Secara teori Anda bisa melakukan ini:
- Temukan rentang unicode yang ingin Anda uji.
- Mengenkode awal dan akhir secara manual ke dalam UTF-8.
- Gunakan byte pertama dari setiap awal dan akhir yang disandikan sebagai rentang untuk REGEXP.
Saya percaya bahwa kisaran CJK cukup jauh dari hal-hal seperti simbol euro sehingga positif palsu dan negatif palsu akan sedikit atau tidak sama sekali.
Sunting: Kami sekarang telah mempraktikkan teori!
Langkah 1: Pilih rentang karakter. saya sarankan \u3000-\u9fff; mudah untuk diuji, dan akan memberikan hasil yang hampir sempurna.
Langkah 2: Enkode ke dalam byte. (halaman Wikipedia utf-8)
Untuk rentang pilihan kami, nilai yang dikodekan utf-8 akan selalu 3 byte, yang pertama adalah 1110xxxx, di mana xxxx adalah empat bit paling signifikan dari nilai unicode.
Jadi, kita ingin membuat mach byte dalam rentang 11100011 hingga 11101001, atau 0xe3 hingga 0xe9.
Langkah 3: Jadikan regexp kami menggunakan fungsi UNHEX yang sangat berguna (dan baru saja ditemukan oleh saya).
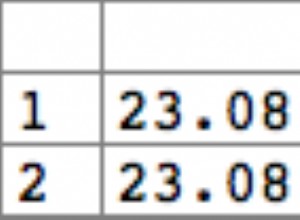
SELECT * FROM `mydata`
WHERE `words` REGEXP CONCAT('[',UNHEX('e3'),'-',UNHEX('e9'),']')
Baru saja mencobanya. Bekerja seperti pesona. :)