Ada juga overhead awal yang signifikan untuk setiap pemanggilan fungsi PL/PgSQL. Itu tidak besar, tetapi cukup untuk ditambahkan saat digunakan sebagai agregat.
Pendekatan yang lebih cepat dalam C
Dalam kasus Anda, saya mungkin akan melakukannya dalam C, seperti yang telah Anda lakukan, tetapi saya akan menghindari menyalin array saat dipanggil sebagai agregat. Anda dapat memeriksa apakah itu dipanggil dalam konteks agregat:
if (AggCheckCallContext(fcinfo, NULL))
dan jika demikian, gunakan nilai asli sebagai pengganti yang dapat diubah, ubah lalu kembalikan, alih-alih mengalokasikan yang baru. Saya akan menulis demo untuk memverifikasi bahwa ini mungkin dengan array segera... (update) atau tidak-begitu-singkat, saya lupa betapa mengerikan bekerja dengan array PostgreSQL di C. Ini dia:
// append to contrib/intarray/_int_op.c
PG_FUNCTION_INFO_V1(add_intarray_cols);
Datum add_intarray_cols(PG_FUNCTION_ARGS);
Datum
add_intarray_cols(PG_FUNCTION_ARGS)
{
ArrayType *a,
*b;
int i, n;
int *da,
*db;
if (PG_ARGISNULL(1))
ereport(ERROR, (errmsg("Second operand must be non-null")));
b = PG_GETARG_ARRAYTYPE_P(1);
CHECKARRVALID(b);
if (AggCheckCallContext(fcinfo, NULL))
{
// Called in aggregate context...
if (PG_ARGISNULL(0))
// ... for the first time in a run, so the state in the 1st
// argument is null. Create a state-holder array by copying the
// second input array and return it.
PG_RETURN_POINTER(copy_intArrayType(b));
else
// ... for a later invocation in the same run, so we'll modify
// the state array directly.
a = PG_GETARG_ARRAYTYPE_P(0);
}
else
{
// Not in aggregate context
if (PG_ARGISNULL(0))
ereport(ERROR, (errmsg("First operand must be non-null")));
// Copy 'a' for our result. We'll then add 'b' to it.
a = PG_GETARG_ARRAYTYPE_P_COPY(0);
CHECKARRVALID(a);
}
// This requirement could probably be lifted pretty easily:
if (ARR_NDIM(a) != 1 || ARR_NDIM(b) != 1)
ereport(ERROR, (errmsg("One-dimesional arrays are required")));
// ... as could this by assuming the un-even ends are zero, but it'd be a
// little ickier.
n = (ARR_DIMS(a))[0];
if (n != (ARR_DIMS(b))[0])
ereport(ERROR, (errmsg("Arrays are of different lengths")));
da = ARRPTR(a);
db = ARRPTR(b);
for (i = 0; i < n; i++)
{
// Fails to check for integer overflow. You should add that.
*da = *da + *db;
da++;
db++;
}
PG_RETURN_POINTER(a);
}
dan tambahkan ini ke contrib/intarray/intarray--1.0.sql :
CREATE FUNCTION add_intarray_cols(_int4, _int4) RETURNS _int4
AS 'MODULE_PATHNAME'
LANGUAGE C IMMUTABLE;
CREATE AGGREGATE sum_intarray_cols(_int4) (sfunc = add_intarray_cols, stype=_int4);
(lebih tepatnya Anda akan membuat intarray--1.1.sql dan intarray--1.0--1.1.sql dan perbarui intarray.control . Ini hanya peretasan cepat.)
Gunakan:
make USE_PGXS=1
make USE_PGXS=1 install
untuk mengkompilasi dan menginstal.
Sekarang DROP EXTENSION intarray; (jika Anda sudah memilikinya) dan CREATE EXTENSION intarray; .
Anda sekarang akan memiliki fungsi agregat sum_intarray_cols tersedia untuk Anda (seperti sum(int4[]) , serta dua operan add_intarray_cols (seperti array_add Anda ).
Dengan mengkhususkan diri dalam array integer, sejumlah besar kompleksitas hilang. Banyak penyalinan dihindari dalam kasus agregat, karena kita dapat dengan aman memodifikasi larik "status" (argumen pertama) di tempat. Agar semuanya tetap konsisten, dalam kasus pemanggilan non-agregat, kami mendapatkan salinan argumen pertama sehingga kami masih dapat bekerja dengannya di tempat dan mengembalikannya.
Pendekatan ini dapat digeneralisasi untuk mendukung tipe data apa pun dengan menggunakan cache fmgr untuk mencari fungsi add untuk tipe yang diinginkan, dll. Saya tidak terlalu tertarik untuk melakukannya, jadi jika Anda membutuhkannya (katakanlah, untuk menjumlahkan kolom NUMERIC array) lalu ... bersenang-senanglah.
Demikian pula, jika Anda perlu menangani panjang array yang berbeda, Anda mungkin dapat mencari tahu apa yang harus dilakukan dari atas.