Pelajari cara menggunakan alat OCR, Apache Spark, dan komponen Apache Hadoop lainnya untuk memproses gambar PDF dalam skala besar.
Teknologi pengenalan karakter optik (OCR) telah berkembang secara signifikan selama 20 tahun terakhir. Namun, selama waktu itu, hanya ada sedikit atau tidak ada upaya untuk menggabungkan OCR dengan arsitektur terdistribusi seperti Apache Hadoop untuk memproses sejumlah besar gambar dalam waktu yang hampir real-time.
Dalam posting ini, Anda akan belajar cara menggunakan alat open source standar bersama dengan komponen Hadoop seperti Apache Spark, Apache Solr, dan Apache HBase untuk melakukan hal itu untuk kasus penggunaan informasi perangkat medis. Secara khusus, Anda akan menggunakan kumpulan data publik untuk mengubah teks naratif menjadi bidang yang dapat ditelusuri.
Meskipun contoh ini berkonsentrasi pada informasi perangkat medis, ini dapat diterapkan di banyak skenario lain di mana pemrosesan dan gambar yang bertahan diperlukan. Perusahaan asuransi, misalnya, dapat membuat semua dokumen pindaian mereka dalam file klaim dapat dicari untuk penyelesaian klaim yang lebih baik. Demikian pula, departemen rantai pasokan di fasilitas manufaktur dapat memindai semua lembar data teknis dari pemasok suku cadang dan membuatnya dapat dicari oleh analis.
Kasus Penggunaan:Pendaftaran Alat Kesehatan
Beberapa tahun terakhir telah terlihat banyak perubahan di bidang pendaftaran produk obat elektronik. Standar ISO IDMP (Identifikasi produk medis) adalah salah satu format pesan untuk mendaftarkan produk dan zat yang terkandung di dalamnya, dengan ID Produk Obat, ID Pengemasan, dan ID Batch digunakan untuk melacak produk dalam kasus pengalaman buruk, ilegal impor, pemalsuan, dan masalah farmakovigilans lainnya. Standar tersebut meminta tidak hanya produk baru yang perlu didaftarkan, tetapi pengarsipan lama/arsip dari setiap produk yang dapat diekspos ke publik juga harus disediakan dalam bentuk elektronik.
Untuk mematuhi standar IDMP di perusahaan yang berbeda, perusahaan harus dapat menarik dan memproses data dari berbagai sumber data, seperti RDBMS serta, dalam beberapa kasus, lembar data produk lama. Meskipun sudah diketahui cara menyerap data dari RDBMS melalui teknologi seperti Apache Sqoop, pemrosesan dokumen lama memerlukan sedikit lebih banyak pekerjaan. Untuk sebagian besar, dokumen perlu diserap, dan teks yang relevan perlu diekstraksi secara terprogram dalam skala besar menggunakan teknologi OCR yang ada.
Set data
Kami akan menggunakan kumpulan data dari FDA yang berisi semua 510(k) pengajuan yang pernah diajukan oleh produsen perangkat medis sejak tahun 1976. Bagian 510(k) dari Food, Drug and Cosmetic Act mewajibkan produsen perangkat yang harus mendaftar, untuk memberi tahu FDA tentang niat mereka untuk memasarkan perangkat medis setidaknya 90 hari sebelumnya.
Dataset ini berguna untuk beberapa alasan dalam kasus ini:
- Data ini gratis dan berada dalam domain publik.
- Data tersebut sesuai dengan peraturan Eropa, yang berlaku pada Juli 2016 (di mana produsen harus mematuhi standar data baru). Tambalan FDA memiliki informasi penting yang relevan untuk mendapatkan gambaran lengkap IDMP.
- Format dokumen (PDF) memungkinkan kami untuk mendemonstrasikan teknik OCR yang sederhana namun efektif saat menangani dokumen dengan berbagai format.
Untuk mengindeks data ini secara efektif, kita perlu mengekstrak beberapa bidang dari gambar. Di bawah ini adalah contoh dokumen, dengan bidang potensial yang dapat diekstraksi.
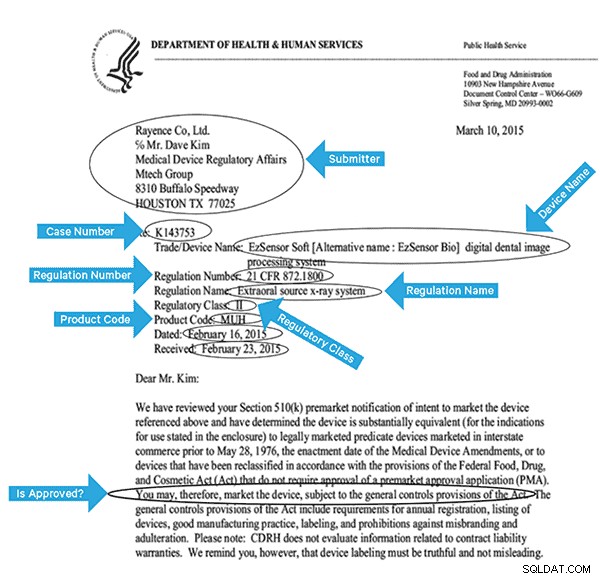
Arsitektur Tingkat Tinggi
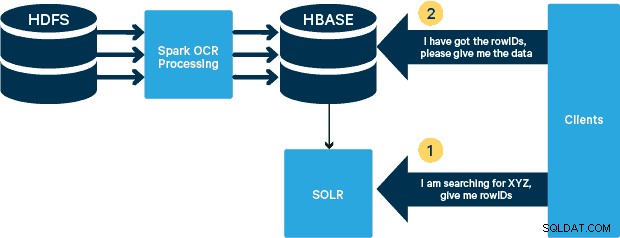
Untuk kasus penggunaan ini, PDF disimpan dalam HDFS dan diproses menggunakan pustaka Spark dan OCR. (Langkah penyerapan berada di luar cakupan postingan ini, tetapi dapat sesederhana menjalankan hdfs -dfs -put atau menggunakan antarmuka webhdfs.) Spark memungkinkan penggunaan kode yang hampir identik dalam aplikasi Spark Streaming untuk streaming yang hampir real-time, dan HBase adalah media penyimpanan yang sempurna untuk akses acak latensi rendah—dan sangat cocok untuk menyimpan gambar, dengan fungsi MOB baru, untuk boot. Cloudera Search (yang dibangun di atas Apache Solr) adalah satu-satunya solusi pencarian yang terintegrasi secara native dengan HBase, sehingga memungkinkan Anda untuk membangun indeks sekunder.
Menyiapkan Tabel Alat Kesehatan di HBase
Kami akan menjaga skema untuk kasus penggunaan kami secara langsung. RowID akan menjadi nama file, dan akan ada dua keluarga kolom:"info" dan "obj". Keluarga kolom "info" akan berisi semua bidang yang kami ekstrak dari gambar. Keluarga kolom "obj" akan menampung byte dari objek biner yang sebenarnya, dalam hal ini PDF. Nama tabel dalam kasus kami adalah “mdds.”
Kami akan memanfaatkan fungsionalitas HBase MOB (objek sedang) yang diperkenalkan di HBASE-11339. Untuk menyiapkan HBase untuk menangani MOB, diperlukan beberapa langkah tambahan, tetapi, dengan mudah, petunjuknya dapat ditemukan di tautan ini.
Ada banyak cara untuk membuat tabel di HBase secara terprogram (Java API, REST API, atau metode serupa). Di sini kita akan menggunakan shell HBase untuk membuat tabel "mdds" (sengaja menggunakan nama keluarga kolom deskriptif agar lebih mudah diikuti). Kami ingin agar keluarga kolom "info" direplikasi ke Solr, tetapi bukan data MOB.
Perintah di bawah ini akan membuat tabel dan mengaktifkan replikasi pada keluarga kolom yang disebut "info." Sangat penting untuk menentukan opsi REPLICATION_SCOPE => '1' , jika tidak, Pengindeks Lily HBase tidak akan mendapatkan pembaruan apa pun dari HBase. Kami ingin menggunakan jalur MOB di HBase untuk objek yang lebih besar dari 10MB. Untuk mencapai itu, kami juga membuat keluarga kolom lain, yang disebut "obj", menggunakan parameter berikut untuk MOB:
IS_MOB => benar, MOB_THRESHOLD => 10240000
IS_MOB parameter menentukan apakah keluarga kolom ini dapat menyimpan MOB, sementara MOB_THRESHOLD menentukan setelah seberapa besar objek harus dianggap sebagai MOB. Jadi, mari kita buat tabelnya:
buat 'mdds', {NAME => 'info', DATA_BLOCK_ENCODING => 'FAST_DIFF',REPLICATION_SCOPE => '1'},{NAME => 'obj', IS_MOB => true, MOB_THRESHOLD => 10240000}
Untuk mengonfirmasi bahwa tabel telah dibuat dengan benar, jalankan perintah berikut di shell HBase:
hbase(main):001:0> deskripsikan 'mdds'Table mdds is ENABLEDmddsCOLUMN FAMILIES DESCRIPTION{NAME => 'info', DATA_BLOCK_ENCODING => 'FAST_DIFF', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '1' , VERSI => '1', KOMPRESI => 'TIDAK ADA', MIN_VERSIONS => '0', TTL => 'SELAMANYA', KEEP_DELETED_CELLS => 'SALAH', BLOCKSIZE => '65536', IN_MEMORY => 'salah', BLOCKCACHE => 'benar'}{NAME => 'obj', DATA_BLOCK_ENCODING => 'TIDAK ADA', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', KOMPRESI => 'TIDAK ADA', VERSI => '1', MIN_VERSIONS => '0', TTL => 'SELAMANYA', MOB_THRESHOLD => '10240000', IS_MOB => 'benar', KEEP_DELETED_CELLS => 'SALAH', BLOCKSIZE => '65536', IN_MEMORY => 'salah', BLOCKCACHE => 'true'}2 baris dalam 0,3440 detik Memproses Gambar yang Dipindai dengan Tesseract
OCR telah berkembang jauh dalam hal menangani variasi font, noise gambar, dan masalah perataan. Di sini kita akan menggunakan mesin OCR open source Tesseract, yang awalnya dikembangkan sebagai perangkat lunak berpemilik di lab HP. Pengembangan Tesseract telah dirilis sebagai perangkat lunak sumber terbuka dan disponsori oleh Google sejak 2006.
Tesseract adalah perpustakaan perangkat lunak yang sangat portabel. Ini menggunakan perpustakaan pemrosesan gambar Leptonica untuk menghasilkan gambar biner dengan melakukan ambang batas adaptif pada gambar abu-abu atau berwarna.
Pemrosesan mengikuti jalur pipa langkah-demi-langkah tradisional. Berikut adalah alur kasar langkah-langkahnya:
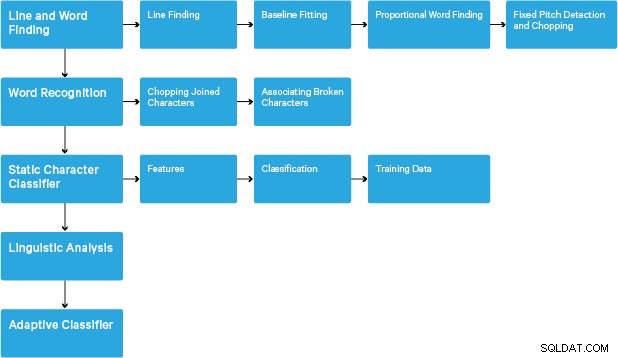
Pemrosesan dimulai dengan analisis komponen yang terhubung, yang menghasilkan penyimpanan komponen yang ditemukan. Langkah ini membantu dalam pemeriksaan garis besar bersarang, dan jumlah garis anak dan cucu.
Pada tahap ini, garis besar dikumpulkan bersama, murni dengan bersarang, ke dalam Binary Large Objects (BLOBs). Gumpalan diatur ke dalam baris teks, dan garis serta wilayah dianalisis untuk nada tetap atau teks proporsional. Baris teks dipecah menjadi kata-kata secara berbeda sesuai dengan jenis spasi karakter. Teks nada tetap dipotong segera oleh sel karakter. Teks proporsional dipecah menjadi kata-kata menggunakan spasi pasti dan spasi kabur.
Pengakuan kemudian berlanjut sebagai proses dua kali. Pada lintasan pertama, upaya dilakukan untuk mengenali setiap kata secara bergantian. Setiap kata yang memuaskan dilewatkan ke pengklasifikasi adaptif sebagai data pelatihan. Pengklasifikasi adaptif kemudian mendapat kesempatan untuk lebih akurat mengenali teks di bagian bawah halaman. Karena pengklasifikasi adaptif mungkin terlambat mempelajari sesuatu yang berguna untuk membuat kontribusi di dekat bagian atas halaman, lintasan kedua dijalankan di atas halaman, di mana kata-kata yang tidak cukup dikenal dikenali lagi. Fase terakhir menyelesaikan ruang fuzzy, dan memeriksa hipotesis alternatif untuk tinggi-x untuk menemukan teks huruf kecil.
Tesseract dalam bentuknya saat ini sepenuhnya mampu unicode dan terlatih untuk beberapa bahasa. Berdasarkan penelitian kami, ini adalah salah satu perpustakaan open source paling akurat yang tersedia untuk OCR. Seperti disebutkan sebelumnya, Tesseract menggunakan Leptonica. Kami juga menggunakan Ghostscript untuk membagi file PDF menjadi gambar. (Anda dapat membaginya ke dalam format kompresi gambar pilihan Anda; kami memilih PNG.) Ketiga library ini ditulis dalam C++, dan untuk memanggilnya dari program Java/Scala, kita perlu menggunakan implementasi Java Native Interface yang sesuai. Dalam pekerjaan kami, kami menggunakan binding JNI dari JavaPresets. (Petunjuk pembuatan dapat ditemukan di bawah.) Kami menggunakan Scala untuk menulis driver Spark.
val renderer :SimpleRenderer =baru SimpleRenderer( )renderer.setResolution( 300 )val images:List[Image] =renderer.render( document )
Leptonica membaca dalam gambar terpisah dari langkah sebelumnya.
ImageIO.write( x.asInstanceOf[RenderedImage], "png", imageByteStream)val pix:PIX =pixReadMem ( ByteBuffer.wrap( imageByteStream.toByteArray() ).array() , ByteBuffer.wrap( imageByteStream.toByteArray( ) ).kapasitas())
Kami kemudian menggunakan panggilan API Tesseract untuk mengekstrak teks. Kami menganggap dokumen dalam bahasa Inggris di sini, maka parameter kedua untuk metode Init adalah “eng.”
val api:TessBaseAPI =new TessBaseAPI( )api.Init( null, "eng" )api.SetImage(pix)api.GetUTF8Text().getString()
Setelah gambar diproses, kami mengekstrak beberapa bidang dari teks dan mengirimkannya ke HBase.
def populateHbase ( fileName:String, lines:String, pdf:org.apache.spark.input.PortableDataStream) :Unit ={ /** Konfigurasi dan buka koneksi HBase */ val mddsTbl =_conn.getTable( TableName. nilaiDari("mdds" )); val cf ="info" val put =new Put( Bytes.toBytes( fileName )) /** * Ekstrak Fields di sini menggunakan Regex * Buat objek Put dan kirim ke HBase */ val aAndCP ="""(?s)(? m).*\d\d\d\d\d-\d\d\d\d(.*)\nRe:(\w\d\d\d\d\d\d).*"" ".r …….. baris cocok { case aAndCP( addr, casenum ) => put.add( Bytes.toBytes( cf ),Bytes.toBytes( "submitter_info" ),Bytes.toBytes( addr ) ).add( Bytes .toBytes( cf ),Bytes.toBytes( "case_num" ), Bytes.toBytes( casenum )) case _ => println( "tidak cocok dengan regex" ) } ……. lines.split("\n").foreach { val regNumRegex ="""Nomor Regulasi:\s+(.+)""".r val regNameRegex ="""Nama Regulasi:\s+(.+)""" .r …….. ……. _ cocokkan { case regNumRegex( regNum ) => put.add( Bytes.toBytes( cf ),Bytes.toBytes( "reg_num" ), ……. ….. case _ => print( "" ) } } put.add ( Bytes.toBytes( cf ), Bytes.toBytes( "teks" ), Bytes.toBytes( baris )) val pdfBytes =pdf.toArray.clone put.add(Bytes.toBytes( "obj" ), Bytes.toBytes( " pdf" ), pdfBytes ) mddsTbl.put( put ) …….}
Jika Anda melihat lebih dekat ke kode di atas, tepat sebelum kami mengirim objek Put ke HBase, kami memasukkan byte PDF mentah ke dalam keluarga kolom "obj" dari tabel. Kami menggunakan HBase sebagai lapisan penyimpanan untuk bidang yang diekstraksi serta gambar mentah. Ini membuatnya cepat dan nyaman bagi aplikasi untuk mengekstrak gambar asli, jika perlu. Kode lengkapnya dapat ditemukan di sini. (Perlu dicatat bahwa meskipun kami menggunakan API HBase standar untuk membuat objek Put untuk HBase, dalam sistem produksi nyata, sebaiknya pertimbangkan untuk menggunakan API SparkOnHBase, yang memungkinkan pembaruan batch ke HBase dari Spark RDD.)
Jalur Eksekusi
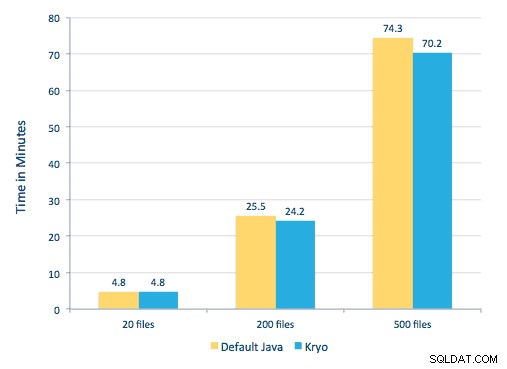
Kami dapat memproses setiap PDF dalam kerangka serial. Untuk menskalakan pemrosesan, kami memilih untuk memproses PDF ini secara terdistribusi menggunakan Spark. Bagan berikut menunjukkan bagaimana kami menggabungkan berbagai tahapan pemrosesan ini untuk mengubah alur kerja menjadi panggilan makro sederhana dari Spark dan memuat data ke HBase.
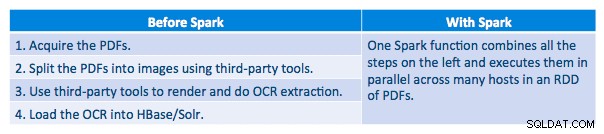
Kami juga mencoba melakukan perbandingan antara metode serialisasi, tetapi dengan dataset kami, kami tidak melihat perbedaan kinerja yang signifikan.
Pengaturan Lingkungan
Perangkat keras yang digunakan:Cluster lima simpul dengan memori 15 GB, 4 vCPU, dan SSD 2x40 GB
Karena kami menggunakan library C++ untuk pemrosesan, kami menggunakan binding JNI yang dapat ditemukan di sini.
Buat binding JNI untuk Tesseract dan Leptonica dari preset javaCPP:
-
- Pada semua node:
yum -y install automake autoconf libtool zlib-devel libjpeg-devel giflib libtiff-devel libwebp libwebp-devel libicu-devel openjpeg-devel cairo-devel
git clone https://github.com/bytedeco/javacpp-presets.git cd javacpp-presets - Build Leptonica.
cd leptonica./cppbuild.sh install leptonicacd cppbuild/linux-x86_64/leptonica-1.72/LDFLAGS="-Wl,-rpath -Wl,/usr/local/lib" ./configuremake &&sudo make installcd ../../../mvn clean installcd ..
- Bangun Tesseract.
cd tesseract./cppbuild.sh install tesseractcd tesseract/cppbuild/linux-x86_64/tesseract-3.03LDFLAGS="-Wl,-rpath -Wl,/usr/local/lib" ./configuremake &&make installcd ../ ../../mvn clean installcd ..
- Buat preset javaCPP.
mvn clean install --projects leptonica,tesseract
Kami menggunakan Ghostscript untuk mengekstrak gambar dari PDF. Petunjuk untuk membuat Ghostscript, sesuai dengan versi Tesseract dan Leptonica yang digunakan di sini, adalah sebagai berikut. (Pastikan Ghostscript tidak diinstal di sistem melalui manajer paket.)
wget https://downloads.ghostscript.com/public/ghostscript-9.16.tar.gztar zxvf ghostscript-9.16.tar.gzcd ghostscript-9.16./autogen.sh &&./configure --prefix=/usr - -disable-compile-inits --enable-dynamicsudo make &&make soinstall &&install -v -m644 base/*.h /usr/include/ghostscript &&ln -v -s ghostscript /usr/include/ps(Tergantung pada ldpath Anda pengaturan, Anda mungkin harus melakukan):sudo ln -sf /usr/lib/libgs.so /usr/local/lib/libgs.so
Pastikan semua library yang dibutuhkan ada di classpath. Kami meletakkan semua toples yang relevan di direktori bernama lib. Koma penting di bawah ini:
$ untuk saya di `ls lib/*`; lakukan ekspor MY_JARS=./$i,$MY_JARS; donetesseract.jar, tesseract-linux-x86_64.jar, javacpp.jar, ghost4j-1.0.0.jar, leptonica.jar, leptonica-1.72-1.0.jar, leptonica-linux-x86_64.jar
Kami memanggil program Spark sebagai berikut. Kita perlu menentukan extraLibraryPath untuk pustaka Ghostscript asli; conf lain diperlukan untuk Tesseract.
spark-submit --jars $MY_JARS --num-executors 12 --executor-memory 4G --executor-cores 1 --conf spark.executor.extraLibraryPath=/usr/local/lib --confspark.executorEnv. TESSDATA_PREFIX=/home/vsingh/javacpp-presets/tesseract/cppbuild/1-x86_64/share/tessdata/ --confspark.executor.extraClassPath=/etc/hbase/conf:/opt/cloudera/parcels/CDH/lib/hbase /lib/htrace-core-3.1.0-incubating.jar --driver-class-path/etc/hbase/conf:/opt/cloudera/parcels/CDH/lib/hbase/lib/htrace-core-3.1.0 -incubating.jar --conf spark.serializer=org.apache.spark.serializer.KryoSerializer--conf spark.kryoserializer.buffer.mb=24 --class com.cloudera.sa.OCR.IdmpExtraction
Membuat Koleksi Solr
Solr terintegrasi cukup mulus dengan HBase melalui Lily HBase Indexer. Untuk memahami bagaimana integrasi integrasi Lily Indexer dengan HBase dilakukan, Anda dapat memoles melalui posting kami sebelumnya di bagian “Memahami Replikasi HBase dan Lily HBase Indexer”.
Di bawah ini kami menguraikan langkah-langkah yang perlu dilakukan untuk membuat indeks:
- Buat contoh file konfigurasi schema.xml:
solrctl --zk localhost:2181 instancedir --generate $HOME/solrcfg
- Edit file schema.xml di
$HOME/solrcfg , menentukan bidang yang kita butuhkan untuk koleksi kita. File lengkapnya dapat ditemukan di sini.
- Unggah konfigurasi Solr ke ZooKeeper:
solrctl --zk localhost:2181/solr instancedir --create mdds_collection $HOME/solrcfg
- Buat koleksi Solr dengan 2 pecahan (-s 2) dan 2 replika (-r 2):
solrctl --zk localhost:2181/solr --solr localhost:8983/solr collection --create mdds_collection -s 2 -r 2
Pada perintah di atas kami membuat koleksi Solr dengan dua parameter pecahan (-s 2) dan dua replika (-r 2). Parameternya cukup untuk corpus kami, tetapi dalam penerapan yang sebenarnya, seseorang harus menetapkan nomor berdasarkan pertimbangan lain di luar cakupan diskusi kami di sini.
Mendaftarkan Pengindeks
Langkah ini diperlukan untuk menambah dan mengkonfigurasi pengindeks dan replikasi HBase. Perintah di bawah ini akan memperbarui ZooKeeper dan menambahkan mdds_indexer sebagai rekan replikasi untuk HBase. Itu juga akan memasukkan konfigurasi ke ZooKeeper, yang akan digunakan Lily HBase Indexer untuk menunjuk ke koleksi yang tepat di Solr. |
hbase-indexer add-indexer -n mdds_indexer -c indexer-config.xml -cp solr.zk=localhost:2181/solr -cp solr.collection=mdds_collection.
Argumen:
-n mdds_indexer– menentukan nama pengindeks yang akan didaftarkan di ZooKeeper-c indexer-config.xml– file konfigurasi yang akan menentukan perilaku pengindeks-cp solr.zk=localhost:2181/solr– menentukan lokasi konfigurasi ZooKeeper dan Solr. Ini harus diperbarui dengan lokasi khusus lingkungan ZooKeeper.-cp solr.collection=mdds_collection– menentukan koleksi mana yang akan diperbarui. Ingat langkah Konfigurasi Solr tempat kita membuat koleksi1.
index-config.xml file relatif mudah dalam kasus ini; yang dilakukannya hanyalah menentukan kepada pengindeks tabel mana yang akan dilihat, kelas yang akan digunakan sebagai mapper (com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper ), dan lokasi file konfigurasi Morphline. Secara default, tipe pemetaan diatur ke baris , dalam hal ini dokumen Solr menjadi baris penuh. Param name="morphlineFile" menentukan lokasi file konfigurasi Morphlines. Lokasi bisa menjadi jalur absolut dari file Morphlines Anda, tetapi karena Anda menggunakan Cloudera Manager, tentukan jalur relatif sebagai morphlines.conf.
Isi dari file konfigurasi hbase-indexer dapat ditemukan di sini.
Mengonfigurasi dan Memulai Pengindeks Lily HBase
Saat Anda mengaktifkan Lily HBase Indexer, Anda perlu menentukan logika transformasi Morphlines yang akan memungkinkan pengindeks ini untuk mengurai pembaruan ke tabel Perangkat Medis dan mengekstrak semua bidang yang relevan. Buka Layanan dan pilih Lily HBase Indexer yang Anda tambahkan sebelumnya. Pilih Konfigurasi->Lihat dan Edit->Lebar-Layanan->Morphlines . Salin dan tempel file Morphlines.
Pustaka morphlines perangkat medis akan melakukan tindakan berikut:
- Baca acara email HBase dengan
extractHBaseCellsperintah- Konversi tanggal/stempel waktu menjadi bidang yang akan dipahami Solr, dengan
convertTimestampperintah- Lepaskan semua bidang tambahan yang tidak kami tentukan di schema.xml, dengan
sanitizeUknownSolrFieldsperintahUnduh salinan file Morphlines ini dari sini.
Satu catatan penting adalah bahwa bidang id akan dibuat secara otomatis oleh Lily HBase Indexer. Pengaturan tersebut dapat dikonfigurasi dalam file index-config.xml di atas dengan menentukan atribut unique-key-field. Ini adalah praktik terbaik untuk membiarkan nama default id—karena tidak ditentukan dalam file xml di atas, bidang id default dibuat dan akan menjadi kombinasi RowID.
Mengakses Data
Anda memiliki banyak pilihan alat visual untuk mengakses gambar yang diindeks. HUE dan Solr GUI keduanya merupakan opsi yang sangat bagus. HBase juga memungkinkan sejumlah teknik akses, tidak hanya dari GUI tetapi juga melalui shell HBase, API, dan bahkan teknik skrip sederhana.
Integrasi dengan Solr memberi Anda fleksibilitas luar biasa dan juga dapat memberikan opsi pencarian yang sangat sederhana serta lanjutan untuk data Anda. Misalnya, mengonfigurasi file skema.xml Solr sedemikian rupa sehingga semua bidang dalam objek email disimpan di Solr memungkinkan pengguna untuk mengakses isi pesan lengkap melalui pencarian sederhana, dengan pertukaran ruang penyimpanan dan kompleksitas komputasi. Atau, Anda dapat mengonfigurasi Solr untuk menyimpan hanya sejumlah bidang, seperti id. Dengan elemen ini, pengguna dapat dengan cepat mencari Solr dan mengambil rowID yang pada gilirannya dapat digunakan untuk mengambil masing-masing bidang atau seluruh gambar dari HBase itu sendiri.
Contoh di atas hanya menyimpan rowID di Solr tetapi mengindeks pada semua bidang yang diekstraksi dari gambar. Mencari Solr dalam skenario ini mengambil ID baris HBase, yang kemudian dapat Anda gunakan untuk menanyakan HBase. Jenis penyiapan ini ideal untuk Solr karena menghemat biaya penyimpanan dan memanfaatkan sepenuhnya kemampuan pengindeksan Solr.
Contoh Kueri
Di bawah ini adalah beberapa contoh query yang dapat dilakukan dari aplikasi ke dalam Solr. Idenya adalah bahwa klien awalnya akan menanyakan indeks Solr, mengembalikan rowID dari HBase. Kemudian kueri HBase untuk bidang lainnya dan/atau gambar mentah asli.
- Beri saya semua dokumen yang diajukan antara tanggal berikut:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=received:[2010-01 -06T23:59:59.999Z SAMPAI 02-06T23:59:59.999Z]
- Beri saya dokumen yang diajukan di bawah nama peraturan sistem x-ray Seluler:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=reg_name:Mobile sistem sinar-x
- Beri saya semua dokumen yang diajukan dari pabrikan China:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=submitter_info:*China*
Id dari dokumen Solr adalah ID baris di HBase; bagian kedua dari kueri adalah ke HBase untuk mengekstrak data (termasuk PDF mentah jika diperlukan).
Akses melalui HUE
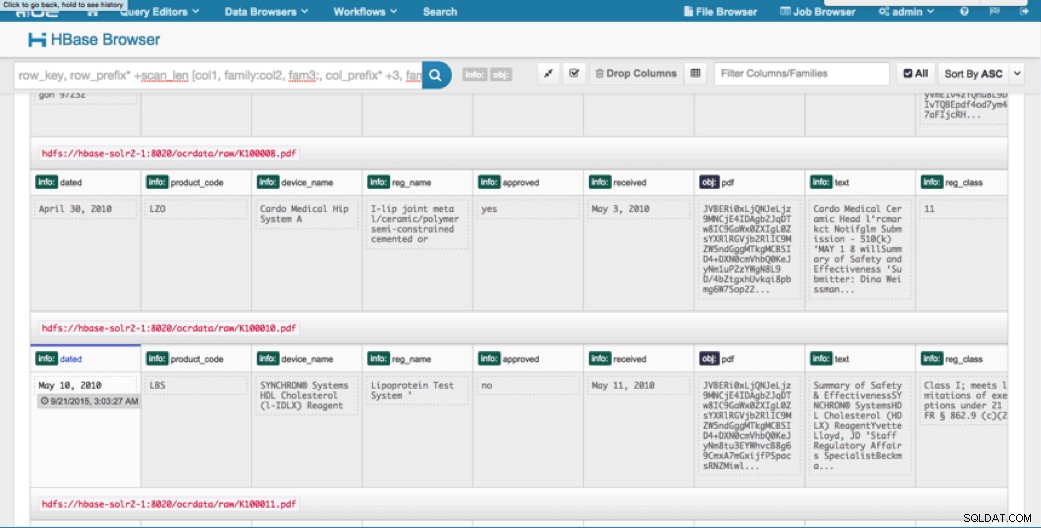
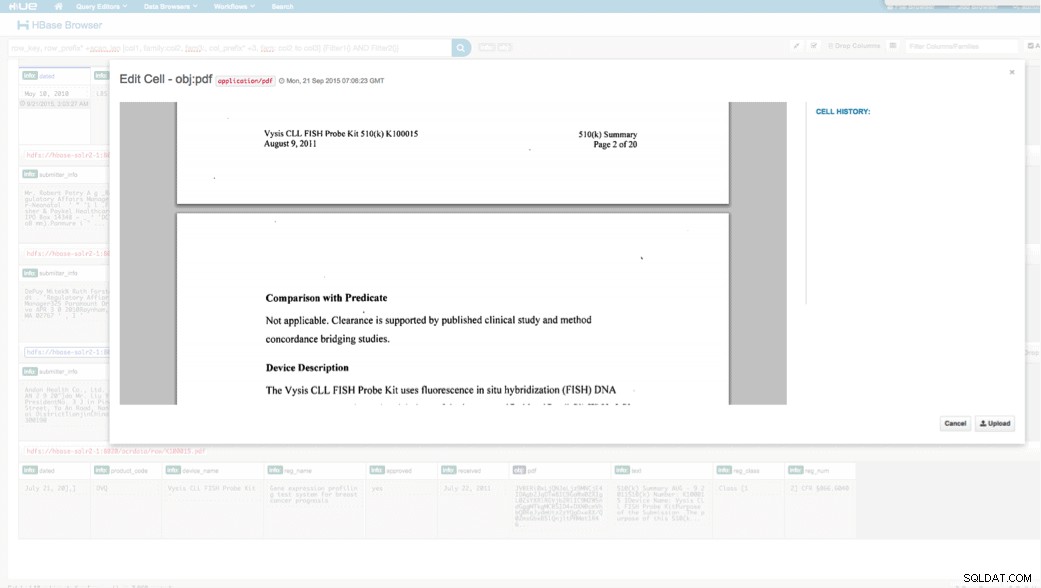
Kami dapat melihat data yang diunggah melalui Browser HBase di HUE. Satu hal hebat tentang HUE adalah dapat mendeteksi biner untuk PDF dan merendernya saat diklik.
Di bawah ini adalah cuplikan tampilan bidang yang diurai dalam baris HBase dan juga tampilan yang dirender dari salah satu objek PDF yang disimpan sebagai MOB dalam keluarga kolom obj.
Kesimpulan
Dalam posting ini, kami telah menunjukkan cara menggunakan teknologi open source standar untuk melakukan OCR pada dokumen yang dipindai menggunakan program Spark yang dapat diskalakan, menyimpan ke HBase untuk pengambilan cepat, dan mengindeks informasi yang diekstraksi di Solr. Harus jelas bahwa:
- Mengingat format spesifikasi pesan, kita dapat mengekstrak bidang dan pasangan nilai dan membuatnya dapat dicari melalui Solr.
- Bidang dari data ini dapat memenuhi persyaratan IDMP untuk membuat data lama menjadi elektronik, yang mulai berlaku sekitar tahun depan.
- Bidang serta gambar mentah dapat dipertahankan di HBase dan diakses melalui API standar.
Jika Anda merasa perlu memproses dokumen yang dipindai dan menggabungkan data dengan berbagai sumber lain di perusahaan Anda, pertimbangkan untuk menggunakan kombinasi Spark, HBase, Solr, bersama dengan Tesseract dan Leptonica. Ini dapat menghemat banyak waktu dan uang Anda!
Jeff Shmain adalah Arsitek Solusi Senior di Cloudera. Dia memiliki 16+ tahun pengalaman industri keuangan dengan pemahaman yang kuat tentang perdagangan keamanan, risiko, dan peraturan. Selama beberapa tahun terakhir, ia telah mengerjakan berbagai implementasi kasus penggunaan di 8 dari 10 bank investasi terbesar di dunia.
Vartika Singh adalah Konsultan Solusi Senior di Cloudera. Dia memiliki lebih dari 12 tahun pengalaman dalam pembelajaran mesin terapan dan pengembangan perangkat lunak.



