Dalam artikel ini kita akan membuat scraper untuk aktual pertunjukan lepas di mana klien menginginkan program Python untuk mengikis data dari Stack Overflow untuk mengambil pertanyaan baru (judul pertanyaan dan URL). Data yang tergores kemudian harus disimpan di MongoDB. Perlu dicatat bahwa Stack Overflow memiliki API, yang dapat digunakan untuk mengakses tepat data yang sama. Namun, klien menginginkan scraper, jadi dia mendapatkan scraper.
Bonus Gratis: Klik di sini untuk mengunduh kerangka proyek Python + MongoDB dengan kode sumber lengkap yang menunjukkan cara mengakses MongoDB dari Python.
Pembaruan:
- 03/01/2014 - Memfaktorkan ulang laba-laba. Terima kasih, @kissgyorgy.
- 18/02/2015 - Menambahkan Bagian 2.
- 09/06/2015 - Diperbarui ke versi terbaru Scrapy dan PyMongo - semangat!
Seperti biasa, pastikan untuk meninjau persyaratan penggunaan/layanan situs dan menghormati robots.txt file sebelum memulai pekerjaan pengikisan. Pastikan untuk mematuhi praktik pengikisan etis dengan tidak membanjiri situs dengan banyak permintaan dalam rentang waktu yang singkat. Perlakukan situs apa pun yang Anda kikis seolah-olah itu milik Anda sendiri .
Pemasangan
Kami membutuhkan perpustakaan Scrapy (v1.0.3) bersama dengan PyMongo (v3.0.3) untuk menyimpan data di MongoDB. Anda juga perlu menginstal MongoDB (tidak tercakup).
Tergores
Jika Anda menjalankan OSX atau Linux, instal Scrapy dengan pip (dengan virtualenv Anda diaktifkan):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Jika Anda menggunakan mesin Windows, Anda perlu menginstal sejumlah dependensi secara manual. Silakan merujuk ke dokumentasi resmi untuk instruksi terperinci serta video Youtube yang saya buat ini.
Setelah Scrapy diatur, verifikasi instalasi Anda dengan menjalankan perintah ini di shell Python:
>>>>>> import scrapy
>>>
Jika Anda tidak mendapatkan kesalahan, maka Anda siap melakukannya!
PyMongo
Selanjutnya, instal PyMongo dengan pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Sekarang kita bisa mulai membuat crawler.
Proyek Scrapy
Mari kita mulai proyek Scrapy baru:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Ini membuat sejumlah file dan folder yang menyertakan boilerplate dasar agar Anda dapat memulai dengan cepat:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Tentukan Data
items.py file digunakan untuk mendefinisikan "wadah" penyimpanan untuk data yang kami rencanakan untuk dikikis.
StackItem() kelas mewarisi dari Item (docs), yang pada dasarnya memiliki sejumlah objek yang telah ditentukan sebelumnya yang telah dibuat oleh Scrapy untuk kita:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Mari tambahkan beberapa item yang sebenarnya ingin kita kumpulkan. Untuk setiap pertanyaan klien membutuhkan judul dan URL. Jadi, perbarui items.py seperti ini:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Buat Laba-laba
Buat file bernama stack_spider.py di direktori "laba-laba". Di sinilah keajaiban terjadi – misalnya, di mana kami akan memberi tahu Scrapy cara menemukan tepat data yang kita cari. Seperti yang dapat Anda bayangkan, ini khusus ke setiap halaman web yang ingin Anda gores.
Mulailah dengan mendefinisikan kelas yang diwarisi dari Spider Scrapy lalu tambahkan atribut sesuai kebutuhan:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
Beberapa variabel pertama cukup jelas (docs):
namemendefinisikan nama Laba-laba.allowed_domainsberisi URL dasar untuk domain yang diizinkan untuk dijelajahi laba-laba.start_urlsadalah daftar URL tempat laba-laba mulai merayapi. Semua URL berikutnya akan dimulai dari data yang diunduh spider dari URL distart_urls.
Pemilih XPath
Selanjutnya, Scrapy menggunakan pemilih XPath untuk mengekstrak data dari situs web. Dengan kata lain, kita dapat memilih bagian tertentu dari data HTML berdasarkan XPath yang diberikan. Sebagaimana dinyatakan dalam dokumentasi Scrapy, “XPath adalah bahasa untuk memilih node dalam dokumen XML, yang juga dapat digunakan dengan HTML.”
Anda dapat dengan mudah menemukan Xpath tertentu menggunakan Alat Pengembang Chrome. Cukup periksa elemen HTML tertentu, salin XPath, lalu atur (sesuai kebutuhan):
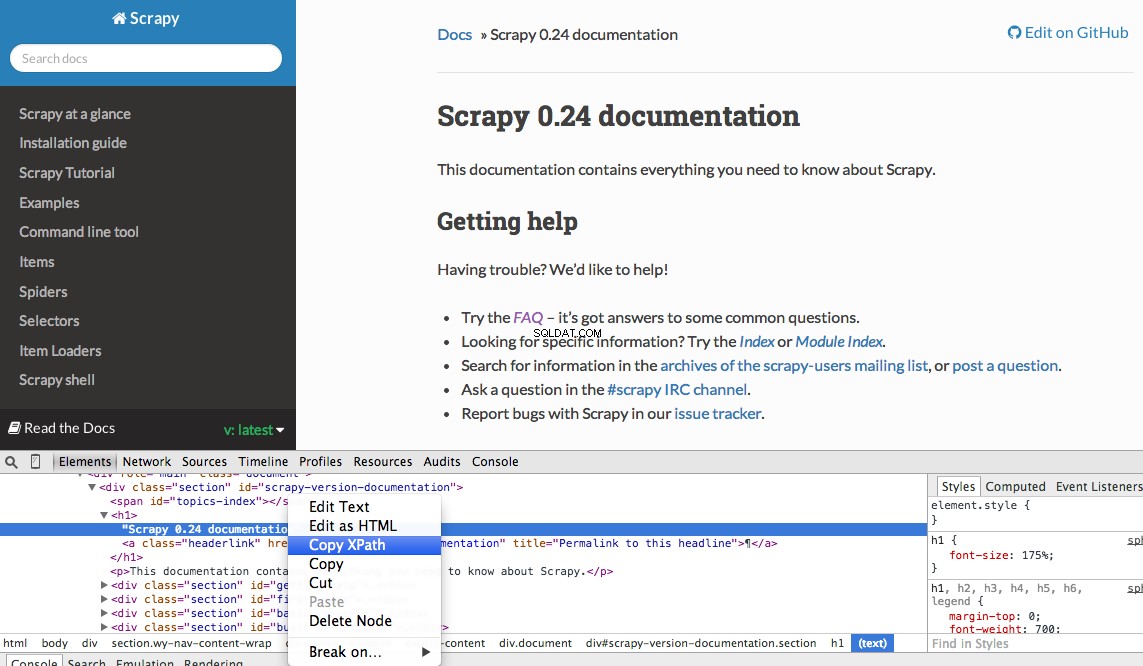
Alat Pengembang juga memberi Anda kemampuan untuk menguji pemilih XPath di Konsol JavaScript dengan menggunakan $x - yaitu, $x("//img") :
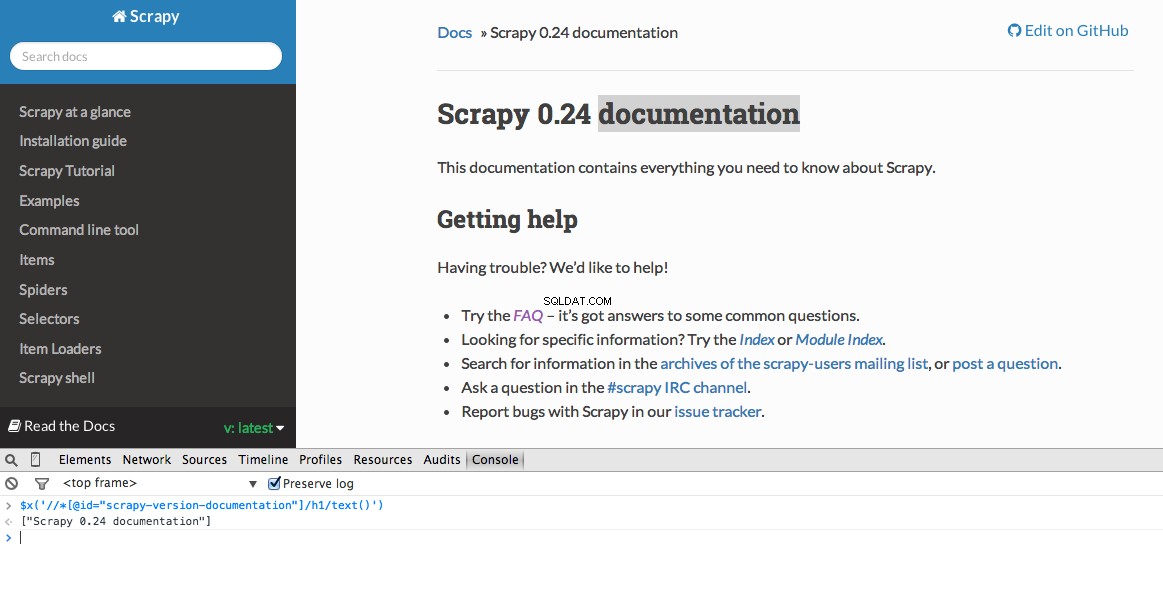
Sekali lagi, kami pada dasarnya memberi tahu Scrapy di mana harus mulai mencari informasi berdasarkan XPath yang ditentukan. Mari buka situs Stack Overflow di Chrome dan temukan pemilih XPath.
Klik kanan pada pertanyaan pertama dan pilih “Inspect Element”:
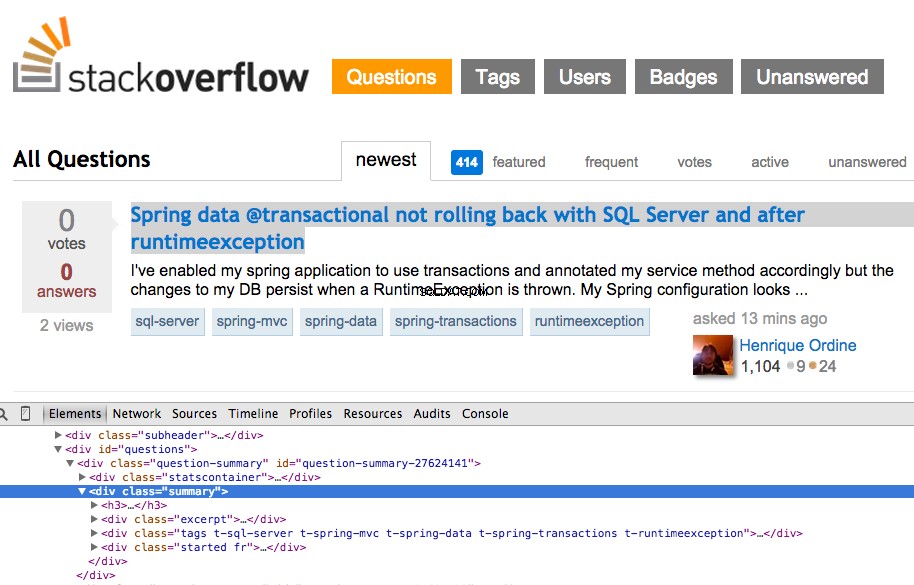
Sekarang ambil XPath untuk <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] , lalu uji di Konsol JavaScript:
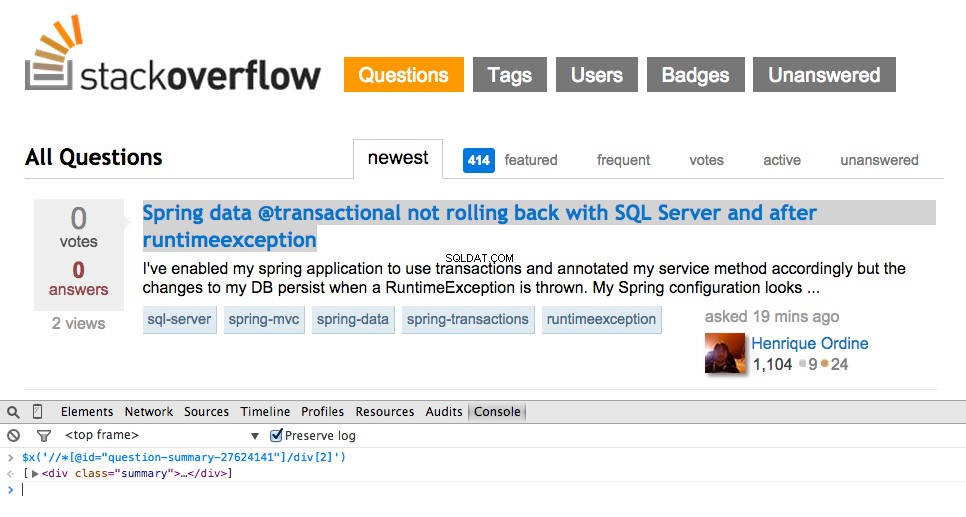
Seperti yang Anda tahu, itu hanya memilih satu pertanyaan. Jadi kita perlu mengubah XPath untuk mengambil semua pertanyaan. Ada ide? Sederhana saja://div[@class="summary"]/h3 . Apa artinya ini? Pada dasarnya, XPath ini menyatakan:Ambil semua <h3> elemen yang merupakan anak dari <div> yang memiliki kelas summary . Uji XPath ini di Konsol JavaScript.
Perhatikan bagaimana kami tidak menggunakan keluaran XPath yang sebenarnya dari Alat Pengembang Chrome. Dalam kebanyakan kasus, output hanya membantu, yang biasanya mengarahkan Anda ke arah yang benar untuk menemukan XPath yang berfungsi.
Sekarang mari perbarui stack_spider.py naskah:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Ekstrak Datanya
Kita masih perlu mengurai dan mengikis data yang kita inginkan, yang termasuk dalam <div class="summary"><h3> . Sekali lagi, perbarui stack_spider.py seperti ini:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Seiring dengan jejak tumpukan Scrapy, Anda akan melihat 50 judul pertanyaan dan URL yang dikeluarkan. Anda dapat merender output ke file JSON dengan perintah kecil ini:
$ scrapy crawl stack -o items.json -t json
Kami sekarang telah menerapkan Spider kami berdasarkan data yang kami cari. Sekarang kita perlu menyimpan data yang tergores dalam MongoDB.
Simpan Data di MongoDB
Setiap kali item dikembalikan, kami ingin memvalidasi data dan kemudian menambahkannya ke koleksi Mongo.
Langkah awal adalah membuat database yang akan kita gunakan untuk menyimpan semua data yang kita jelajahi. Buka settings.py dan tentukan pipeline dan tambahkan pengaturan database:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Manajemen Pipa
Kami telah menyiapkan laba-laba kami untuk merayapi dan mengurai HTML, dan kami telah menyiapkan pengaturan basis data kami. Sekarang kita harus menghubungkan keduanya bersama-sama melalui pipa di pipelines.py .
Hubungkan ke Basis Data
Pertama, mari kita tentukan metode untuk benar-benar terhubung ke database:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Di sini, kita membuat kelas, MongoDBPipeline() , dan kami memiliki fungsi konstruktor untuk menginisialisasi kelas dengan mendefinisikan pengaturan Mongo dan kemudian menghubungkan ke database.
Memproses Data
Selanjutnya, kita perlu mendefinisikan metode untuk memproses data yang diurai:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Kami membuat koneksi ke database, membongkar data, dan kemudian menyimpannya ke database. Sekarang kita bisa menguji lagi!
Uji
Sekali lagi, jalankan perintah berikut di dalam direktori “stack”:
$ scrapy crawl stack
CATATAN :Pastikan Anda memiliki daemon Mongo -
mongod- berjalan di jendela terminal yang berbeda.
Hore! Kami telah berhasil menyimpan data perayapan kami ke dalam database:
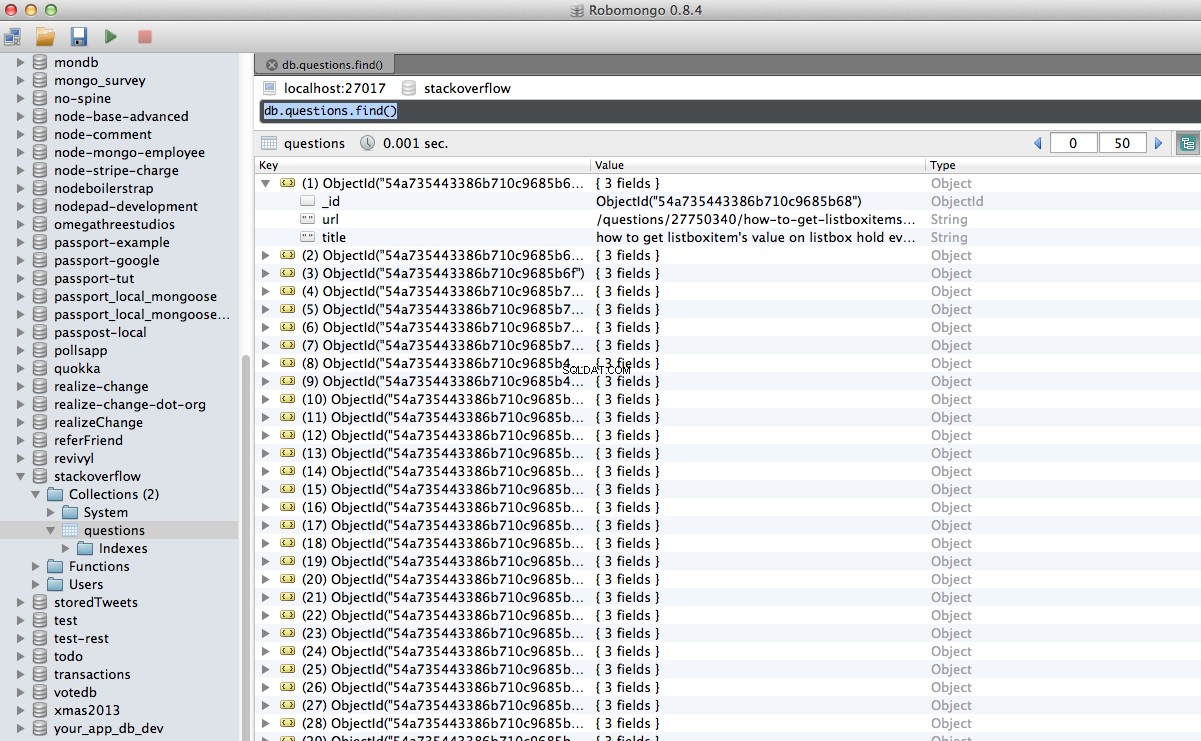
Kesimpulan
Ini adalah contoh yang cukup sederhana menggunakan Scrapy untuk merayapi dan mengikis halaman web. Proyek lepas yang sebenarnya membutuhkan skrip untuk mengikuti tautan pagination dan mengikis setiap halaman menggunakan CrawlSpider (docs), yang sangat mudah diterapkan. Coba terapkan ini sendiri, dan tinggalkan komentar di bawah dengan tautan ke repositori Github untuk tinjauan kode cepat.
Butuh bantuan? Mulailah dengan skrip ini, yang hampir selesai. Kalau begitu lihat Bagian 2 untuk solusi lengkapnya!
Bonus Gratis: Klik di sini untuk mengunduh kerangka proyek Python + MongoDB dengan kode sumber lengkap yang menunjukkan cara mengakses MongoDB dari Python.
Anda dapat mengunduh seluruh kode sumber dari repositori Github. Komentar di bawah dengan pertanyaan. Terima kasih telah Membaca!



