Dalam posting blog ini, kita akan melihat beberapa metrik dan status utama saat memantau Server Percona untuk MySQL untuk membantu kita menyempurnakan konfigurasi server MySQL untuk jangka panjang. Sebagai informasi, Server Percona memiliki beberapa metrik pemantauan yang hanya tersedia di build ini. Saat membandingkan pada versi 8.0.20, 51 status berikut hanya tersedia di Server Percona untuk MySQL, yang tidak tersedia di Server Komunitas MySQL Oracle hulu:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Lihat halaman Status InnoDB yang Diperluas untuk informasi lebih lanjut tentang setiap metrik pemantauan di atas. Perhatikan bahwa beberapa status tambahan seperti kumpulan utas hanya tersedia di Oracle's MySQL Enterprise. Lihat dokumentasi Percona Server for MySQL 8.0 untuk melihat semua peningkatan khusus untuk build ini melalui Oracle's MySQL Community Server 8.0.
Untuk mengambil status global MySQL, cukup gunakan salah satu pernyataan berikut:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Status dan Ikhtisar Basis Data
Kami akan mulai dengan status uptime, jumlah detik server telah menyala.
Semua status com_* adalah variabel penghitung pernyataan yang menunjukkan berapa kali setiap pernyataan telah dieksekusi. Ada satu variabel status untuk setiap jenis pernyataan. Misalnya, com_delete dan com_update masing-masing menghitung pernyataan DELETE dan UPDATE. com_delete_multi dan com_update_multi serupa tetapi berlaku untuk pernyataan DELETE dan UPDATE yang menggunakan sintaks beberapa tabel.
Untuk membuat daftar semua proses yang berjalan oleh MySQL, jalankan salah satu dari pernyataan berikut:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Koneksi dan Utas
Koneksi Saat Ini
Rasio koneksi yang saat ini terbuka (utas koneksi). Jika rasionya tinggi, ini menunjukkan ada banyak koneksi bersamaan ke server MySQL dan dapat menyebabkan kesalahan "Terlalu banyak koneksi". Untuk mendapatkan persentase koneksi:
Current connections(%) = (threads_connected / max_connections) x 100Nilai yang baik harus 80% ke bawah. Coba tingkatkan variabel max_connections atau periksa koneksi menggunakan SHOW FULL PROCESSLIST. Ketika kesalahan "Terlalu banyak koneksi" terjadi, server database MySQL akan menjadi tidak tersedia untuk pengguna non-super sampai beberapa koneksi dibebaskan. Perhatikan bahwa meningkatkan variabel max_connections juga berpotensi meningkatkan jejak memori MySQL.
Koneksi Maksimum yang Pernah Terlihat
Rasio koneksi maksimum ke server MySQL yang pernah dilihat. Perhitungan sederhananya adalah:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100Nilai yang baik harus di bawah 80%. Jika rasionya tinggi, ini menunjukkan bahwa MySQL pernah mencapai jumlah koneksi yang tinggi yang akan menyebabkan kesalahan 'terlalu banyak koneksi'. Periksa rasio koneksi saat ini untuk melihat apakah rasio koneksi tetap rendah secara konsisten. Jika tidak, tambah variabel max_connections. Periksa status max_used_connections_time untuk menunjukkan kapan status max_used_connections mencapai nilai saat ini.
Rasio Hit Tembolok Utas
Status threads_created adalah jumlah utas yang dibuat untuk menangani koneksi. Jika threads_created besar, Anda mungkin ingin meningkatkan nilai thread_cache_size. Tingkat hit/miss cache dapat dihitung sebagai:
Threads cache hit rate (%) = (threads_created / connections) x 100Ini adalah pecahan yang memberikan indikasi tingkat hit cache thread. Semakin dekat kurang dari 50%, semakin baik. Jika server Anda melihat ratusan koneksi per detik, Anda biasanya harus menyetel thread_cache_size cukup tinggi sehingga sebagian besar koneksi baru menggunakan utas yang di-cache.
Kinerja Kueri
Pemindaian Tabel Lengkap
Rasio pemindaian tabel penuh, operasi yang mengharuskan membaca seluruh isi tabel, bukan hanya bagian yang dipilih menggunakan indeks. Nilai ini tinggi jika Anda melakukan banyak kueri yang memerlukan pengurutan hasil atau pemindaian tabel. Umumnya, ini menunjukkan bahwa tabel tidak diindeks dengan benar atau kueri Anda tidak ditulis untuk memanfaatkan indeks yang Anda miliki. Untuk menghitung persentase pemindaian tabel penuh:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100Nilai yang baik harus di bawah 25%. Periksa output log kueri lambat MySQL untuk menemukan kueri yang kurang optimal.
Pilih Gabung Penuh
Status select_full_join adalah jumlah gabungan yang melakukan pemindaian tabel karena tidak menggunakan indeks. Jika nilai ini bukan 0, Anda harus hati-hati memeriksa indeks tabel Anda.
Pilih Pemeriksaan Jangkauan
Status select_range_check adalah jumlah gabungan tanpa kunci yang memeriksa penggunaan kunci setelah setiap baris. Jika ini bukan 0, Anda harus hati-hati memeriksa indeks tabel Anda.
Urutkan Pass
Rasio penggabungan melewati yang harus dilakukan oleh algoritma pengurutan. Jika nilai ini tinggi, Anda harus mempertimbangkan untuk meningkatkan nilai sort_buffer_size dan read_rnd_buffer_size. Perhitungan rasio sederhana adalah:
Sort passes = sort_merge_passes / (sort_scan + sort_range)Nilai rasio yang lebih rendah dari 3 seharusnya merupakan nilai yang baik. Jika Anda ingin meningkatkan sort_buffer_size atau read_rnd_buffer_size, coba tingkatkan sedikit demi sedikit hingga Anda mencapai rasio yang dapat diterima.
Kinerja InnoDB
Rasio Hit Pangkalan Buffer InnoDB
Rasio seberapa sering halaman Anda diambil dari memori, bukan dari disk. Jika nilainya rendah selama startup MySQL awal, harap tunggu beberapa saat hingga buffer pool menjadi hangat. Untuk mendapatkan hit rate kumpulan buffer, gunakan pernyataan SHOW ENGINE INNODB STATUS:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...Nilai terbaik adalah 1000/10000 hit rate. Untuk nilai yang lebih rendah, misalnya, hit rate 986/1000 menunjukkan bahwa dari 1000 halaman yang dibaca, ia mampu membaca halaman di RAM sebanyak 986 kali. Sisanya 14 kali, MySQL harus membaca halaman dari disk. Sederhananya, 1000 / 1000 adalah nilai terbaik yang kami coba capai di sini, yang berarti data yang sering diakses sepenuhnya sesuai dengan RAM.
Meningkatkan variabel innodb_buffer_pool_size akan banyak membantu untuk mengakomodasi lebih banyak ruang bagi MySQL untuk bekerja. Namun, pastikan Anda memiliki sumber daya RAM yang cukup sebelumnya. Menghapus indeks yang berlebihan juga bisa membantu. Jika Anda memiliki beberapa instans kumpulan buffer, pastikan hit rate untuk setiap instans mencapai 1000 / 1000.
Halaman Kotor InnoDB
Rasio seberapa sering InnoDB perlu di-flush. Selama beban tulis-berat, adalah normal jika persentase ini meningkat.
Perhitungan sederhananya adalah:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Nilai yang baik harus 75% ke bawah. Jika persentase halaman kotor tetap tinggi untuk waktu yang lama, Anda mungkin ingin menambah kumpulan buffer atau mendapatkan disk yang lebih cepat untuk menghindari kemacetan kinerja.
InnoDB Menunggu Pos Pemeriksaan
Rasio seberapa sering InnoDB perlu membaca atau membuat halaman di mana tidak ada halaman bersih yang tersedia. Biasanya, penulisan ke InnoDB Buffer Pool terjadi di latar belakang. Namun, jika perlu membaca atau membuat halaman dan tidak ada halaman bersih yang tersedia, Anda juga perlu menunggu halaman di-flush terlebih dahulu. Penghitung innodb_buffer_pool_wait_free menghitung berapa kali ini terjadi. Untuk menghitung rasio InnoDB menunggu checkpointing, kita dapat menggunakan perhitungan berikut:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsJika innodb_buffer_pool_wait_free lebih besar dari 0, ini merupakan indikator kuat bahwa kumpulan buffer InnoDB terlalu kecil, dan operasi harus menunggu di pos pemeriksaan. Meningkatkan innodb_buffer_pool_size biasanya akan menurunkan innodb_buffer_pool_wait_free, serta rasio ini. Nilai rasio yang baik harus tetap di bawah 1.
InnoDB Menunggu Redolog
Rasio redo log contention. Centang innodb_log_waits dan jika terus bertambah maka naikkan innodb_log_buffer_size. Ini juga dapat berarti bahwa disk terlalu lambat dan tidak dapat mempertahankan IO disk, mungkin karena beban tulis puncak. Gunakan perhitungan berikut untuk menghitung rasio tunggu redo log:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesNilai rasio yang baik harus di bawah 1. Jika tidak, tingkatkan innodb_log_buffer_size.
Tabel
Penggunaan Cache Tabel
Rasio penggunaan cache tabel untuk semua utas. Perhitungan sederhananya adalah:
Table cache usage(%) = (opened_tables / table_open_cache) x 100Nilai bagus harus kurang dari 80%. Tingkatkan variabel table_open_cache hingga persentase mencapai nilai yang baik.
Rasio Hit Cache Tabel
Rasio penggunaan cache tabel hit. Perhitungan sederhananya adalah:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Nilai rasio hit yang baik harus 90% ke atas. Jika tidak, tingkatkan variabel table_open_cache hingga rasio klik mencapai nilai yang baik.
Pemantauan Metrik dengan ClusterControl
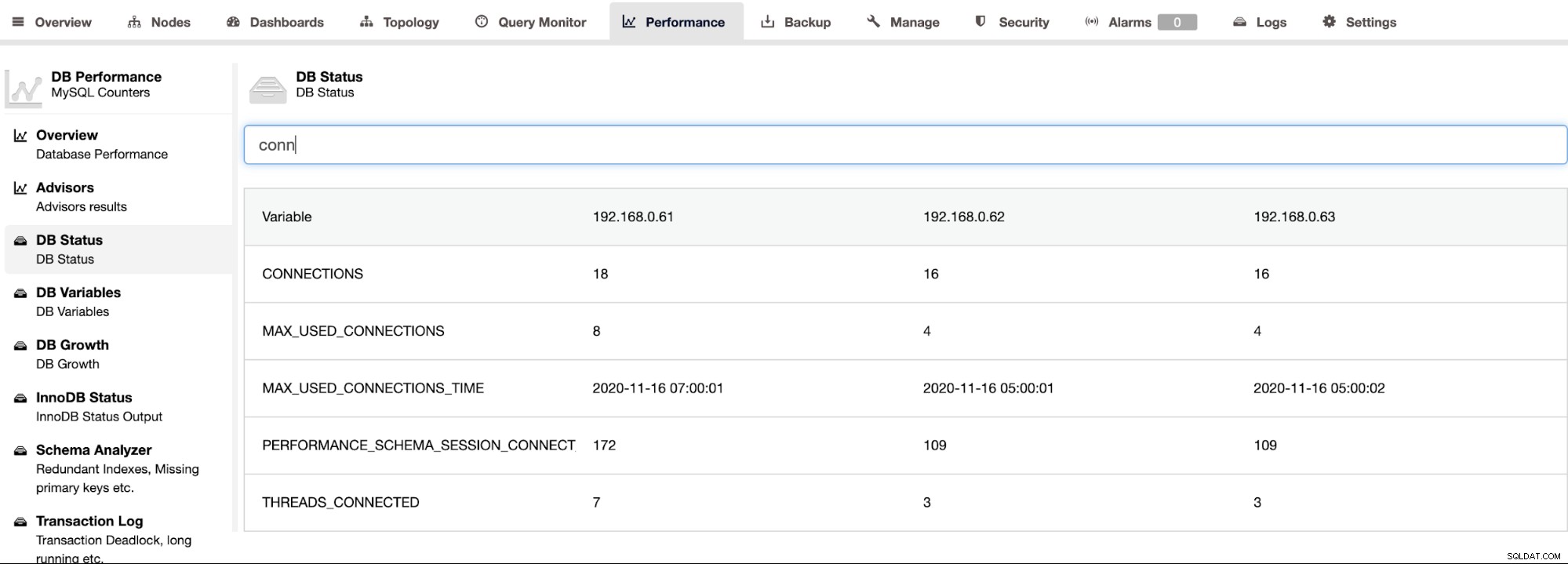
ClusterControl mendukung Percona Server untuk MySQL dan menyediakan tampilan agregat dari semua node dalam sebuah cluster di bawah halaman ClusterControl -> Performance -> DB Status. Ini memberikan pendekatan terpusat untuk mencari semua status di semua host dengan kemampuan untuk memfilter status, seperti yang ditunjukkan pada tangkapan layar berikut:
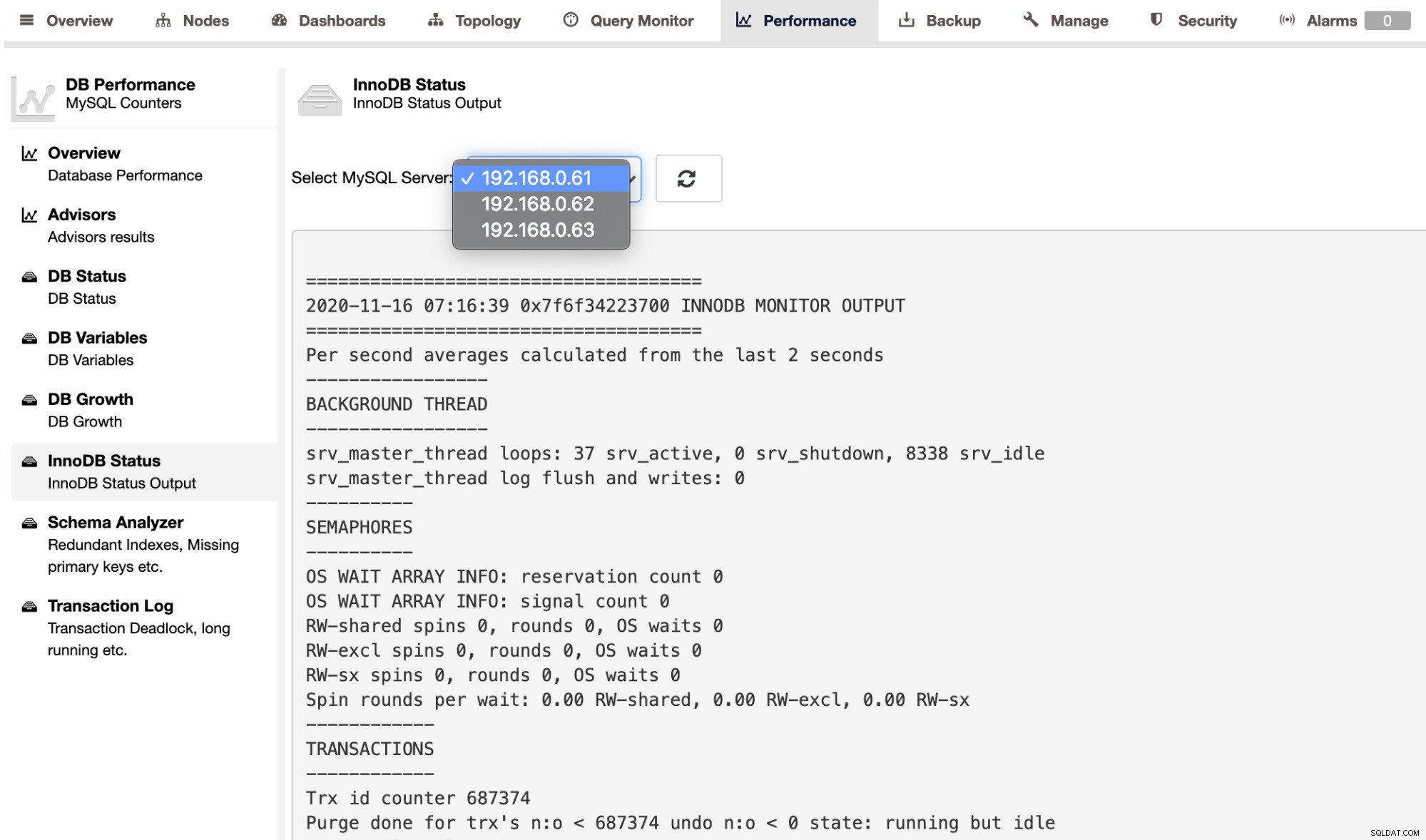
Untuk mengambil output SHOW ENGINE INNODB STATUS untuk server individual, Anda dapat gunakan halaman Performance -> InnoDB Status, seperti gambar di bawah ini:
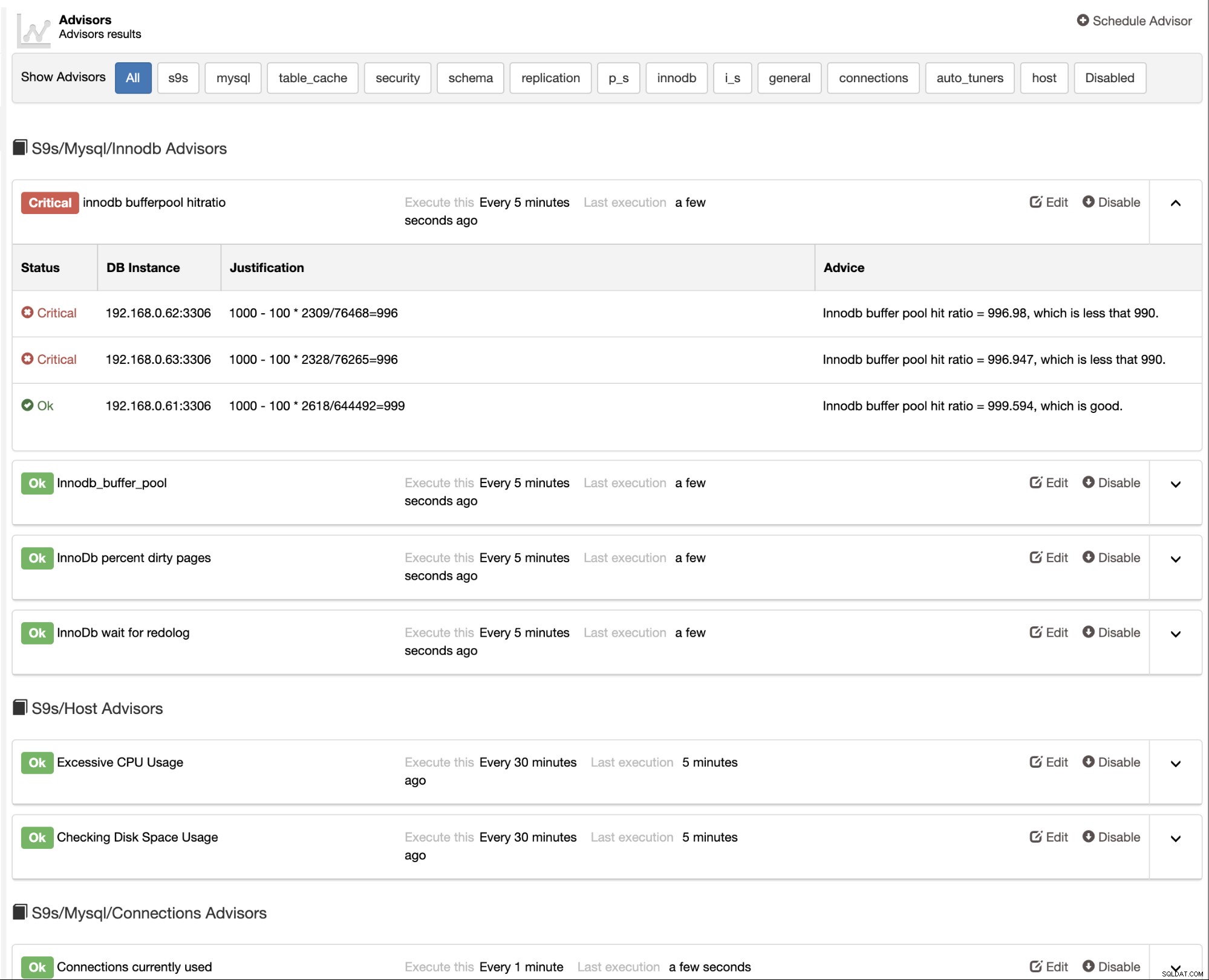
ClusterControl juga menyediakan penasihat bawaan yang dapat Anda gunakan untuk melacak basis data Anda pertunjukan. Fitur ini dapat diakses di bawah ClusterControl -> Performance -> Advisors:
Penasihat pada dasarnya adalah program mini yang dijalankan oleh ClusterControl dalam waktu yang dijadwalkan seperti cron pekerjaan. Anda dapat menjadwalkan penasihat dengan mengklik tombol "Jadwalkan Penasihat", dan memilih penasihat yang ada dari pohon objek Developer Studio:
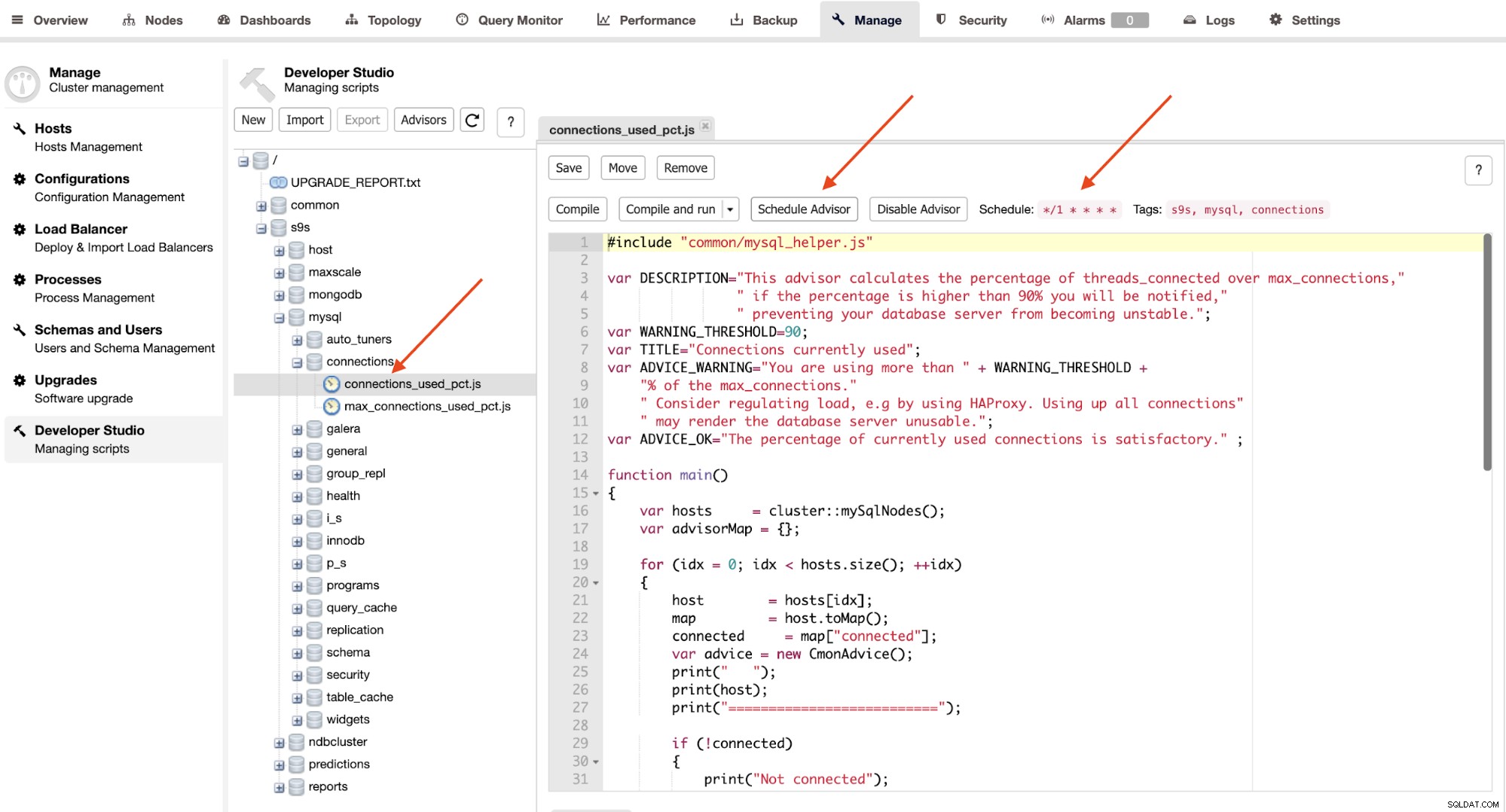
Klik tombol "Schedule Advisor" untuk mengatur penjadwalan, argumen ke lulus dan juga tag penasihat. Anda juga dapat mengompilasi penasehat untuk melihat output segera dengan mengklik tombol "Kompilasi dan jalankan", di mana Anda akan melihat output berikut di bawah "Pesan" di bawahnya:

Anda dapat membuat penasihat sendiri dengan merujuk ke Panduan Pengembang ini, yang ditulis dalam Bahasa Khusus Domain ClusterControl (sangat mirip dengan Javascript), atau sesuaikan penasihat yang ada agar sesuai dengan kebijakan pemantauan Anda. Singkatnya, tugas pemantauan ClusterControl dapat diperpanjang dengan kemungkinan tak terbatas melalui ClusterControl Advisors.