Galera Cluster hadir dengan banyak fitur penting yang tidak tersedia dalam replikasi MySQL standar (atau Replikasi Grup); penyediaan node otomatis, multi-master sejati dengan resolusi konflik dan failover otomatis. Ada juga sejumlah batasan yang berpotensi memengaruhi kinerja klaster. Untungnya, jika Anda tidak mengetahuinya, ada solusi. Dan jika Anda melakukannya dengan benar, Anda dapat meminimalkan dampak pembatasan ini dan meningkatkan kinerja secara keseluruhan.
Kami sebelumnya telah membahas banyak tip dan trik terkait Galera Cluster, termasuk menjalankan Galera di AWS Cloud. Entri blog ini secara jelas membahas aspek kinerja, dengan contoh tentang cara mendapatkan hasil maksimal dari Galera.
Payload Replikasi
Sedikit pengantar - Galera mereplikasi writeset selama tahap komit, mentransfer writeset dari node originator ke node penerima secara sinkron melalui plugin replikasi wsrep. Plugin ini juga akan mengesahkan writesets pada node penerima. Jika proses sertifikasi berlalu, ia mengembalikan OK ke klien pada node originator dan akan diterapkan pada node penerima di lain waktu secara asinkron. Jika tidak, transaksi akan dibatalkan pada node originator (mengembalikan error ke klien) dan writeset yang telah ditransfer ke node penerima akan dibuang.
Writeset terdiri dari operasi tulis di dalam transaksi yang mengubah status basis data. Di Galera Cluster, autocommit adalah default ke 1 (diaktifkan). Secara harfiah, setiap pernyataan SQL yang dieksekusi di Galera Cluster akan dilampirkan sebagai transaksi, kecuali Anda secara eksplisit memulai dengan BEGIN, START TRANSACTION atau SET autocommit=0. Diagram berikut mengilustrasikan enkapsulasi pernyataan DML tunggal menjadi writeset:
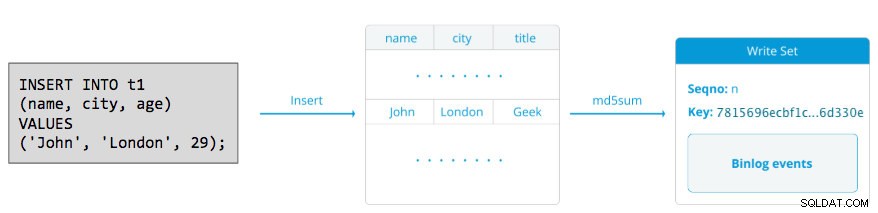
Untuk DML (INSERT, UPDATE, DELETE..), payload writeset terdiri dari peristiwa log biner untuk transaksi tertentu sedangkan untuk DDL (ALTER, GRANT, CREATE..), payload writeset adalah pernyataan DDL itu sendiri. Untuk DML, writeset harus disertifikasi terhadap konflik pada node penerima sedangkan untuk DDL (bergantung pada wsrep_osu_method , default ke TOI), cluster cluster menjalankan pernyataan DDL pada semua node dalam urutan urutan total yang sama, memblokir transaksi lain dari melakukan saat DDL sedang berlangsung (lihat juga RSU). Dengan kata sederhana, Galera Cluster menangani replikasi DDL dan DML secara berbeda.
Waktu Pulang Pergi
Secara umum, faktor berikut menentukan seberapa cepat Galera dapat mereplikasi writeset dari node originator ke semua node penerima:
- Waktu pulang pergi (round trip time (RTT) ke node terjauh dalam cluster dari node originator.
- Ukuran writeset yang akan ditransfer dan disertifikasi untuk konflik pada node penerima.
Misalnya, jika kita memiliki Galera Cluster tiga node dan salah satu node terletak 10 milidetik (0,01 detik), sangat tidak mungkin Anda dapat menulis lebih dari 100 kali per detik ke baris yang sama tanpa konflik. Ada kutipan populer dari Mark Callaghan yang menggambarkan perilaku ini dengan cukup baik:
"[Dalam kluster Galera] baris tertentu tidak dapat diubah lebih dari satu kali per RTT"
Untuk mengukur nilai RTT, cukup lakukan ping pada node originator ke node terjauh dalam cluster:
$ ping 192.168.55.173 # the farthest nodeTunggu beberapa detik (atau menit) dan akhiri perintah. Baris terakhir dari bagian statistik ping adalah yang kita cari:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msmaks nilainya adalah 1,340 ms (0,00134 detik) dan kita harus mengambil nilai ini saat memperkirakan minimum transaksi per detik (tps) untuk cluster ini. rata-rata nilainya adalah 0,431ms (0,000431s) dan dapat kita gunakan untuk memperkirakan rata-rata tps sementara min nilainya adalah 0.111ms (0,000111s) yang dapat kita gunakan untuk memperkirakan maksimum tp Mdev berarti bagaimana sampel RTT didistribusikan dari rata-rata. Nilai yang lebih rendah berarti RTT yang lebih stabil.
Oleh karena itu, transaksi per detik dapat diperkirakan dengan membagi RTT (dalam detik) menjadi 1 detik:

Hasilnya,
- TPs minimum:1 / 0,00134 (RTT maks) =746,26 ~ 746 tps
- Rata-rata tps:1 / 0,000431 (RTT rata-rata) =2320,19 ~ 2320 tps
- TPs maksimum:1 / 0,000111 (RTT min) =9009,01 ~ 9009 tps
Perhatikan bahwa ini hanya perkiraan untuk mengantisipasi kinerja replikasi. Tidak banyak yang dapat kami lakukan untuk meningkatkan ini di sisi basis data, setelah kami menerapkan dan menjalankan semuanya. Kecuali, jika Anda memindahkan atau memigrasi server database lebih dekat satu sama lain untuk meningkatkan RTT antar node, atau memutakhirkan periferal atau infrastruktur jaringan. Ini akan membutuhkan masa pemeliharaan dan perencanaan yang tepat.
Memotong Transaksi Besar
Faktor lainnya adalah ukuran transaksi. Setelah writeset ditransfer, akan ada proses sertifikasi. Sertifikasi adalah proses untuk menentukan apakah node dapat menerapkan writeset atau tidak. Galera menghasilkan kunci semu checksum MD5 dari setiap baris penuh. Biaya sertifikasi tergantung pada ukuran writeset, yang diterjemahkan ke dalam sejumlah pencarian kunci unik ke dalam indeks sertifikasi (tabel hash). Jika Anda memperbarui 500.000 baris dalam satu transaksi, misalnya:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Di atas akan menghasilkan satu writeset dengan 500.000 peristiwa log biner di dalamnya. Writeset besar ini tidak melebihi wsrep_max_ws_size (default ke 2GB) sehingga akan ditransfer oleh plugin replikasi Galera ke semua node dalam cluster, menyatakan 500.000 baris ini pada node penerima untuk setiap transaksi yang bertentangan yang masih dalam antrian slave. Terakhir, status sertifikasi dikembalikan ke plugin replikasi grup. Semakin besar ukuran transaksi, semakin tinggi risikonya akan bertentangan dengan transaksi lain yang berasal dari master lain. Transaksi yang bentrok membuang sumber daya server, ditambah menyebabkan kemunduran besar ke node originator. Perhatikan bahwa operasi rollback di MySQL jauh lebih lambat dan kurang optimal dibandingkan operasi commit.
Pernyataan SQL di atas dapat ditulis ulang menjadi pernyataan yang lebih ramah Galera dengan bantuan perulangan sederhana, seperti contoh di bawah ini:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
donePerintah shell di atas akan memperbarui 1000 baris per transaksi selama 500 kali dan menunggu selama 2 detik di antara eksekusi. Anda juga dapat menggunakan prosedur tersimpan atau cara lain untuk mencapai hasil yang serupa. Jika menulis ulang kueri SQL bukan merupakan opsi, cukup instruksikan aplikasi untuk mengeksekusi transaksi besar selama jendela pemeliharaan untuk mengurangi risiko konflik.
Untuk penghapusan besar-besaran, pertimbangkan untuk menggunakan pt-archiver dari Percona Toolkit - tugas forward-impact yang rendah untuk menghapus data lama dari tabel tanpa terlalu memengaruhi kueri OLTP.
Utas Budak Paralel
Di Galera, applier adalah proses multithreaded. Applier adalah utas yang berjalan di dalam Galera untuk menerapkan set tulis yang masuk dari node lain. Artinya, semua receiver dapat menjalankan beberapa operasi DML yang datang langsung dari node originator (master) secara bersamaan. Replikasi paralel Galera hanya diterapkan pada transaksi jika aman untuk dilakukan. Ini meningkatkan kemungkinan node untuk menyinkronkan dengan node originator. Namun, kecepatan replikasi masih terbatas pada RTT dan ukuran writeset.
Untuk mendapatkan yang terbaik dari ini, kita perlu mengetahui dua hal:
- Jumlah inti yang dimiliki server.
- Nilai wsrep_cert_deps_distance status.
Status wsrep_cert_deps_distance memberitahu kita tingkat potensial paralelisasi. Ini adalah nilai jarak rata-rata antara nilai seqno tertinggi dan terendah yang mungkin dapat diterapkan secara paralel. Anda dapat menggunakan wsrep_cert_deps_distance variabel status untuk menentukan jumlah maksimum utas budak yang mungkin. Perhatikan bahwa ini adalah nilai rata-rata sepanjang waktu. Oleh karena itu, untuk mendapatkan nilai yang baik, Anda harus menekan cluster dengan operasi tulis melalui beban kerja pengujian atau benchmark hingga Anda melihat nilai stabil yang keluar.
Untuk mendapatkan jumlah core, Anda cukup menggunakan perintah berikut:
$ grep -c processor /proc/cpuinfo
4Idealnya, 2, 3 atau 4 thread dari slave applier per inti CPU adalah awal yang baik. Jadi, nilai minimum untuk utas budak harus 4 x jumlah inti CPU, dan tidak boleh melebihi wsrep_cert_deps_distance nilai:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Anda dapat mengontrol jumlah utas slave applier menggunakan wsrep_slave_thread variabel. Meskipun ini adalah variabel dinamis, hanya peningkatan jumlah yang akan memiliki efek langsung. Jika Anda mengurangi nilainya secara dinamis, itu akan memakan waktu, hingga thread applier keluar setelah selesai diterapkan. Nilai yang disarankan adalah antara 16 hingga 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Perhatikan bahwa agar utas budak paralel berfungsi, hal berikut harus diatur (yang biasanya telah dikonfigurasi sebelumnya untuk Galera Cluster):
innodb_autoinc_lock_mode=2Cache Galera (gcache)
Galera menggunakan file yang telah dialokasikan sebelumnya dengan ukuran tertentu yang disebut gcache, di mana node Galera menyimpan salinan writeset dalam gaya buffer melingkar. Secara default, ukurannya adalah 128MB, yang agak kecil. Incremental State Transfer (IST) adalah metode untuk menyiapkan joiner dengan hanya mengirimkan writeset yang hilang yang tersedia di gcache donor. IST lebih cepat daripada transfer snapshot negara (SST), ini tidak memblokir dan tidak memiliki dampak kinerja yang signifikan pada donor. Ini harus menjadi pilihan yang lebih disukai bila memungkinkan.
IST hanya dapat dicapai jika semua perubahan yang terlewatkan oleh joiner masih ada di file gcache donor. Pengaturan yang disarankan untuk ini adalah sebesar keseluruhan dataset MySQL. Jika ruang disk terbatas atau mahal, menentukan ukuran gcache yang tepat sangat penting, karena dapat memengaruhi kinerja sinkronisasi data antar node Galera.
Pernyataan di bawah ini akan memberi kita gambaran tentang jumlah data yang direplikasi oleh Galera. Jalankan pernyataan berikut di salah satu node Galera selama jam sibuk (diuji pada MariaDB>10.0 dan PXC>5.6, galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Kami dapat memperkirakan bahwa node Galera dapat memiliki waktu henti sekitar 16 menit, tanpa memerlukan SST untuk bergabung (kecuali jika Galera tidak dapat menentukan status joiner). Jika waktu ini terlalu singkat dan Anda memiliki cukup ruang disk di node, Anda dapat mengubah wsrep_provider_options="gcache.size=
Disarankan juga untuk menggunakan gcache.recover=yes di wsrep_provider_options (Galera>3.19), di mana Galera akan mencoba memulihkan file gcache ke status yang dapat digunakan saat startup daripada menghapusnya, sehingga mempertahankan kemampuan untuk memiliki IST dan menghindari SST sebanyak mungkin. Codership dan Percona telah membahas ini secara rinci di blog mereka. IST selalu merupakan metode terbaik untuk menyinkronkan setelah sebuah node bergabung kembali dengan cluster. Ini 50% lebih cepat dari xtrabackup atau mariabackup dan 5x lebih cepat dari mysqldump.
Budak Asinkron
Node Galera digabungkan dengan erat, di mana kinerja replikasi secepat node paling lambat. Galera menggunakan mekanisme kontrol aliran, untuk mengontrol aliran replikasi di antara anggota dan menghilangkan lag slave. Replikasi bisa cepat atau lambat di setiap node dan diatur secara otomatis oleh Galera. Jika Anda ingin tahu tentang kontrol aliran, baca posting blog ini oleh Jay Janssen dari Percona.
Dalam kebanyakan kasus, operasi berat seperti analitik yang berjalan lama (intensif baca) dan pencadangan (intensif baca, penguncian) seringkali tidak dapat dihindari, yang berpotensi menurunkan kinerja cluster. Cara terbaik untuk mengeksekusi jenis kueri ini adalah dengan mengirimkannya ke server replika yang digabungkan secara longgar, misalnya, slave asinkron.
Budak asinkron mereplikasi dari simpul Galera menggunakan protokol replikasi asinkron MySQL standar. Tidak ada batasan jumlah budak yang dapat dihubungkan ke satu simpul Galera, dan menghubungkannya dengan master perantara juga dimungkinkan. Operasi MySQL yang dijalankan di server ini tidak akan memengaruhi kinerja cluster, selain dari fase sinkronisasi awal di mana cadangan penuh harus diambil pada node Galera untuk mengatur slave sebelum membuat tautan replikasi (walaupun ClusterControl memungkinkan Anda untuk membuat async budak dari cadangan yang ada terlebih dahulu, sebelum menghubungkannya ke cluster).
GTID (Global Transaction Identifier) menyediakan pemetaan transaksi yang lebih baik di seluruh node, dan didukung di MySQL 5.6 dan MariaDB 10.0. Dengan GTID, operasi failover pada slave ke master lain (node Galera lain) disederhanakan, tanpa perlu mengetahui file log dan posisi yang tepat. Galera juga hadir dengan implementasi GTID-nya sendiri, tetapi keduanya independen satu sama lain.
Menskalakan slave asinkron hanya dengan sekali klik jika Anda menggunakan ClusterControl -> Tambahkan fitur Replication Slave:
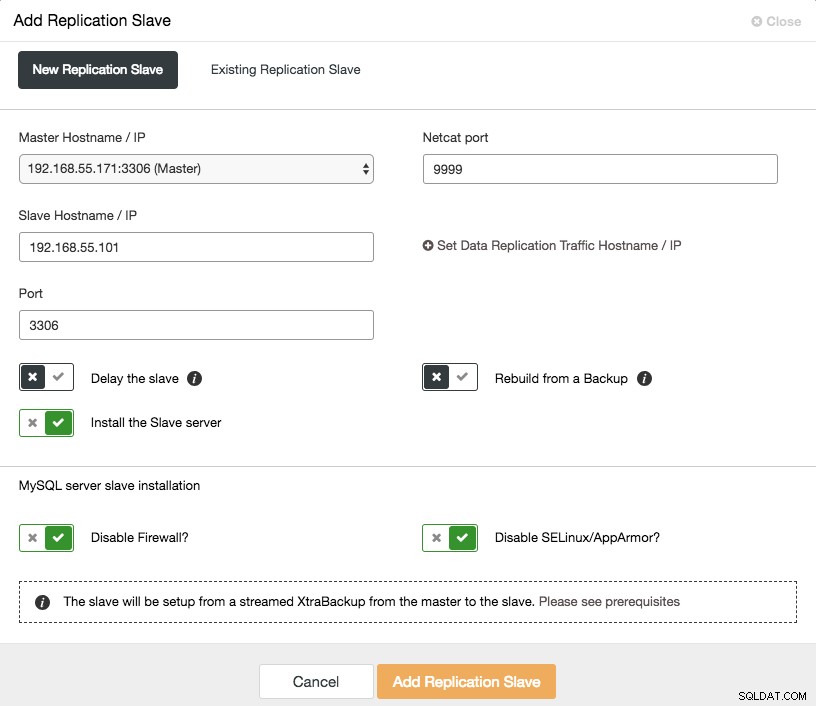
Perhatikan bahwa log biner harus diaktifkan pada master (node Galera yang dipilih) sebelum kita dapat melanjutkan pengaturan ini. Kami juga telah membahas cara manual di postingan sebelumnya.
Tangkapan layar berikut dari ClusterControl menunjukkan topologi cluster, ini menggambarkan arsitektur Galera Cluster kami dengan slave asinkron:
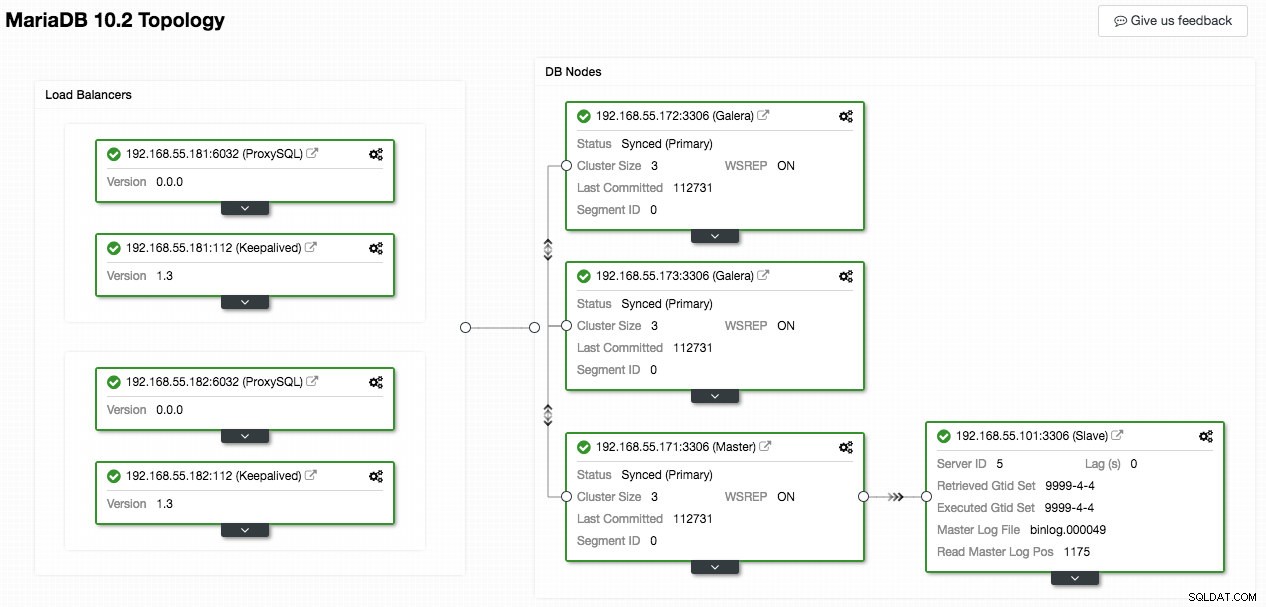
ClusterControl secara otomatis menemukan topologi dan menghasilkan diagram super keren seperti di atas. Anda juga dapat melakukan tugas administrasi langsung dari halaman ini dengan mengklik ikon roda gigi kanan atas setiap kotak.
Proxy Terbalik yang sadar SQL
ProxySQL dan MariaDB MaxScale adalah reverse-proxies cerdas yang memahami protokol MySQL dan mampu bertindak sebagai gateway, router, load balancer, dan firewall di depan node Galera Anda. Dengan bantuan penyedia Alamat IP Virtual seperti LVS atau Keepalive, dan menggabungkannya dengan teknologi replikasi multi-master Galera, kami dapat memiliki layanan basis data yang sangat tersedia, menghilangkan semua kemungkinan kegagalan titik tunggal (SPOF) dari titik aplikasi -dari-pandangan. Hal ini tentunya akan meningkatkan ketersediaan dan keandalan arsitektur secara keseluruhan.
Keuntungan lain dengan pendekatan ini adalah Anda akan memiliki kemampuan untuk memantau, menulis ulang, atau merutekan ulang kueri SQL yang masuk berdasarkan seperangkat aturan sebelum mencapai server database yang sebenarnya, meminimalkan perubahan pada aplikasi atau sisi klien dan merutekan kueri ke node yang lebih cocok untuk kinerja yang optimal. Kueri berisiko untuk Galera seperti LOCK TABLES dan FLUSH TABLES WITH READ LOCK dapat dicegah jauh di depan sebelum menyebabkan malapetaka pada sistem, sementara memengaruhi kueri seperti kueri "hotspot" (baris yang ingin diakses oleh kueri yang berbeda pada saat yang sama) dapat ditulis ulang atau dialihkan ke satu simpul Galera untuk mengurangi risiko konflik transaksi. Untuk kueri read-only yang berat seperti OLAP atau backup, Anda dapat mengarahkannya ke slave asinkron jika ada.
Reverse proxy juga memantau status database, kueri, dan variabel untuk memahami perubahan topologi dan menghasilkan keputusan perutean yang akurat ke server backend. Secara tidak langsung, ini memusatkan pemantauan node dan ikhtisar cluster tanpa perlu memeriksa setiap node Galera secara teratur. Tangkapan layar berikut menunjukkan dasbor pemantauan ProxySQL di ClusterControl:
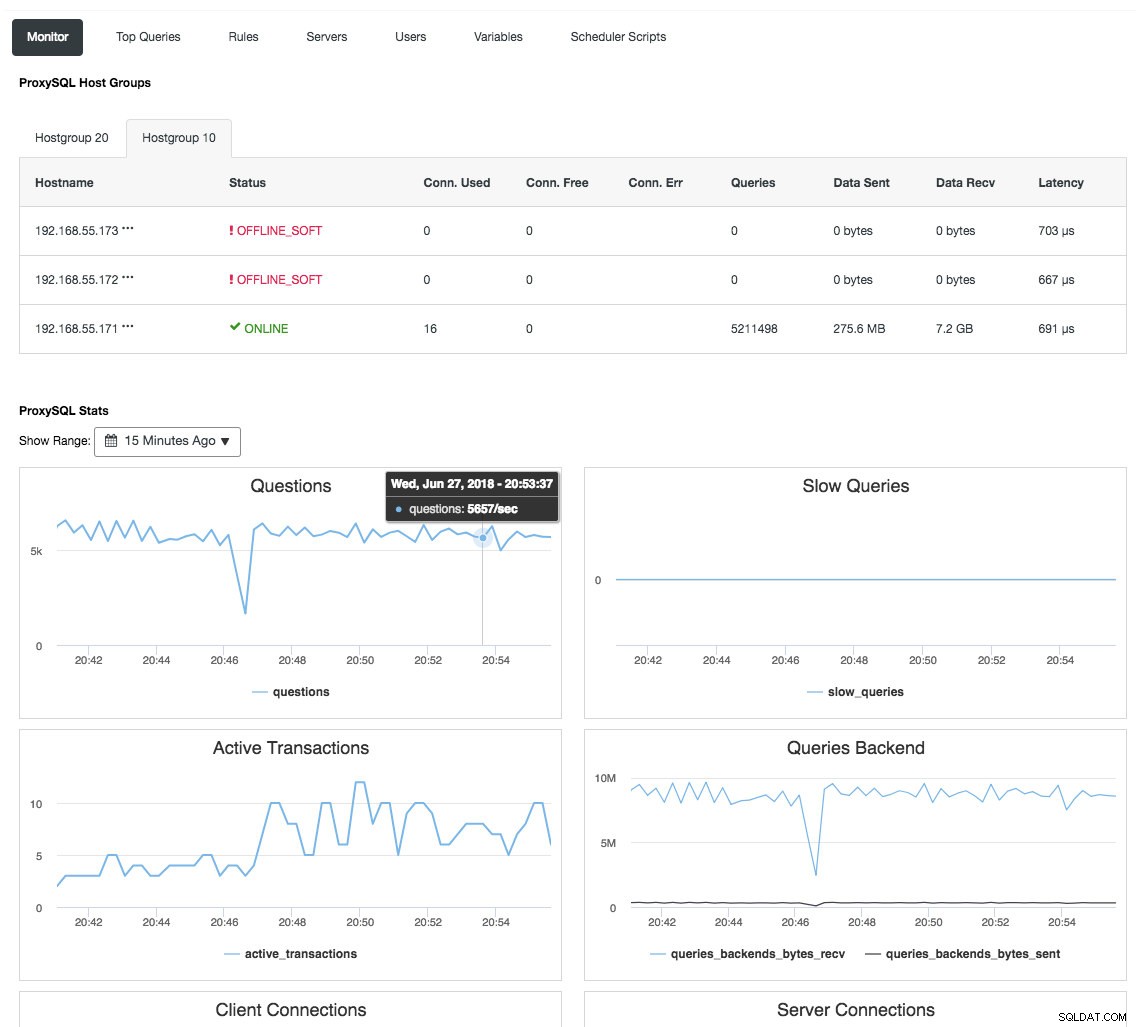
Ada juga banyak manfaat lain yang dapat dibawa oleh penyeimbang beban untuk meningkatkan Galera Cluster secara signifikan, seperti yang dibahas secara rinci dalam posting blog ini, Menjadi ClusterControl DBA:Membuat komponen DB Anda menjadi HA melalui Load Balancer.
Pemikiran Akhir
Dengan pemahaman yang baik tentang cara kerja Galera Cluster secara internal, kami dapat mengatasi beberapa keterbatasan dan meningkatkan layanan database. Selamat mengelompokkan!