Menerapkan pencarian yang ramah pengguna bisa jadi rumit, tetapi juga bisa dilakukan dengan sangat efisien. Bagaimana saya tahu ini? Belum lama ini, saya perlu menerapkan mesin pencari di aplikasi seluler. Aplikasi ini dibangun di atas kerangka Ionic dan akan terhubung ke backend CakePHP 2. Idenya adalah untuk menampilkan hasil saat pengguna mengetik. Ada beberapa opsi untuk ini, tetapi tidak semuanya memenuhi persyaratan proyek saya.
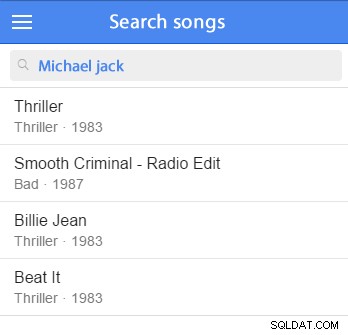
Untuk mengilustrasikan tugas semacam ini, bayangkan mencari lagu dan kemungkinan hubungannya (seperti artis, album, dll).
Catatan harus diurutkan berdasarkan relevansi, yang akan bergantung pada apakah kata pencarian cocok dengan bidang dari catatan itu sendiri atau dari kolom lain dalam tabel terkait. Juga, pencarian harus menerapkan setidaknya beberapa kata dasar yang berasal dari kata dasar. (Stemming digunakan untuk mendapatkan bentuk akar dari sebuah kata. "Stems", "stemmer", "stemming", dan "stemmed" semuanya memiliki akar yang sama:"stem".)
Pendekatan yang disajikan di sini telah diuji dengan beberapa ratus ribu catatan dan mampu mengambil hasil yang berguna saat pengguna mengetik.
Produk Pencarian Teks Lengkap untuk Dipertimbangkan
Ada beberapa cara kita bisa menerapkan pencarian semacam ini. Proyek kami memiliki beberapa kendala dalam kaitannya dengan waktu dan sumber daya server, jadi kami harus menjaga solusinya sesederhana mungkin. Beberapa pesaing akhirnya muncul:
Elasticsearch
Elasticsearch menyediakan pencarian teks lengkap dalam layanan berorientasi dokumen. Ini dirancang untuk mengelola sejumlah besar beban dengan cara terdistribusi:ini dapat memberi peringkat hasil berdasarkan relevansi, melakukan agregasi, dan bekerja dengan kata dasar dan sinonim. Alat ini dimaksudkan untuk pencarian waktu nyata. Dari situs web mereka:
Elasticsearch membangun kapabilitas terdistribusi di atas Apache Lucene untuk menyediakan kapabilitas pencarian teks lengkap paling andal yang tersedia. API kueri yang andal dan ramah pengembang mendukung penelusuran multibahasa, geolokasi, saran maksud Anda kontekstual, pelengkapan otomatis, dan cuplikan hasil.
Elasticsearch dapat bekerja sebagai layanan REST, menanggapi permintaan http, dan dapat diatur dengan sangat cepat. Namun, memulai mesin sebagai layanan mengharuskan Anda memiliki beberapa hak akses server. Dan jika penyedia hosting Anda tidak mendukung Elasticsearch, Anda harus menginstal beberapa paket.
Intinya adalah bahwa produk ini adalah pilihan yang bagus jika Anda menginginkan solusi pencarian yang solid. (Catatan:Anda mungkin memerlukan VPS atau server khusus karena persyaratan perangkat kerasnya cukup berat.)
Sphinx
Seperti Elasticsearch, Sphinx juga menyediakan produk pencarian teks lengkap yang sangat solid:Craigslist melayani lebih dari 300.000.000 kueri per hari dengannya. Sphinx tidak menyediakan antarmuka RESTful asli. Ini diimplementasikan di C, dengan jejak perangkat keras yang lebih kecil daripada Elasticsearch (yang diimplementasikan di Java dan dapat berjalan di OS apa pun dengan jvm). Anda juga memerlukan akses root ke server dengan beberapa RAM/CPU khusus untuk menjalankan Sphinx dengan benar.
Pencarian Teks Lengkap MySQL
Secara historis, pencarian teks lengkap didukung di mesin MyISAM. Setelah versi 5.6, MySQL juga mendukung pencarian teks lengkap di mesin penyimpanan InnoDB. Ini adalah berita bagus, karena memungkinkan pengembang untuk mendapatkan keuntungan dari integritas referensial InnoDB, kemampuan untuk melakukan transaksi, dan kunci tingkat baris.
Pada dasarnya ada dua pendekatan untuk pencarian teks lengkap di MySQL:bahasa alami dan mode boolean. (Opsi ketiga menambah pencarian bahasa alami dengan kueri perluasan kedua.)
Perbedaan utama antara mode natural dan boolean adalah bahwa boolean mengizinkan operator tertentu sebagai bagian dari pencarian. Misalnya, operator boolean dapat digunakan jika sebuah kata memiliki relevansi yang lebih besar daripada yang lain dalam kueri atau jika kata tertentu harus ada dalam hasil, dll. Perlu diperhatikan bahwa dalam kedua kasus, hasil dapat diurutkan berdasarkan relevansi yang dihitung oleh MySQL selama pencarian.
Membuat Keputusan
Yang paling cocok untuk masalah kami adalah menggunakan pencarian teks lengkap InnoDb dalam mode boolean. Mengapa?
- Kami hanya punya sedikit waktu untuk mengimplementasikan fungsi pencarian.
- Pada titik ini, kami tidak memiliki data besar untuk diproses atau beban besar yang memerlukan sesuatu seperti Elasticsearch atau Sphinx.
- Kami menggunakan hosting bersama yang tidak mendukung Elasticsearch atau Sphinx dan perangkat kerasnya sangat terbatas pada tahap ini.
- Meskipun kami menginginkan kata yang berasal dari fungsi pencarian kami, itu bukan pemecah kesepakatan:kami dapat menerapkannya (dalam batasan) melalui beberapa pengkodean PHP sederhana dan denormalisasi data
- Penelusuran teks lengkap dalam mode boolean dapat menelusuri kata dengan karakter pengganti (untuk kata yang berasal dari kata) dan mengurutkan hasil berdasarkan relevansi.
Penelusuran Teks Lengkap dalam Mode Boolean
Seperti disebutkan sebelumnya, pencarian bahasa alami adalah pendekatan paling sederhana:cukup cari frasa atau kata di kolom tempat Anda telah menetapkan indeks teks lengkap dan Anda akan mendapatkan hasil yang diurutkan berdasarkan relevansi.
Dalam Model Vertabelo yang Dinormalisasi
Mari kita lihat bagaimana pencarian sederhana akan bekerja. Kami akan membuat tabel sampel terlebih dahulu:
-- Dibuat oleh Vertabelo (https://vertabelo.com)-- Tanggal modifikasi terakhir:25-04-2016 15:01:22.153-- tabel-- Tabel:artisCREATE TABLE artis ( id int(11) NOT NULL AUTO_INCREMENT, nama varchar(255) NOT NULL, bio text NOT NULL, CONSTRAINT Artists_pk PRIMARY KEY (id)) ENGINE InnoDB;CREATE FULLTEXT INDEX artis_idx_1 PADA artis (nama);-- Akhir file.
Dalam mode bahasa alami
Anda dapat memasukkan beberapa data sampel dan memulai pengujian. (Akan lebih baik untuk menambahkannya ke kumpulan data sampel Anda.) Misalnya, kami akan mencoba menelusuri Michael Jackson:
PILIH *FROM artistWHERE MATCH (artists.name) AGAINST ('Michael Jackson' DALAM MODE BAHASA ALAMI) Kueri ini akan menemukan catatan yang cocok dengan istilah pencarian dan akan mengurutkan catatan yang cocok menurut relevansinya; semakin baik kecocokannya, semakin relevan dan semakin tinggi hasilnya akan muncul dalam daftar.
Dalam mode boolean
Kami dapat melakukan pencarian yang sama dalam mode boolean. Jika kami tidak menerapkan operator apa pun ke kueri kami, satu-satunya perbedaan adalah hasil tidak diurutkan berdasarkan relevansi:
PILIH *FROM artistWHERE MATCH (artists.name) AGAINST ('Michael Jackson' DALAM MODE BOOLEAN) Operator wildcard dalam mode boolean
Karena kita ingin mencari kata-kata bertangkai dan sebagian, kita memerlukan operator wildcard (*). Operator ini dapat digunakan dalam pencarian mode boolean, itulah sebabnya kami memilih mode itu.
Jadi, mari kita lepaskan kekuatan pencarian boolean dan coba cari bagian dari nama artis. Kami akan menggunakan operator wildcard untuk mencocokkan artis mana pun yang namanya dimulai dengan 'Mich':
PILIH *FROM artisWHERE MATCH (nama) AGAINST ('Mich*' DALAM MODE BOOLEAN) Mengurutkan menurut relevansi dalam mode boolean
Sekarang mari kita lihat relevansi yang dihitung untuk pencarian. Ini akan membantu kita memahami penyortiran yang akan kita lakukan nanti dengan Cake:
PILIH *, MATCH (nama) AGAINST ('mich*' DALAM MODE BOOLEAN) SEBAGAI peringkatFROM artisWHERE MATCH (nama) AGAINST ('mich*' DALAM MODE BOOLEAN)ORDER BY rank DESC Kueri ini mengambil kecocokan penelusuran dan nilai relevansi yang dihitung MySQL untuk setiap catatan. Pengoptimal mesin akan mendeteksi bahwa kami memilih relevansi, sehingga tidak akan repot menghitung ulang peringkat.
Stemming Kata dalam Pencarian Teks Lengkap
Saat kami memasukkan kata yang berasal dari pencarian, pencarian menjadi lebih ramah pengguna. Bahkan jika hasilnya bukan kata itu sendiri, algoritma mencoba menghasilkan akar yang sama untuk kata turunan. Misalnya, kata dasar “argu” bukanlah kata bahasa Inggris, tetapi dapat digunakan sebagai kata dasar untuk kata “argue”, “argued”, “argues”, “arguing”, “Argus” dan lainnya.
Stemming meningkatkan hasil, karena pengguna dapat memasukkan kata yang tidak memiliki kecocokan persis tetapi "batang"-nya. Meskipun stemmer PHP atau stemmer Python Snowball bisa menjadi pilihan (jika Anda memiliki akses root SSH ke server Anda), kami akan menggunakan kelas PorterStemmer.php.
Kelas ini mengimplementasikan algoritma yang diusulkan oleh Martin Porter untuk membendung kata dalam bahasa Inggris. Seperti yang dinyatakan oleh penulis di situs webnya, gratis digunakan untuk tujuan apa pun. Cukup letakkan file di dalam direktori Vendor Anda di dalam CakePHP, sertakan perpustakaan dalam model Anda, dan panggil metode statis untuk membendung kata:
//include library (harus disebut PorterStemmer.php) di dalam folder Vendor CakePHPApp::import('Vendor', 'PorterStemmer'); //stem kata (kata harus di-stem satu per satu)echo PorterStemmer::Stem('stemming'); //output akan menjadi 'batang' Tujuan kami adalah membuat penelusuran menjadi cepat dan efisien serta dapat mengurutkan hasil menurut relevansi teks lengkapnya. Untuk melakukan ini, kita perlu menggunakan kata dasar dalam dua cara:
- Kata-kata yang dimasukkan oleh pengguna
- Data terkait lagu (yang akan kami simpan dalam kolom dan urutkan untuk hasil berdasarkan relevansi)
Jenis pertama dari kata stemming dapat dilakukan seperti ini:
Aplikasi::import('Vendor', 'PorterStemmer');$search =trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));/ /hapus karakter yang tidak diinginkan$words =meledak(" ", trim($search));$stemmedSearch ="";$unstemmedSearch ="";foreach ($words as $word) { $stemmedSearch .=PorterStemmer::Stem($ kata) . "* ";//kami menambahkan wildcard setelah setiap kata $unstemmedSearch =$word . "* ";//untuk mencari kolom artis yang tidak bertangkai}$stemmedSearch =trim($stemmedSearch);$unstemmedSearch =trim($unstemmedSearch);if ($stemmedSearch =="*" || $unstemmedSearch==" *") { //jika tidak, mySql akan mengeluh, karena Anda tidak dapat menggunakan wildcard saja $stemmedSearch =""; $unstemmedSearch ="";} Kami telah membuat dua string:satu untuk mencari nama artis (tanpa stemming), dan satu untuk mencari di kolom stem lainnya. Ini akan membantu kami nantinya membangun 'melawan' bagian dari kueri teks lengkap. Sekarang mari kita lihat bagaimana kita dapat membendung dan mengurutkan data lagu.
Mendenormalisasi Data Lagu
Kriteria penyortiran kami akan didasarkan pada pencocokan artis lagu (tanpa stemming) terlebih dahulu. Selanjutnya akan muncul nama lagu, album, dan kategori terkait. Stemming akan digunakan pada semua kriteria pencarian sekunder.
Untuk mengilustrasikannya, misalkan saya mencari 'nirwana' dan ada lagu berjudul 'Nirvana Games' oleh 'XYZ', dan lagu lain berjudul 'Polly' oleh artis 'Nirvana'. Hasil harus mencantumkan 'Polly' terlebih dahulu, karena kecocokan nama artis lebih penting daripada kecocokan nama lagu (berdasarkan kriteria saya).
Untuk melakukan ini, saya menambahkan 4 bidang di songs tabel, satu untuk setiap kriteria pencarian/penyortiran yang kita inginkan:
ALTER TABLE `songs` ADD `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD `denorm_album` VARCHAR(255) NOT NULL denorm_trackname`,ADD `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, ADD FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album`), ADD FULLTEXT(`denorm_categories`);
Model database lengkap kami akan terlihat seperti ini:
Setiap kali Anda menyimpan lagu menggunakan add/edit di CakePHP, Anda hanya perlu menyimpan nama artis di kolom denorm_artist tanpa membendungnya. Selanjutnya, tambahkan nama trek bertangkai di denorm_trackname (mirip dengan apa yang kami lakukan di teks yang dicari) dan simpan nama album bertangkai di denorm_album kolom. Terakhir, simpan set kategori bertangkai untuk lagu di denorm_categories bidang, menggabungkan kata-kata dan menambahkan satu spasi di antara setiap nama kategori bertangkai.
Pencarian Teks Lengkap dan Penyortiran Relevansi di CakePHP
Melanjutkan contoh pencarian 'Nirvana', mari kita lihat apa yang dapat dicapai oleh kueri serupa ini:
SELECT trackname, MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) sebagai rank1, MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) sebagai rank2, MATCH(denorm_album) AGAINST ('Nirvana*' DALAM MODE BOOLEAN) sebagai peringkat3, MATCH(denorm_categories) MELAWAN ('Nirvana*' DALAM MODE BOOLEAN) sebagai peringkat4 FROM lagu WHERE MATCH(denorm_artist) AGAINST ('Nirvana*' DALAM MODE BOOLEAN) ATAU MATCH(denorm_trackname') LAGI ' DALAM MODE BOOLEAN) ATAU COCOK(denorm_album) MELAWAN ('Nirvana*' DALAM MODE BOOLEAN) ATAU MATCH(denorm_categories) MELAWAN ('Nirvana*' DALAM MODE BOOLEAN) ORDER OLEH peringkat1 DESC, peringkat2 DESC, peringkat3 DESC, peringkat4 DESC Kami akan mendapatkan output berikut:
| nama trek | peringkat1 | peringkat2 | peringkat3 | peringkat4 |
| Poly | 0.0906190574169159 | 0 | 0 | 0 |
| permainan nirwana | 0 | 0.0906190574169159 | 0 | 0 |
Untuk melakukannya di CakePHP, temukan metode harus dipanggil menggunakan kombinasi parameter 'bidang', 'kondisi', dan 'urutan'. Melanjutkan kode contoh PHP sebelumnya:
//di dalam file model Song.php $fields =array( "Song.trackname", "MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} DALAM MODE BOOLEAN) sebagai `rank1`", "MATCH(Song. denorm_trackname) MELAWAN ({$stemmedSearch} DALAM MODE BOOLEAN) sebagai `rank2`", "MATCH(Song.denorm_album) MELAWAN ({$stemmedSearch} DALAM MODE BOOLEAN) sebagai `rank3`", "MATCH(Song.denorm_categories) MELAWAN ( {$stemmedSearch} DALAM MODE BOOLEAN) sebagai `rank4`" );$order ="`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";$conditions =array( "ATAU" => array( "MATCH(Song.denorm_artist) MELAWAN ({$unstemmedSearch} DALAM MODE BOOLEAN)", "MATCH(Song.denorm_trackname) TERHADAP ({$stemmedSearch} DALAM MODE BOOLEAN)", "MATCH(Lagu. denorm_album) AGAINST ({$stemmedSearch} DALAM MODE BOOLEAN)", "MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} DALAM MODE BOOLEAN)" ) );$results =$this->find ('all',array('conditions'=>$conditions,'fields'=>$fields,'order'=>$order); $results akan menjadi susunan lagu yang diurutkan dengan kriteria yang telah kita tentukan sebelumnya.
Solusi ini dapat digunakan untuk menghasilkan pencarian yang berarti bagi pengguna – tanpa memerlukan terlalu banyak waktu dari pengembang atau menambahkan kerumitan besar pada kode.
Menjadikan Pencarian CakePHP Lebih Baik
Perlu disebutkan bahwa “membubuhi” kolom yang didenormalisasi dengan lebih banyak data dapat memberikan hasil yang lebih baik.
Yang saya maksud dengan "membubuhi" adalah Anda dapat memasukkan, ke dalam kolom yang didenormalisasi, lebih banyak data dari kolom tambahan yang Anda anggap berguna dengan tujuan membuat hasil lebih relevan, misalnya jika Anda tahu bahwa negara artis dapat ditemukan dalam istilah pencarian, Anda bisa menambahkan negara beserta nama artis di denorm_artist kolom. Ini akan meningkatkan kualitas hasil pencarian.
Dari pengalaman saya (tergantung pada data aktual yang Anda gunakan dan kolom yang Anda denormalisasi) hasil teratas cenderung sangat akurat. Ini bagus untuk aplikasi seluler, karena menggulir daftar panjang ke bawah dapat membuat pengguna frustasi.
Terakhir, jika Anda perlu mendapatkan lebih banyak data dari tabel yang terkait dengan lagu tersebut, Anda selalu dapat bergabung dan mendapatkan artis, kategori, album, komentar lagu, dll. Jika Anda menggunakan filter perilaku yang dapat ditampung CakePHP, saya akan menyarankan untuk menambahkan plugin EagerLoader untuk menyelesaikan penggabungan secara efisien.
Jika Anda memiliki pendekatan sendiri untuk menerapkan pencarian teks lengkap, silakan bagikan dalam komentar di bawah. Kita semua bisa belajar dari pengalaman satu sama lain.