Ingin ikut serta dengan opsi untuk menyelesaikan tugas Anda dengan BigQuery (SQL Standar) murni
Prasyarat / asumsi :sumber data ada di sandbox.temp.id1_id2_pairs
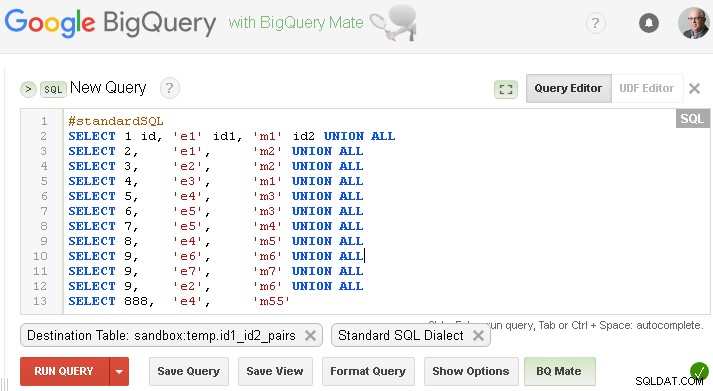
Anda harus mengganti ini dengan milik Anda sendiri atau jika Anda ingin menguji dengan data dummy dari pertanyaan Anda - Anda dapat membuat tabel ini seperti di bawah ini (tentu saja ganti sandbox.temp dengan project.dataset Anda sendiri )
Pastikan Anda mengatur tabel tujuan masing-masing
Catatan :Anda dapat menemukan semua Pertanyaan masing-masing (sebagai teks) di bagian bawah jawaban ini, tetapi untuk saat ini saya menggambarkan jawaban saya dengan tangkapan layar - jadi semuanya disajikan - kueri, hasil, dan opsi yang digunakan
Jadi, akan ada tiga langkah:
Langkah 1 - Inisialisasi
Disini kita hanya melakukan pengelompokan awal id1 berdasarkan koneksi dengan id2:
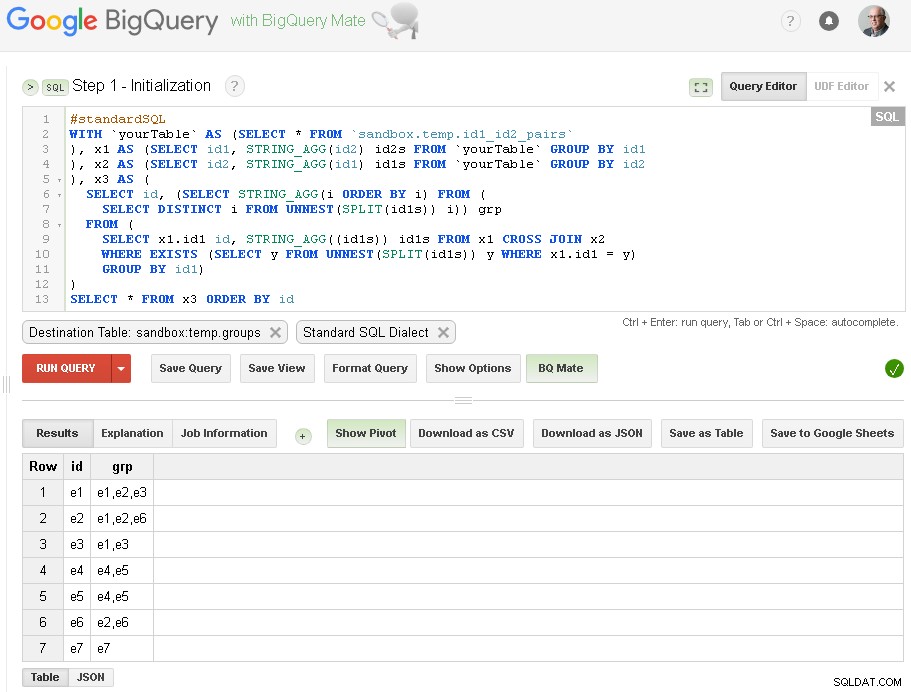
Seperti yang Anda lihat di sini - kami membuat daftar semua nilai id1 dengan koneksi masing-masing berdasarkan koneksi satu tingkat sederhana melalui id2
Tabel keluaran adalah sandbox.temp.groups
Langkah 2 - Mengelompokkan Iterasi
Dalam setiap iterasi kita akan memperkaya pengelompokan berdasarkan grup yang sudah terbentuk.
Sumber Query adalah tabel keluaran dari Langkah sebelumnya (sandbox.temp.groups ) dan Destination adalah tabel yang sama (sandbox.temp.groups ) dengan Timpa
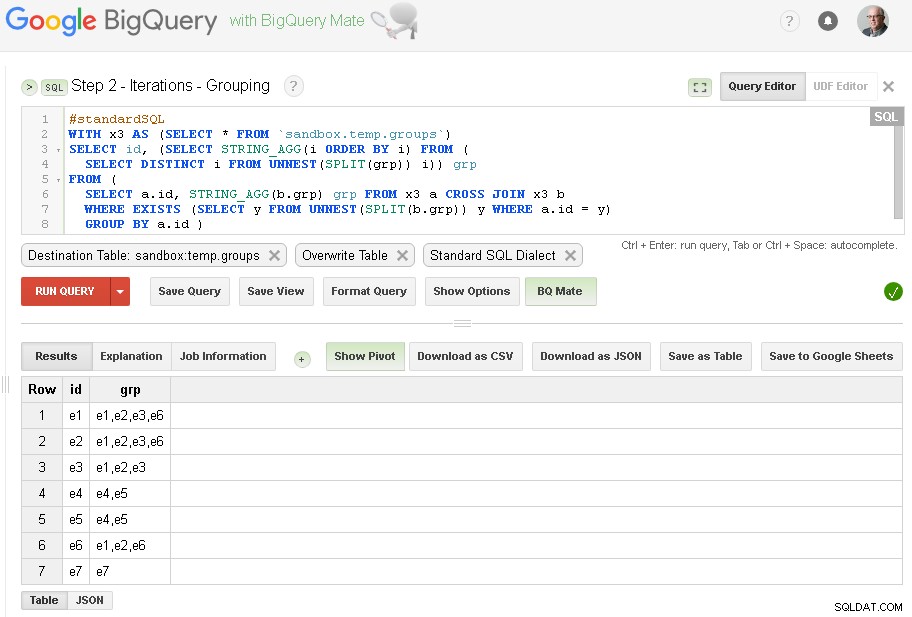
Kami akan melanjutkan iterasi sampai jumlah grup yang ditemukan akan sama seperti pada iterasi sebelumnya

Catatan :Anda cukup membuka dua Tab UI Web BigQuery (seperti yang ditunjukkan di atas) dan tanpa mengubah kode apa pun, jalankan Pengelompokan, lalu Periksa lagi dan lagi hingga iterasi menyatu
(untuk data spesifik yang saya gunakan di bagian prasyarat - Saya memiliki tiga iterasi - iterasi pertama menghasilkan 5 pengguna, iterasi kedua menghasilkan 3 pengguna dan iterasi ketiga menghasilkan lagi 3 pengguna - yang menunjukkan bahwa kami selesai dengan iterasi.
Tentu saja, dalam kasus kehidupan nyata - jumlah iterasi bisa lebih dari hanya tiga - jadi kami memerlukan semacam otomatisasi (lihat bagian masing-masing di bagian bawah jawaban).
Langkah 3 – Pengelompokan Akhir
Ketika pengelompokan id1 selesai - kita dapat menambahkan pengelompokan akhir untuk id2

Hasil akhir sekarang ada di sandbox.temp.users tabel
Kueri yang Digunakan (jangan lupa untuk mengatur tabel tujuan masing-masing dan menimpa bila diperlukan sesuai logika dan tangkapan layar yang dijelaskan di atas):
Prasyarat:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Langkah 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Langkah 2 - Pengelompokan
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Langkah 2 - Periksa
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Langkah 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Otomasi :
Tentu saja, "proses" di atas dapat dijalankan secara manual untuk berjaga-jaga jika iterasi berkumpul dengan cepat - jadi Anda akan berakhir dengan 10-20 kali. Namun dalam kasus kehidupan nyata lainnya, Anda dapat dengan mudah mengotomatiskannya dengan klien
mana pun pilihan Anda