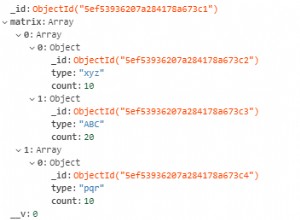
Anotasi untuk mereka yang mencari - Hitungan Asing
Sedikit lebih baik daripada yang semula dijawab adalah dengan benar-benar menggunakan bentuk $lookup
dari MongoDB 3.6. Ini sebenarnya dapat melakukan "penghitungan" dalam ekspresi "sub-pipa" sebagai lawan mengembalikan "array" untuk pemfilteran dan penghitungan berikutnya atau bahkan menggunakan $unwind
db.emailGroup.aggregate([
{ "$lookup": {
"from": "link",
"let": { "id": "$_id" },
"pipeline": [
{ "$match": {
"originalLink": "",
"$expr": { "$eq": [ "$$id", "$_id" ] }
}},
{ "$count": "count" }
],
"as": "linkCount"
}},
{ "$addFields": {
"linkCount": { "$sum": "$linkCount.count" }
}}
])
Bukan pertanyaan awal yang ditanyakan tetapi bagian dari jawaban di bawah ini dalam bentuk yang sekarang paling optimal, tentu saja hasil dari $lookup
dikurangi menjadi "jumlah yang cocok" hanya alih-alih "semua dokumen yang cocok".
Asli
Cara yang benar untuk melakukannya adalah dengan menambahkan "linkCount" ke $group
panggung serta $first
pada bidang tambahan apa pun dari dokumen induk untuk mendapatkan formulir "tunggal" seperti status "sebelum" $unwind
diproses pada larik yang merupakan hasil dari $lookup
:
Semua Detail
db.emailGroup.aggregate([
{ "$lookup": {
"from": "link",
"localField": "_id",
"foreignField": "emailGroupId",
"as": "link"
}},
{ "$unwind": "$link" },
{ "$match": { "link.originalLink": "" } },
{ "$group": {
"_id": "$_id",
"partId": { "$first": "$partId" },
"link": { "$push": "$link" },
"linkCount": {
"$sum": {
"$size": {
"$ifNull": [ "$link.linkHistory", [] ]
}
}
}
}}
])
Menghasilkan:
{
"_id" : ObjectId("594a6c47f51e075db713ccb6"),
"partId" : "f56c7c71eb14a20e6129a667872f9c4f",
"link" : [
{
"_id" : ObjectId("594b96d6f51e075db67c44c9"),
"originalLink" : "",
"emailGroupId" : ObjectId("594a6c47f51e075db713ccb6"),
"linkHistory" : [
{
"_id" : ObjectId("594b96f5f51e075db713ccdf")
},
{
"_id" : ObjectId("594b971bf51e075db67c44ca")
}
]
}
],
"linkCount" : 2
}
Kelompokkan Menurut partId
db.emailGroup.aggregate([
{ "$lookup": {
"from": "link",
"localField": "_id",
"foreignField": "emailGroupId",
"as": "link"
}},
{ "$unwind": "$link" },
{ "$match": { "link.originalLink": "" } },
{ "$group": {
"_id": "$partId",
"linkCount": {
"$sum": {
"$size": {
"$ifNull": [ "$link.linkHistory", [] ]
}
}
}
}}
])
Menghasilkan
{
"_id" : "f56c7c71eb14a20e6129a667872f9c4f",
"linkCount" : 2
}
Alasan Anda melakukannya dengan cara ini dengan $unwind
lalu $match
adalah karena bagaimana MongoDB benar-benar menangani pipa ketika dikeluarkan dalam urutan itu. Inilah yang terjadi pada $lookup
seperti yang ditunjukkan "jelaskan" keluaran dari operasi:
{
"$lookup" : {
"from" : "link",
"as" : "link",
"localField" : "_id",
"foreignField" : "emailGroupId",
"unwinding" : {
"preserveNullAndEmptyArrays" : false
},
"matching" : {
"originalLink" : {
"$eq" : ""
}
}
}
},
{
"$group" : {
Saya meninggalkan bagian dengan $group
dalam output itu untuk menunjukkan bahwa dua tahap pipa lainnya "menghilang". Ini karena mereka telah "digabungkan" ke $lookup
tahap pipa seperti yang ditunjukkan. Ini sebenarnya bagaimana MongoDB menangani kemungkinan bahwa Batas BSON dapat dilampaui oleh hasil "bergabung" hasil $lookup
ke dalam larik dokumen induk.
Anda dapat menulis operasi secara bergantian seperti ini:
Semua Detail
db.emailGroup.aggregate([
{ "$lookup": {
"from": "link",
"localField": "_id",
"foreignField": "emailGroupId",
"as": "link"
}},
{ "$addFields": {
"link": {
"$filter": {
"input": "$link",
"as": "l",
"cond": { "$eq": [ "$$l.originalLink", "" ] }
}
},
"linkCount": {
"$sum": {
"$map": {
"input": {
"$filter": {
"input": "$link",
"as": "l",
"cond": { "$eq": [ "$$l.originalLink", "" ] }
}
},
"as": "l",
"in": { "$size": { "$ifNull": [ "$$l.linkHistory", [] ] } }
}
}
}
}}
])
Kelompokkan menurut partId
db.emailGroup.aggregate([
{ "$lookup": {
"from": "link",
"localField": "_id",
"foreignField": "emailGroupId",
"as": "link"
}},
{ "$addFields": {
"link": {
"$filter": {
"input": "$link",
"as": "l",
"cond": { "$eq": [ "$$l.originalLink", "" ] }
}
},
"linkCount": {
"$sum": {
"$map": {
"input": {
"$filter": {
"input": "$link",
"as": "l",
"cond": { "$eq": [ "$$l.originalLink", "" ] }
}
},
"as": "l",
"in": { "$size": { "$ifNull": [ "$$l.linkHistory", [] ] } }
}
}
}
}},
{ "$unwind": "$link" },
{ "$group": {
"_id": "$partId",
"linkCount": { "$sum": "$linkCount" }
}}
])
Yang memiliki keluaran yang sama tetapi "berbeda" dari kueri pertama karena $filter
di sini diterapkan "setelah" SEMUA hasil $lookup
dikembalikan ke larik baru dari dokumen induk.
Jadi dalam hal kinerja, sebenarnya lebih efektif untuk melakukannya dengan cara pertama dan juga portabel untuk kemungkinan kumpulan hasil besar "sebelum memfilter" yang jika tidak akan melanggar Batas BSON 16MB.
Sebagai catatan tambahan bagi mereka yang tertarik, dalam rilis MongoDB mendatang ( mungkin 3.6 dan lebih tinggi ) Anda dapat menggunakan $replaceRoot
sebagai ganti $addFields
dengan penggunaan baru $mergeObjects operator pipa. Keuntungan dari ini adalah sebagai "blok", kita dapat mendeklarasikan "filtered" konten sebagai variabel melalui $let
, yang berarti Anda tidak perlu menulis $filter yang sama
"dua kali":
db.emailGroup.aggregate([
{ "$lookup": {
"from": "link",
"localField": "_id",
"foreignField": "emailGroupId",
"as": "link"
}},
{ "$replaceRoot": {
"newRoot": {
"$mergeObjects": [
"$$ROOT",
{ "$let": {
"vars": {
"filtered": {
"$filter": {
"input": "$link",
"as": "l",
"cond": { "$eq": [ "$$l.originalLink", "" ] }
}
}
},
"in": {
"link": "$$filtered",
"linkCount": {
"$sum": {
"$map": {
"input": "$$filtered.linkHistory",
"as": "lh",
"in": { "$size": { "$ifNull": [ "$$lh", [] ] } }
}
}
}
}
}}
]
}
}}
])
Meskipun demikian cara terbaik untuk melakukan "difilter" $lookup
operasi "masih" saat ini menggunakan $unwind
lalu $match
pola, hingga Anda dapat memberikan argumen kueri ke $ pencarian
secara langsung.