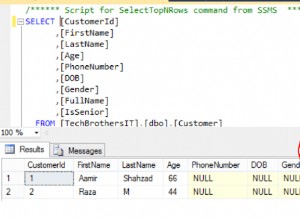
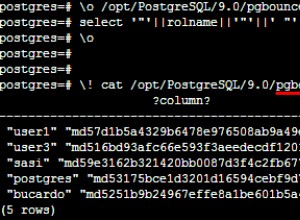
Menurut jawaban atas pertanyaan Excel to CSV dengan encoding UTF8 , Google Documents harus menyimpan CSV dengan benar, bertentangan dengan Excel, yang menghancurkan semua karakter yang tidak dapat direpresentasikan dalam pengkodean "ANSI" yang digunakan. Tapi mungkin mereka mengubah ini, atau sesuatu yang salah, atau analisis situasinya salah.
Untuk Bangla (Bengali) yang dikodekan dengan benar yang diproses dalam program MS Office, “font Bangla” tidak diperlukan, karena font Arial Unicode MS (dikirim dengan Office) berisi karakter Bangla. Jadi, apakah data sebenarnya dalam beberapa penyandian tidak standar yang bergantung pada font yang disandikan secara khusus? Dalam hal ini, itu harus terlebih dahulu dikonversi ke Unicode, meskipun mungkin entah bagaimana dapat dikelola menggunakan program yang secara konsisten menggunakan font tertentu.
Di Excel, saat menggunakan Save As, Anda dapat memilih "teks Unicode (*.txt)". Ini menyimpan data sebagai TSV (nilai yang dipisahkan tab) dalam pengkodean UTF-16. Anda mungkin perlu mengonversinya untuk menggunakan koma sebagai pemisah alih-alih tab, dan/atau dari UTF-16 ke UTF-8. Tapi ini hanya berfungsi jika data asli dikodekan dengan benar.