Dalam bekerja dengan nama orang, dan melakukan pencarian kabur pada mereka, yang berhasil bagi saya adalah membuat tabel kata kedua. Buat juga tabel ketiga yang merupakan tabel intersect untuk hubungan banyak ke banyak antara tabel yang berisi teks, dan tabel kata. Saat baris ditambahkan ke tabel teks, Anda membagi teks menjadi kata-kata dan mengisi tabel berpotongan dengan tepat, menambahkan kata baru ke tabel kata bila diperlukan. Setelah struktur ini terpasang, Anda dapat melakukan pencarian sedikit lebih cepat, karena Anda hanya perlu menjalankan fungsi damlev Anda di atas tabel kata-kata unik. Gabung sederhana memberi Anda teks yang berisi kata-kata yang cocok. 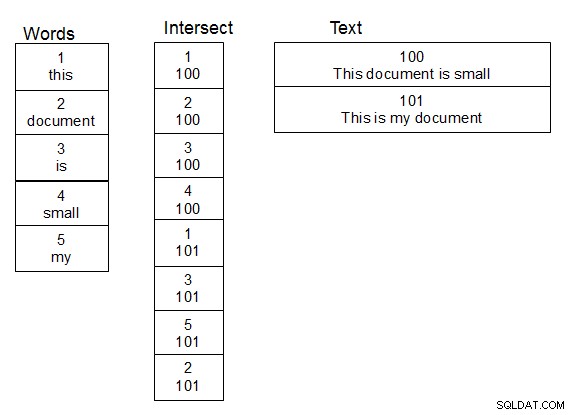
Kueri untuk satu kecocokan kata akan terlihat seperti ini:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
dan dua kata akan terlihat seperti ini (di luar kepala saya, jadi mungkin tidak sepenuhnya benar):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
Keuntungannya di sini, dengan mengorbankan beberapa ruang basis data, adalah Anda hanya perlu menerapkan fungsi damlev yang memakan waktu untuk kata-kata unik, yang mungkin hanya akan berjumlah 10-an ribu terlepas dari ukuran tabel teks Anda. Ini penting, karena damlev UDF tidak akan menggunakan indeks - ia akan memindai seluruh tabel yang diterapkan untuk menghitung nilai untuk setiap baris. Memindai hanya kata-kata unik seharusnya jauh lebih cepat. Keuntungan lainnya adalah bahwa damlev diterapkan pada tingkat kata, yang tampaknya seperti yang Anda minta. Keuntungan lainnya adalah Anda dapat memperluas kueri untuk mendukung pencarian pada banyak kata, dan dapat memberi peringkat pada hasil dengan mengelompokkan baris berpotongan yang cocok di TextId, dan memberi peringkat berdasarkan jumlah kecocokan.