Jika Anda belum melihatnya, kami baru saja merilis ClusterControl 1.7.5 dengan peningkatan besar dan fitur baru yang berguna. Beberapa fitur tersebut antara lain Cluster Wide Maintenance, dukungan untuk versi CentOS 8 dan Debian 10, Dukungan PostgreSQL 12, dukungan MongoDB 4.2 dan Percona MongoDB v4.0, serta MySQL Freeze Frame yang baru.
Tunggu, tapi Apa itu MySQL Freeze Frame? Apakah Ini Sesuatu yang Baru di MySQL?
Yah, itu bukan sesuatu yang baru di dalam Kernel MySQL itu sendiri. Ini adalah fitur baru yang kami tambahkan ke ClusterControl 1.7.5 yang khusus untuk database MySQL. MySQL Freeze Frame di ClusterControl 1.7.5 akan mencakup hal-hal berikut:
- Snapshot status MySQL sebelum kegagalan cluster.
- Snapshot daftar proses MySQL sebelum kegagalan cluster (segera hadir).
- Periksa insiden cluster dalam laporan operasional atau dari alat baris perintah s9s.
Ini adalah kumpulan informasi berharga yang dapat membantu melacak bug dan memperbaiki klaster MySQL/MariaDB Anda saat terjadi masalah. Di masa mendatang, kami berencana untuk menyertakan juga snapshot dari nilai status SHOW ENGINE InnoDB juga. Jadi, pantau terus rilis kami selanjutnya.
Perhatikan bahwa fitur ini masih dalam status beta, kami berharap dapat mengumpulkan lebih banyak set data saat kami bekerja dengan pengguna kami. Di blog ini, kami akan menunjukkan kepada Anda bagaimana memanfaatkan fitur ini, terutama ketika Anda membutuhkan informasi lebih lanjut saat mendiagnosis cluster MySQL/MariaDB Anda.
ClusterControl dalam Menangani Kegagalan Cluster
Untuk kegagalan cluster, ClusterControl tidak melakukan apa pun kecuali Pemulihan Otomatis (Cluster/Node) diaktifkan seperti di bawah ini:

Setelah diaktifkan, ClusterControl akan mencoba memulihkan node atau memulihkan cluster dengan memunculkan seluruh topologi cluster.
Untuk MySQL, misalnya dalam replikasi master-slave, ia harus memiliki setidaknya satu master yang hidup pada waktu tertentu, terlepas dari jumlah slave/s yang tersedia. ClusterControl mencoba untuk memperbaiki topologi setidaknya sekali untuk kluster replikasi, tetapi memberikan lebih banyak percobaan ulang untuk replikasi multi-master seperti Cluster NDB dan Cluster Galera. Pemulihan simpul mencoba memulihkan simpul basis data yang gagal, mis. ketika proses dimatikan (shutdown abnormal), atau proses mengalami OOM (Out-of-Memory). ClusterControl akan terhubung ke node melalui SSH dan mencoba memunculkan MySQL. Kami sebelumnya telah membuat blog tentang Bagaimana ClusterControl Melakukan Pemulihan dan Failover Database Otomatis, jadi silakan kunjungi artikel tersebut untuk mempelajari lebih lanjut tentang skema pemulihan otomatis ClusterControl.
Dalam versi ClusterControl <1.7.5 sebelumnya, upaya pemulihan tersebut memicu alarm. Tetapi satu hal yang terlewatkan oleh pelanggan kami adalah laporan insiden yang lebih lengkap dengan informasi status tepat sebelum kegagalan klaster. Sampai kami menyadari kekurangan ini dan menambahkan fitur ini di ClusterControl 1.7.5. Kami menyebutnya "Bingkai Pembekuan MySQL". MySQL Freeze Frame, pada tulisan ini, menawarkan ringkasan singkat dari insiden yang mengarah ke perubahan status cluster sebelum crash. Yang paling penting, itu termasuk di akhir laporan daftar host dan variabel dan nilai Status Global MySQL mereka.
Bagaimana Perbedaan Bingkai Pembekuan MySQL Dengan Pemulihan Otomatis?
MySQL Freeze Frame bukan bagian dari pemulihan otomatis ClusterControl. Baik Pemulihan Otomatis dinonaktifkan atau diaktifkan, MySQL Freeze Frame akan selalu berfungsi selama kegagalan cluster atau node terdeteksi.
Bagaimana Cara Kerja MySQL Freeze Frame?
Dalam ClusterControl, ada status tertentu yang kami klasifikasikan sebagai berbagai jenis Status Cluster. MySQL Freeze Frame akan menghasilkan laporan insiden ketika dua status ini dipicu:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
Dalam ClusterControl, CLUSTER_DEGRADED adalah saat Anda dapat menulis ke sebuah cluster, tetapi satu atau lebih node sedang down. Ketika ini terjadi, ClusterControl akan membuat laporan insiden.
Untuk CLUSTER_FAILURE, meskipun nomenklaturnya menjelaskan dirinya sendiri, ini adalah status di mana cluster Anda gagal dan tidak lagi dapat memproses baca atau tulis. Maka itu adalah status CLUSTER_FAILURE. Terlepas dari apakah proses pemulihan otomatis mencoba memperbaiki masalah atau menonaktifkannya, ClusterControl akan membuat laporan insiden.
Bagaimana Anda Mengaktifkan MySQL Freeze Frame?
Bingkai Pembekuan MySQL ClusterControl diaktifkan secara default dan hanya menghasilkan laporan insiden hanya ketika status CLUSTER_DEGRADED atau CLUSTER_FAILURE dipicu atau ditemui. Jadi pengguna tidak perlu mengatur pengaturan konfigurasi ClusterControl, ClusterControl akan melakukannya untuk Anda secara otomatis.
Menemukan Lokasi Laporan Insiden MySQL Freeze Frame
Pada tulisan ini, ada 4 cara Anda dapat menemukan laporan insiden. Ini dapat ditemukan dengan melakukan bagian berikut di bawah ini.
Menggunakan Tab Laporan Operasional
Laporan Operasional dari versi sebelumnya hanya digunakan untuk membuat, menjadwalkan, atau membuat daftar laporan operasional yang telah dibuat oleh pengguna. Sejak versi 1.7.5, kami menyertakan laporan insiden yang dihasilkan oleh fitur MySQL Freeze Frame kami. Lihat contoh di bawah ini:
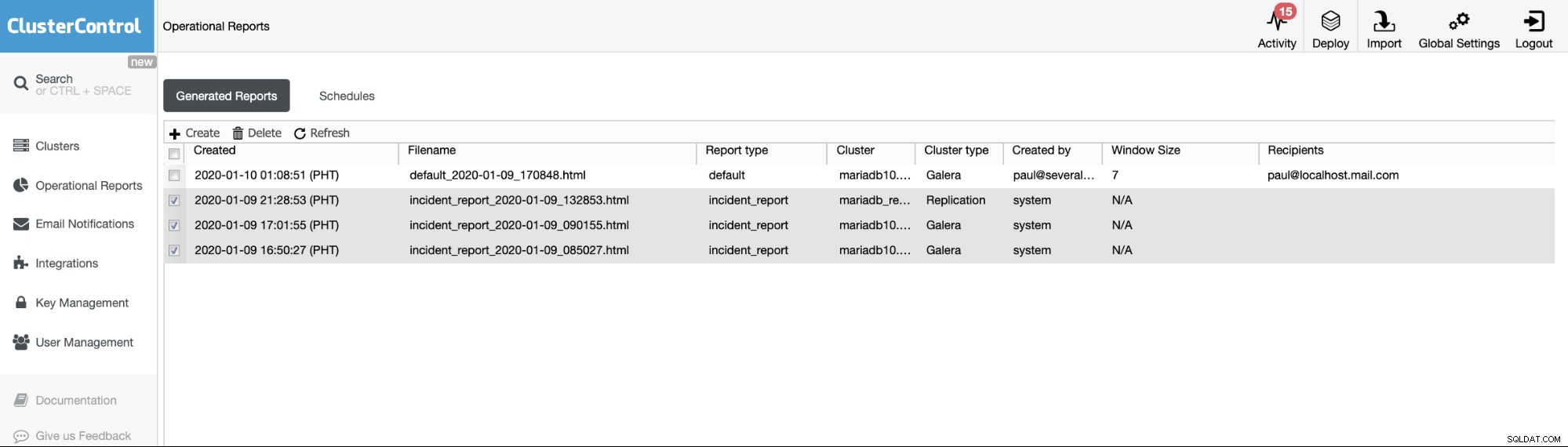
Item yang dicentang atau item dengan tipe Laporan ==incident_report, adalah insiden laporan yang dihasilkan oleh fitur MySQL Freeze Frame di ClusterControl.
Menggunakan Laporan Kesalahan
Dengan memilih cluster dan membuat laporan kesalahan, yaitu melalui proses ini:
Menggunakan s9s CLI Command Line
Pada laporan insiden yang dibuat, ini menyertakan instruksi atau petunjuk tentang bagaimana Anda dapat menggunakan ini dengan perintah s9s CLI. Berikut adalah apa yang ditampilkan dalam laporan insiden:
Petunjuk! Menggunakan alat CLI s9s memungkinkan Anda untuk dengan mudah mengambil data dalam laporan ini, misalnya:
s9s report --list --long
s9s report --cat --report-id=NJadi, jika Anda ingin mencari dan membuat laporan kesalahan, Anda dapat menggunakan pendekatan ini:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportJika saya ingin mengambil variabel wsrep_* pada host tertentu, saya dapat melakukan hal berikut:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Menemukan Lokasi Secara Manual melalui Jalur File Sistem
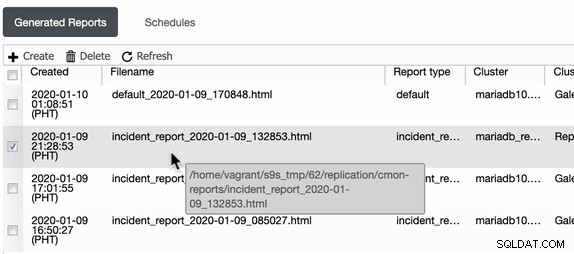
ClusterControl menghasilkan laporan insiden ini di host tempat ClusterControl berjalan. ClusterControl membuat direktori di /home/
Apakah Ada Bahaya atau Peringatan Saat Menggunakan MySQL Freeze Frame?
ClusterControl tidak mengubah atau memodifikasi apa pun di node atau cluster MySQL Anda. MySQL Freeze Frame hanya akan membaca SHOW GLOBAL STATUS (saat ini) pada interval tertentu untuk menyimpan catatan karena kami tidak dapat memprediksi status node atau klaster MySQL ketika dapat crash atau ketika dapat memiliki masalah perangkat keras atau disk. Tidak mungkin untuk memprediksi ini, jadi kami menyimpan nilainya dan oleh karena itu kami dapat membuat laporan insiden jika node tertentu mati. Dalam hal ini, bahaya memiliki ini hampir tidak ada. Secara teoritis dapat menambahkan serangkaian permintaan klien ke server jika beberapa kunci ditahan di dalam MySQL, tetapi kami belum menyadarinya. Serangkaian tes tidak menunjukkan ini jadi kami akan senang jika Anda dapat membiarkannya kami mengetahui atau mengajukan tiket dukungan jika timbul masalah.
Ada situasi tertentu di mana laporan insiden mungkin tidak dapat mengumpulkan variabel status global jika masalah jaringan adalah masalah sebelum ClusterControl membekukan bingkai tertentu untuk mengumpulkan data. Itu sepenuhnya masuk akal karena tidak mungkin ClusterControl dapat mengumpulkan data untuk diagnosis lebih lanjut karena tidak ada koneksi ke node sejak awal.
Terakhir, Anda mungkin bertanya-tanya mengapa tidak semua variabel ditampilkan di bagian STATUS GLOBAL? Untuk sementara, kami menetapkan filter di mana nilai kosong atau 0 dikecualikan dalam laporan insiden. Alasannya adalah kami ingin menghemat ruang disk. Setelah laporan insiden ini tidak lagi diperlukan, Anda dapat menghapusnya melalui Tab Laporan Operasional.
Menguji Fitur MySQL Freeze Frame
Kami yakin Anda ingin mencoba yang ini dan melihat cara kerjanya. Tapi tolong, pastikan Anda tidak menjalankan atau menguji ini di lingkungan hidup atau produksi. Kami akan membahas skenario 2 fase di MySQL/MariaDB, satu untuk penyiapan master-slave dan satu lagi untuk penyiapan tipe Galera.
Skenario Pengujian Penyiapan Master-Slave
Dalam pengaturan master-slave, mudah dan sederhana untuk dicoba.
Langkah Pertama
Pastikan Anda telah menonaktifkan mode Auto Recovery (Cluster dan Node), seperti di bawah ini:

sehingga tidak akan mencoba atau mencoba memperbaiki skenario pengujian.
Langkah Kedua
Buka node Master Anda dan coba setel ke read-only:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Langkah Ketiga
Kali ini, alarm dibunyikan dan laporan insiden dibuat. Lihat di bawah bagaimana tampilan cluster saya:

dan alarm dipicu:

dan laporan insiden dibuat:

Skenario Uji Penyiapan Galera Cluster
Untuk penyiapan berbasis Galera, kita perlu memastikan bahwa kluster tidak akan tersedia lagi, yaitu kegagalan di seluruh kluster. Tidak seperti tes Master-Slave, Anda dapat mengaktifkan Pemulihan Otomatis karena kami akan bermain-main dengan antarmuka jaringan.
Catatan:Untuk penyiapan ini, pastikan Anda memiliki beberapa antarmuka jika Anda menguji node dalam instance jarak jauh karena Anda tidak dapat menaikkan antarmuka saat menurunkan antarmuka di mana Anda terhubung.
Langkah Pertama
Buat cluster Galera 3-simpul (misalnya menggunakan gelandangan)
Langkah Kedua
Keluarkan perintah (seperti di bawah) untuk mensimulasikan masalah jaringan dan lakukan ini ke semua node
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Langkah Ketiga
Sekarang, cluster saya turun dan statusnya seperti ini:

membunyikan alarm,

dan ini menghasilkan laporan insiden:

Untuk contoh laporan insiden, Anda dapat menggunakan file mentah ini dan menyimpannya sebagai html.
Cukup mudah untuk dicoba, tetapi sekali lagi, harap lakukan ini hanya di lingkungan non-live dan non-prod.
Kesimpulan
MySQL Freeze Frame di ClusterControl dapat membantu saat mendiagnosis kerusakan. Saat memecahkan masalah, Anda memerlukan banyak informasi untuk menentukan penyebabnya dan itulah yang disediakan oleh MySQL Freeze Frame.