Replikasi MariaDB adalah salah satu solusi ketersediaan tinggi paling populer untuk MariaDB dan banyak digunakan oleh perusahaan top seperti Booking.com dan Google. Sangat mudah untuk mengatur, dengan beberapa trade-off pada pemeliharaan berkelanjutan seperti upgrade perangkat lunak, perubahan skema, perubahan topologi, failover dan pemulihan yang selalu rumit. Namun demikian, dengan perangkat yang tepat, Anda seharusnya dapat menangani topologi dengan mudah. Dalam posting blog ini, kita akan melihat beberapa tips untuk memantau replikasi MariaDB secara efisien menggunakan ClusterControl.
Menggunakan Penampil Topologi
Pengaturan replikasi terdiri dari sejumlah peran. Sebuah node dalam setup replikasi dapat berupa:
- Master - Penulis/pembaca utama.
- Backup master - Sebuah slave hanya-baca dengan replikasi semi-sinkronisasi, hanya untuk redundansi master.
- Master perantara - Replikasi dari master, sementara slave lain mereplikasi dari node ini.
- Server Binlog - Hanya mengumpulkan/menyimpan binlog tanpa menyajikan data.
- Slave - Replikasi dari master, dan biasanya disetel sebagai hanya-baca.
- Budak multi-sumber - Replikasi dari beberapa master.
Setiap peran memiliki tanggung jawab dan batasannya sendiri dan seseorang harus memahami topologi yang benar ketika berhadapan dengan node database. Ini juga berlaku untuk aplikasi, di mana aplikasi harus menulis hanya ke node master pada waktu tertentu. Oleh karena itu, penting untuk memiliki ikhtisar tentang node mana yang memegang peran yang mana, sehingga kami tidak mengacaukan database kami.
Di ClusterControl, Topology Viewer dapat memberi Anda gambaran umum tentang topologi replikasi dan statusnya, seperti yang ditunjukkan pada tangkapan layar berikut:
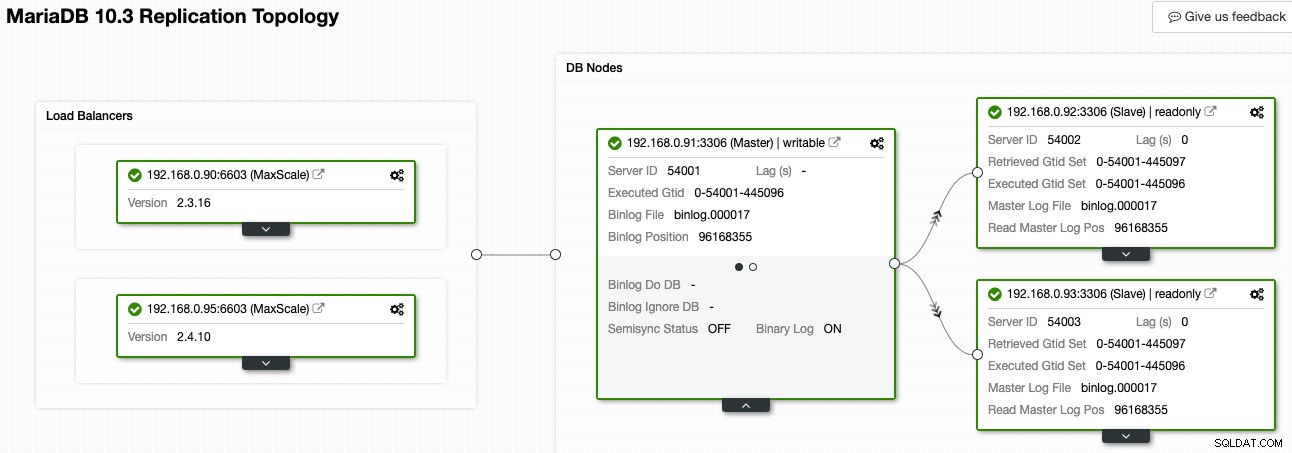
ClusterControl memahami replikasi MariaDB dan mampu memvisualisasikan topologi dengan aliran data replikasi yang benar, seperti yang ditunjukkan oleh panah yang menunjuk ke node slave. Kami dapat dengan mudah membedakan node mana yang merupakan master, slave, dan load balancer (MaxScale) dalam pengaturan replikasi kami. Kotak hijau menunjukkan semua layanan penting berjalan seperti yang diharapkan dengan peran yang ditetapkan.
Pertimbangkan tangkapan layar berikut di mana sejumlah node kami mengalami masalah:
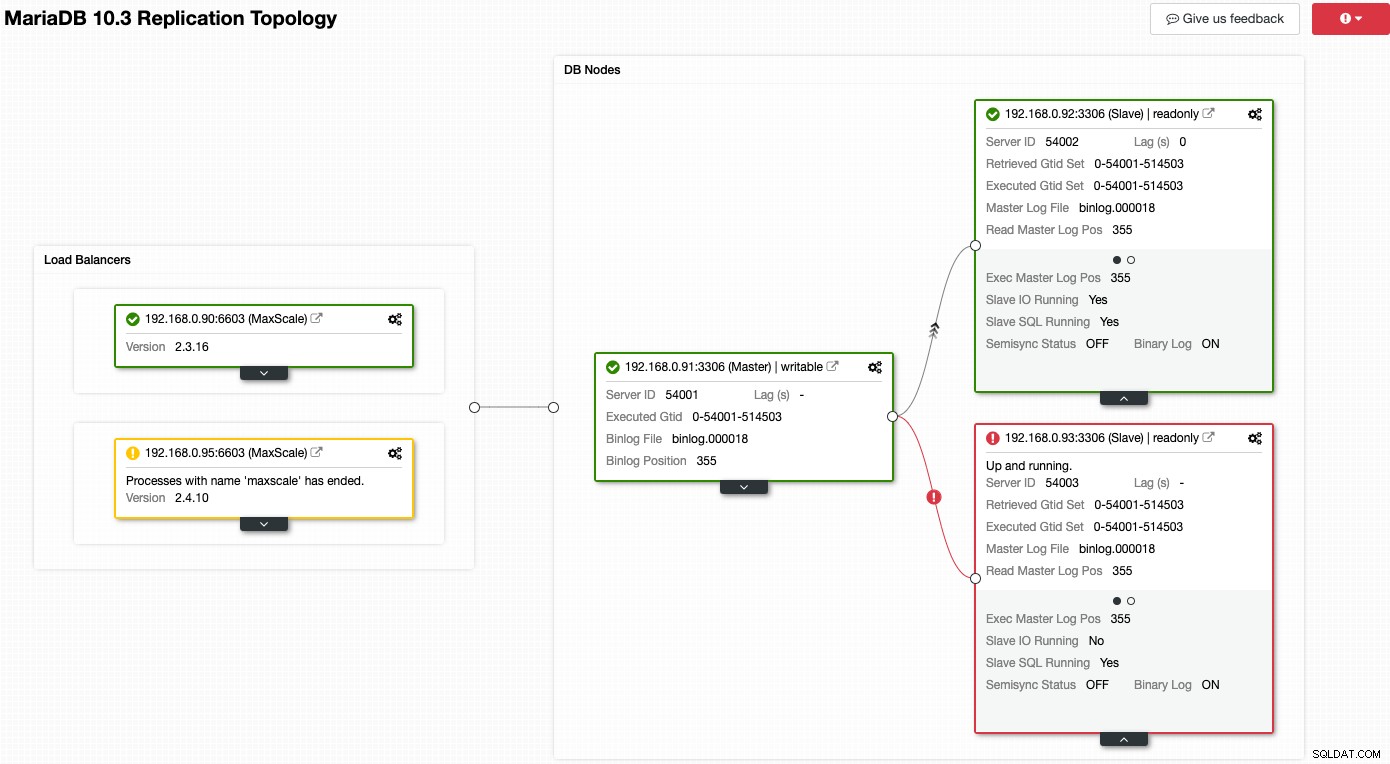
ClusterControl akan segera memberi tahu Anda apa yang salah dengan topologi saat ini. Salah satu budak (kotak merah) menunjukkan "Slave IO Running" sebagai Tidak, untuk menunjukkan beberapa masalah konektivitas untuk direplikasi dari master. Sedangkan kotak kuning menunjukkan layanan MaxScale kami tidak berjalan. Kami juga dapat memberi tahu bahwa versi MaxScale tidak identik untuk kedua node. Anda juga dapat melakukan tugas manajemen dengan mengeklik ikon roda gigi (kanan atas di setiap kotak) secara langsung untuk mengurangi risiko mengambil simpul yang salah.
Keterlambatan Replikasi
Ini adalah hal terpenting jika Anda mengandalkan konsistensi replikasi data. Replikasi lag terjadi ketika budak tidak dapat mengikuti pembaruan yang terjadi pada master. Perubahan yang belum diterapkan terakumulasi dalam log relai slave dan versi database pada slave menjadi semakin berbeda dari master.
Di ClusterControl, Anda dapat menemukan histogram jeda replikasi di bawah Tinjauan -> Lag Replikasi di mana ClusterControl terus-menerus mengambil sampel nilai Seconds_Behind_Master dari output "SHOW SLAVE STATUS":
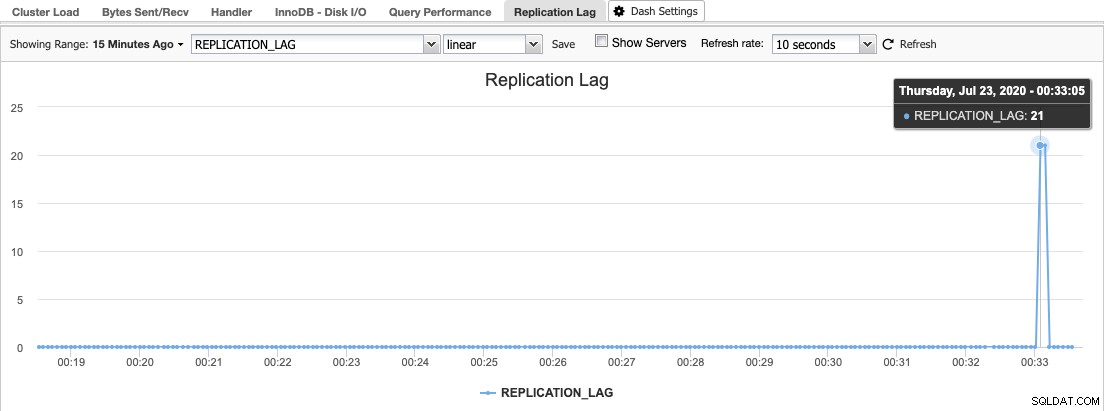
Replikasi lag terjadi ketika I/O Thread atau SQL Thread tidak dapat mengatasi tuntutan yang diberikan padanya. Jika I/O Thread bermasalah, ini berarti koneksi jaringan antara master dan slave lambat atau mengalami masalah. Anda mungkin ingin mempertimbangkan untuk mengaktifkan slave_compressed_protocol untuk mengompresi lalu lintas jaringan atau melaporkan ke administrator jaringan Anda.
Jika itu adalah utas SQL maka masalahnya mungkin karena kueri yang dioptimalkan dengan buruk yang membutuhkan waktu terlalu lama untuk diterapkan. Mungkin ada transaksi yang berjalan lama atau terlalu banyak aktivitas I/O. Tidak adanya kunci utama pada tabel slave saat menggunakan format replikasi ROW atau CAMPURAN juga merupakan penyebab umum kelambatan pada utas ini. Periksa apakah tabel versi master dan slave memiliki kunci utama.
Beberapa tips dan trik lainnya dibahas dalam posting blog ini, Cara Mengurangi Replikasi Lag dalam Penerapan Multi-Cloud.
Ukuran Log Biner/Relai
Sangat penting untuk memantau ukuran disk log biner dan relai karena dapat menghabiskan banyak penyimpanan di setiap node dalam cluster replikasi. Biasanya, seseorang akan menyetel variabel sistem expired_logs_days ke kedaluwarsa file log biner secara otomatis setelah beberapa hari, misalnya, expired_logs_days=7. Ukuran log biner sepenuhnya bergantung pada jumlah peristiwa biner yang dibuat (penulisan masuk) dan sedikit yang kita ketahui berapa banyak ruang disk yang akan digunakan sebelum log akan kedaluwarsa oleh MariaDB. Perlu diingat jika Anda mengaktifkan log_slave_updates pada slave, ukuran log akan hampir dua kali lipat karena keberadaan log biner dan relai pada server yang sama.
Untuk ClusterControl, kita dapat mengatur ambang batas pemanfaatan ruang disk di bawah ClusterControl -> Settings -> Thresholds untuk mendapatkan peringatan dan pemberitahuan penting seperti di bawah ini:
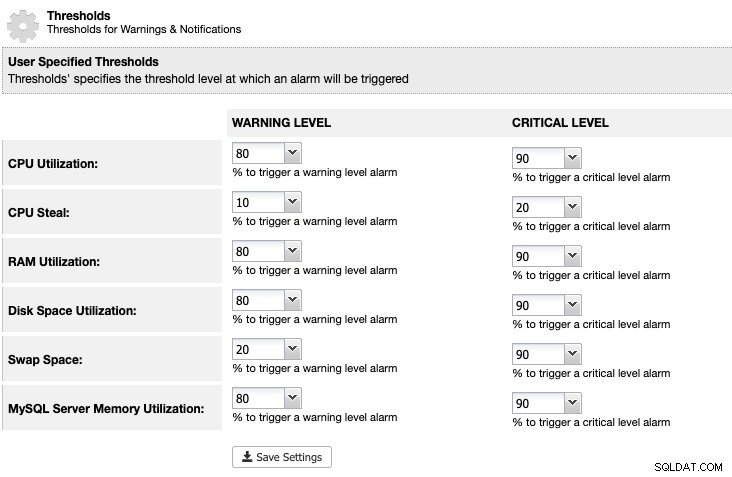
ClusterControl memantau semua ruang disk yang terkait dengan layanan MariaDB seperti lokasi data MariaDB direktori, direktori log biner dan juga partisi root. Jika Anda telah mencapai ambang batas, pertimbangkan untuk membersihkan log biner secara manual dengan menggunakan perintah PURGE BINARY LOGS, seperti yang dijelaskan dan dibahas dalam artikel ini.
Aktifkan Dasbor Pemantauan
ClusterControl menyediakan dua opsi pemantauan untuk mengambil sampel node database - tanpa agen atau berbasis agen. Standarnya adalah tanpa agen di mana pengambilan sampel terjadi melalui SSH dalam mekanisme pull-only. Pemantauan berbasis agen memerlukan server Prometheus untuk berjalan, dan semua node yang dipantau harus dikonfigurasi dengan setidaknya tiga eksportir:
- Pengekspor proses (port 9011)
- Pengekspor metrik node/sistem (port 9100)
- Pengekspor MySQL/MariaDB (port 9104)
Untuk mengaktifkan dasbor pemantauan berbasis agen, seseorang harus pergi ke ClusterControl -> Dasbor -> Aktifkan Pemantauan Berbasis Agen. Setelah diaktifkan, Anda akan melihat satu set dasbor yang dikonfigurasi untuk replikasi MariaDB kami yang memberi kami wawasan yang jauh lebih baik tentang penyiapan replikasi kami. Tangkapan layar berikut menunjukkan apa yang akan Anda lihat untuk node master:
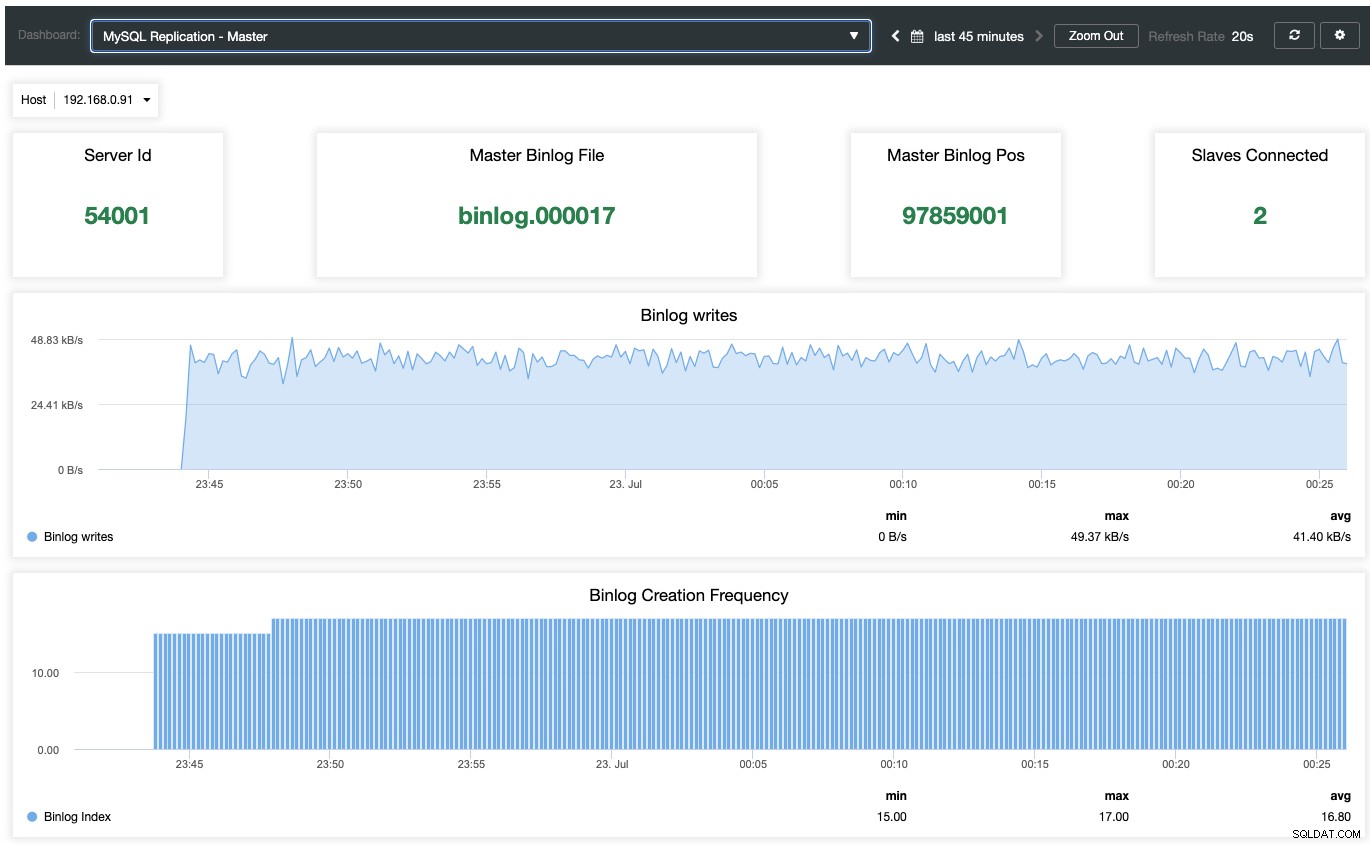
Selain dari dasbor pemantauan standar MariaDB seperti metrik umum, cache, dan InnoDB, Anda akan disajikan dengan dasbor replikasi. Untuk node master, kita bisa mendapatkan banyak informasi berguna mengenai status master, throughput tulis, dan frekuensi pembuatan binlog.
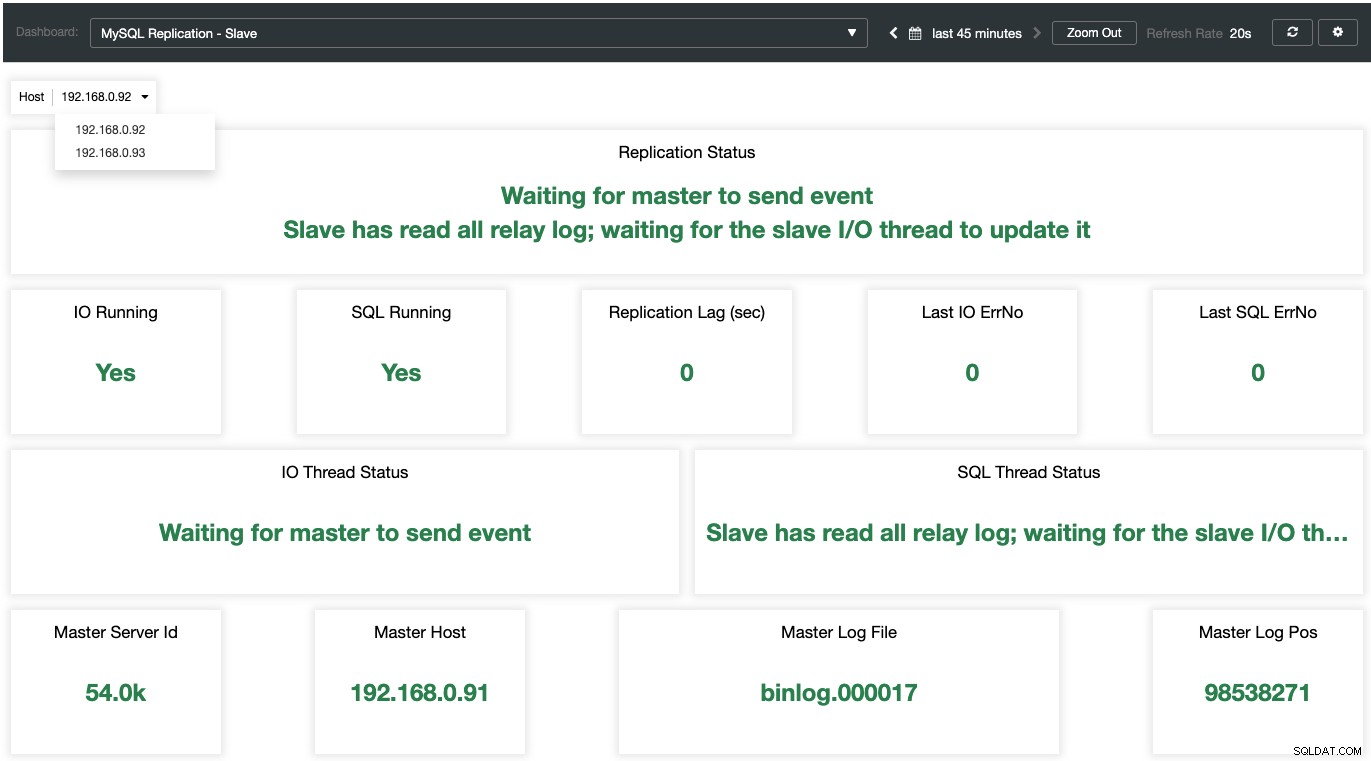
Sementara untuk budak, semua status penting diambil sampelnya dan diringkas sebagai tangkapan layar berikut. jika semuanya berwarna hijau, Anda berada di tangan yang tepat:
Memahami Log Kesalahan MariaDB
MariaDB mencatat peristiwa penting di dalam log kesalahan, yang berguna untuk memahami apa yang terjadi dengan server, terutama sebelum, selama, dan setelah perubahan topologi. ClusterControl menyediakan tampilan log kesalahan terpusat di bawah ClusterControl -> Logs -> System Logs dengan menariknya dari setiap node database. Anda mengklik "Refresh Logs" untuk memicu pekerjaan untuk menarik log terbaru dari server.
File yang dikumpulkan direpresentasikan dalam struktur pohon navigasi dan area teks dengan penyorotan sintaks untuk keterbacaan yang lebih baik:
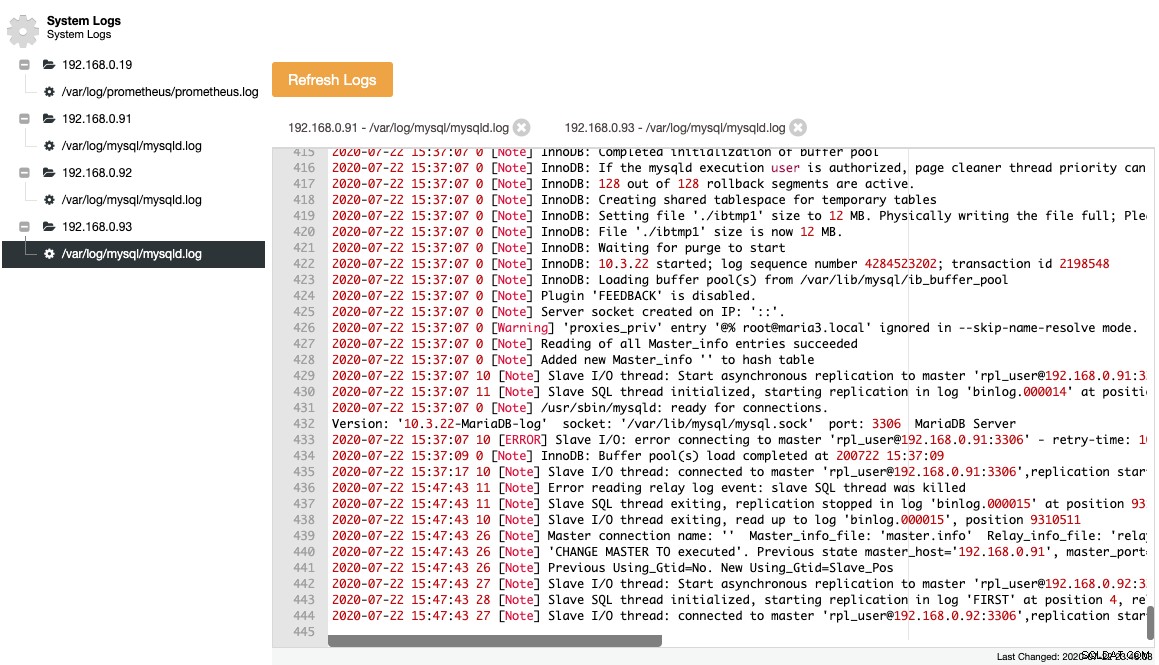
Dari tangkapan layar di atas, kita dapat memahami urutan peristiwa dan apa yang terjadi pada simpul ini selama peristiwa perubahan topologi. Dari 12 baris terakhir dari log kesalahan di atas, budak mengalami kesalahan setelah terhubung ke master dan file log biner terakhir dan posisi dicatat dalam log sebelum berhenti. Kemudian perintah CHANGE MASTER yang lebih baru dijalankan dengan informasi GTID, seperti yang ditunjukkan pada baris "Previous Using_Gtid=No. New Using_Gtid=Slave_Pos" dan kemudian replikasi dilanjutkan seperti yang kita inginkan.
Peringatan dan Pemberitahuan MariaDB
Pemantauan tidak lengkap tanpa peringatan dan pemberitahuan. Semua acara dan alarm yang dihasilkan oleh ClusterControl dapat dikirim ke email atau alat pihak ketiga lainnya yang didukung. Untuk pemberitahuan email, seseorang dapat mengonfigurasi apakah jenis acara akan segera dikirim, diabaikan, atau dicerna (laporan rangkuman harian):

Untuk semua peristiwa tingkat keparahan kritis, disarankan untuk menyetel semuanya ke "Kirim" sehingga Anda akan mendapatkan notifikasi sesegera mungkin. Setel "Intisari" ke peristiwa peringatan sehingga Anda mengetahui kesehatan dan status cluster.
Anda dapat mengintegrasikan alat komunikasi dan pesan pilihan Anda dengan ClusterControl dengan menggunakan fitur Manajemen Pemberitahuan di bawah ClusterControl -> Integrasi -> Pemberitahuan Pihak ke-3. ClusterControl dapat mengirim alarm dan acara ke PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow, atau webhook terdaftar pengguna mana pun.
Tangkapan layar berikut menunjukkan semua peristiwa penting akan didorong ke saluran telegram yang dikonfigurasi untuk klaster Replikasi MariaDB 10.3 kami:

ClusterControl juga mendukung integrasi chatbot, di mana Anda dapat berinteraksi dengan layanan pengontrol melalui klien s9s langsung dari alat perpesanan Anda seperti yang ditunjukkan dalam posting blog ini, Otomatiskan Basis Data Anda dengan CCBot:ClusterControl Hubot Integration.
Kesimpulan
ClusterControl menawarkan satu set lengkap alat pemantauan proaktif untuk cluster database Anda. Gunakan ClusterControl untuk memantau pengaturan replikasi MariaDB Anda karena sebagian besar fitur pemantauan tersedia secara gratis di edisi komunitas. Jangan sampai ketinggalan!



