ClusterControl diprogram dengan sejumlah algoritme pemulihan untuk secara otomatis merespons berbagai jenis kegagalan umum yang memengaruhi sistem database Anda. Ini memahami berbagai jenis topologi database dan manajemen proses terkait database untuk membantu Anda menentukan cara terbaik untuk memulihkan cluster. Di satu sisi, ClusterControl meningkatkan ketersediaan database Anda.
Beberapa manajer topologi hanya mencakup pemulihan cluster seperti MHA, Orchestrator dan mysqlfailover tetapi Anda harus menangani pemulihan node sendiri. ClusterControl mendukung pemulihan di tingkat cluster dan node.
Opsi Konfigurasi
Ada dua komponen pemulihan yang didukung oleh ClusterControl, yaitu:
- Cluster - Mencoba memulihkan cluster ke status operasional
- Node - Mencoba memulihkan node ke status operasional
Kedua komponen ini adalah hal terpenting untuk memastikan ketersediaan layanan setinggi mungkin. Jika Anda sudah memiliki manajer topologi di atas ClusterControl, Anda dapat menonaktifkan fitur pemulihan otomatis dan membiarkan manajer topologi lain menanganinya untuk Anda. Anda memiliki semua kemungkinan dengan ClusterControl.
Fitur pemulihan otomatis dapat diaktifkan dan dinonaktifkan dengan tombol AKTIF/MATI sederhana, dan berfungsi untuk pemulihan klaster atau simpul. Ikon hijau berarti diaktifkan dan ikon merah berarti dinonaktifkan. Tangkapan layar berikut menunjukkan di mana Anda dapat menemukannya di daftar cluster database:
Ada 3 parameter ClusterControl yang dapat digunakan untuk mengontrol perilaku pemulihan. Semua parameter default ke true (diatur dengan boolean integer 0 atau 1):
- enable_autorecovery - Mengaktifkan pemulihan cluster dan node. Parameter ini adalah superset dari enable_cluster_recovery dan enable_node_recovery. Jika disetel ke 0, parameter subset akan dimatikan.
- enable_cluster_recovery - ClusterControl akan melakukan pemulihan cluster jika diaktifkan.
- enable_node_recovery - ClusterControl akan melakukan pemulihan node jika diaktifkan.
Pemulihan cluster mencakup upaya pemulihan untuk memunculkan seluruh topologi cluster. Misalnya, replikasi master-slave harus memiliki setidaknya satu master yang hidup pada waktu tertentu, terlepas dari jumlah slave yang tersedia. ClusterControl mencoba untuk memperbaiki topologi setidaknya sekali untuk kluster replikasi, tetapi tanpa batas untuk replikasi multi-master seperti NDB Cluster dan Galera Cluster.
Pemulihan node mencakup masalah pemulihan node seperti jika sebuah node dihentikan tanpa sepengetahuan ClusterControl, misalnya, melalui perintah penghentian sistem dari konsol SSH atau dihentikan oleh proses OOM.
Pemulihan Node
ClusterControl dapat memulihkan node database jika terjadi kegagalan intermiten dengan memantau proses dan konektivitas ke node database. Untuk prosesnya, cara kerjanya mirip dengan systemd, di mana ia akan memastikan layanan MySQL dimulai dan berjalan kecuali jika Anda sengaja menghentikannya melalui ClusterControl UI.
Jika node kembali online, ClusterControl akan membuat koneksi kembali ke node database dan akan melakukan tindakan yang diperlukan. Berikut ini adalah apa yang akan dilakukan ClusterControl untuk memulihkan sebuah simpul:
- Ini akan menunggu systemd/chkconfig/init untuk memulai layanan/proses yang dipantau selama 30 detik
- Jika layanan/proses yang dipantau masih down, ClusterControl akan mencoba memulai layanan database secara otomatis.
- Jika ClusterControl tidak dapat memulihkan layanan/proses yang dipantau, alarm akan dimunculkan.
Perhatikan bahwa jika penonaktifan database dimulai oleh pengguna, ClusterControl tidak akan mencoba memulihkan node tertentu. Ia mengharapkan pengguna untuk memulai kembali melalui ClusterControl UI dengan membuka Node -> Node Actions -> Start Node atau menggunakan perintah OS secara eksplisit.
Pemulihan mencakup semua layanan terkait basis data seperti ProxySQL, HAProxy, MaxScale, Keepalived, eksportir Prometheus, dan garbd. Perhatian khusus untuk eksportir Prometheus di mana ClusterControl menggunakan program yang disebut "daemon" untuk melakukan daemonisasi proses eksportir. ClusterControl akan mencoba terhubung ke port mendengarkan eksportir untuk pemeriksaan kesehatan dan verifikasi. Oleh karena itu, disarankan untuk membuka port eksportir dari ClusterControl dan server Prometheus untuk memastikan tidak ada alarm palsu selama pemulihan.
Pemulihan Cluster
ClusterControl memahami topologi database dan mengikuti praktik terbaik dalam melakukan pemulihan. Untuk cluster database yang dilengkapi dengan toleransi kesalahan bawaan seperti Galera Cluster, NDB Cluster, dan MongoDB Replicaset, proses failover akan dilakukan secara otomatis oleh server database melalui penghitungan kuorum, detak jantung, dan pergantian peran (jika ada). ClusterControl memantau proses dan membuat penyesuaian yang diperlukan untuk visualisasi seperti mencerminkan perubahan di bawah tampilan Topologi dan menyesuaikan komponen pemantauan dan manajemen untuk peran baru, misalnya node utama baru dalam set replika.
Untuk teknologi database yang tidak memiliki toleransi kesalahan bawaan dengan pemulihan otomatis seperti Replikasi MySQL/MariaDB dan Replikasi Streaming PostgreSQL/TimescaleDB, ClusterControl akan melakukan prosedur pemulihan dengan mengikuti praktik terbaik yang disediakan oleh vendor basis data. Jika pemulihan gagal, campur tangan pengguna diperlukan, dan tentu saja Anda akan mendapatkan pemberitahuan alarm mengenai hal ini.
Dalam topologi campuran/hibrida, misalnya slave asinkron yang dilampirkan ke Galera Cluster atau NDB Cluster, node akan dipulihkan oleh ClusterControl jika pemulihan cluster diaktifkan.
Pemulihan cluster tidak berlaku untuk server MySQL mandiri. Namun, disarankan untuk mengaktifkan pemulihan node dan cluster untuk jenis cluster ini di UI ClusterControl.
Replikasi MySQL/MariaDB
ClusterControl mendukung pemulihan pengaturan replikasi MySQL/MariaDB berikut:
- Master-slave dengan MySQL GTID
- Tukang-budak dengan MariaDB GTID
- Master-slave dengan tanpa GTID (baik MySQL dan MariaDB)
- Master-master dengan MySQL GTID
- Master-master dengan MariaDB GTID
- Budak asinkron yang dilampirkan ke Gugus Galera
ClusterControl akan mengikuti parameter berikut saat melakukan pemulihan cluster:
- aktifkan_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
Untuk detail lebih lanjut tentang setiap parameter, lihat halaman dokumentasi.
ClusterControl akan mematuhi aturan berikut saat memantau dan mengelola replikasi master-slave:
- Semua node akan dimulai dengan read_only=ON dan super_read_only=ON (terlepas dari perannya).
- Hanya satu master (read_only=OFF) yang diizinkan untuk beroperasi pada waktu tertentu.
- Mengandalkan variabel MySQL report_host untuk memetakan topologi.
- Jika ada dua atau lebih node yang memiliki read_only=OFF pada satu waktu, ClusterControl akan secara otomatis menyetel read_only=ON pada kedua master, untuk melindunginya dari penulisan yang tidak disengaja. Intervensi pengguna diperlukan untuk memilih master yang sebenarnya dengan menonaktifkan read-only. Buka Node -> Tindakan Node -> Nonaktifkan Hanya Baca.
Jika master aktif mati, ClusterControl akan mencoba melakukan failover master dalam urutan berikut:
- Setelah 3 detik master tidak dapat dijangkau, ClusterControl akan membunyikan alarm.
- Periksa ketersediaan slave, setidaknya salah satu slave harus dapat dijangkau oleh ClusterControl.
- Pilih budak sebagai kandidat untuk menjadi master.
- ClusterControl akan menghitung kemungkinan transaksi yang salah jika GTID diaktifkan.
- Jika tidak ada transaksi yang salah terdeteksi, yang terpilih akan dipromosikan sebagai master baru.
- Buat dan berikan pengguna replikasi untuk digunakan oleh budak.
- Ubah master untuk semua budak yang menunjuk ke master lama ke master yang baru dipromosikan.
- Mulai slave dan aktifkan hanya baca.
- Siram log di semua node.
- Jika promosi slave gagal, ClusterControl akan membatalkan tugas pemulihan. Intervensi pengguna atau restart layanan cmon diperlukan untuk memicu tugas pemulihan lagi.
- Ketika master lama tersedia lagi, master lama akan dimulai sebagai hanya-baca dan tidak akan menjadi bagian dari replikasi. Intervensi pengguna diperlukan.
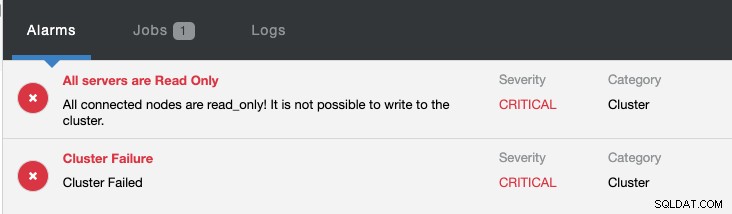
Pada saat yang sama, alarm berikut akan dibunyikan:
Lihat Pengantar Failover untuk Replikasi MySQL - Blog 101 dan Failover Otomatis Replikasi MySQL - Baru di ClusterControl 1.4 untuk mendapatkan informasi lebih lanjut tentang cara mengonfigurasi dan mengelola failover replikasi MySQL dengan ClusterControl.
Replikasi Streaming PostgreSQL/TimescaleDB
ClusterControl mendukung pemulihan pengaturan replikasi PostgreSQL berikut:
- Replikasi Streaming PostgreSQL
- Replikasi Streaming TimescaleDB
ClusterControl akan mengikuti parameter berikut saat melakukan pemulihan cluster:
- aktifkan_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
Untuk detail lebih lanjut tentang setiap parameter, lihat halaman dokumentasi.
ClusterControl akan mematuhi aturan berikut untuk mengelola dan memantau penyiapan replikasi streaming PostgreSQL:
- wal_level disetel ke "replika" (atau "hot_standby" bergantung pada versi PostgreSQL).
- Variabel archive_mode disetel ke AKTIF pada master.
- Setel file recovery.conf pada node slave, yang mengubah node menjadi hot standby dengan read-only diaktifkan.
Jika master aktif mati, ClusterControl akan mencoba melakukan pemulihan cluster dengan urutan berikut:
- Setelah 10 detik master tidak dapat dijangkau, ClusterControl akan membunyikan alarm.
- Setelah 10 detik waktu tunggu yang tenang, ClusterControl akan memulai tugas master failover.
- Contoh replayLocation dan acceptLocation pada semua node yang tersedia untuk menentukan node yang paling canggih.
- Promosikan node paling canggih sebagai master baru.
- Hentikan budak.
- Verifikasi status sinkronisasi dengan pg_rewind.
- Memulai ulang slave dengan master baru.
- Jika promosi slave gagal, ClusterControl akan membatalkan tugas pemulihan. Intervensi pengguna atau restart layanan cmon diperlukan untuk memicu tugas pemulihan lagi.
- Ketika master lama tersedia lagi, master lama akan ditutup secara paksa dan tidak akan menjadi bagian dari replikasi. Intervensi pengguna diperlukan. Lihat lebih jauh ke bawah.
Saat master lama kembali online, jika layanan PostgreSQL sedang berjalan, ClusterControl akan mematikan layanan PostgreSQL secara paksa. Ini untuk melindungi server dari penulisan yang tidak disengaja, karena ini akan dimulai tanpa file pemulihan (recovery.conf), yang berarti dapat ditulis. Anda seharusnya mengharapkan baris berikut akan muncul di postgresql-{day}.log:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downPostgreSQL dimulai setelah server kembali online sekitar 05:06:10 tetapi ClusterControl melakukan shutdown cepat 17 detik setelah itu sekitar 05:06:27. Jika ini adalah sesuatu yang tidak Anda inginkan, Anda dapat menonaktifkan pemulihan node untuk cluster ini untuk sementara.
Lihat Failover Otomatis dari Replikasi Postgres dan Failover untuk Replikasi PostgreSQL 101 untuk mendapatkan informasi lebih lanjut tentang cara mengonfigurasi dan mengelola kegagalan replikasi PostgreSQL dengan ClusterControl.
Kesimpulan
Pemulihan otomatis ClusterControl memahami topologi klaster basis data dan mampu memulihkan klaster yang turun atau terdegradasi ke klaster yang beroperasi penuh yang akan sangat meningkatkan waktu kerja layanan basis data. Coba ClusterControl sekarang dan capai sembilan Anda dalam SLA dan ketersediaan database. Tidak tahu sembilan Anda? Lihat kalkulator sembilan yang keren ini.



