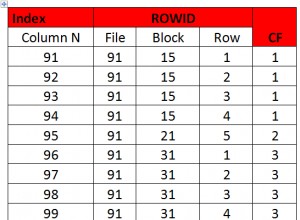
Jika Anda mencari DBMS berperforma sangat tinggi dan tidak membutuhkannya untuk relasional, Anda dapat mempertimbangkan Cassandra - meskipun keuntungannya hanya berperan jika Anda memiliki klaster database, bukan satu node.
Anda tidak mengatakan batasan apa yang ada pada arsitektur fisik. Anda memang menyebutkan sharding yang menyiratkan sebuah cluster. Cluster MySQL IIRC juga mendukung sharding.
Ini juga akan sangat berguna untuk mengetahui tingkat konkurensi apa yang dimaksudkan untuk didukung oleh sistem, dan bagaimana data akan ditambahkan (umpan tetes atau batch).
Anda mengatakan "Jelas saya tidak dapat menghitung sebelumnya hasil agregasi apa pun karena kombinasi filter (dan dengan demikian kumpulan hasil) sangat besar."
Ini adalah masalah terbesar Anda, dan akan menjadi faktor terpenting dalam menentukan kinerja sistem Anda. Tentu, Anda tidak dapat mempertahankan tampilan terwujud dari setiap kombinasi yang mungkin, tetapi kemenangan kinerja terbesar Anda akan mempertahankan tampilan pra-agregat terbatas dan membangun pengoptimal yang dapat menemukan kecocokan terdekat. Tidak terlalu sulit.
C.