Saat ini, database yang tersebar di beberapa cloud cukup umum. Mereka menjanjikan ketersediaan tinggi dan kemungkinan untuk dengan mudah menerapkan prosedur pemulihan bencana. Mereka juga merupakan metode untuk menghindari penguncian vendor:jika Anda mendesain lingkungan database Anda sehingga dapat beroperasi di beberapa penyedia cloud, kemungkinan besar Anda tidak terikat pada fitur dan implementasi khusus untuk satu penyedia tertentu. Ini memudahkan Anda untuk menambahkan penyedia infrastruktur lain ke lingkungan Anda, baik itu cloud lain atau penyiapan lokal. Fleksibilitas tersebut sangat penting mengingat ada persaingan ketat antara penyedia cloud dan migrasi dari satu ke yang lain mungkin cukup layak jika didukung dengan pengurangan biaya.
Mencakup infrastruktur Anda di beberapa pusat data (dari penyedia yang sama atau tidak, itu tidak masalah) membawa masalah serius untuk dipecahkan. Bagaimana seseorang dapat mendesain seluruh infrastruktur sedemikian rupa sehingga data akan aman? Bagaimana menghadapi tantangan yang harus Anda hadapi saat bekerja di lingkungan multi-cloud? Di blog ini kita akan melihat satu, tapi bisa dibilang yang paling serius - potensi otak terbelah. Apa artinya? Mari kita gali sedikit tentang apa itu otak terbelah.
Apa itu "Otak Terpisah"?
Split-brain adalah kondisi di mana lingkungan yang terdiri dari beberapa node mengalami partisi jaringan dan telah dipecah menjadi beberapa segmen yang tidak memiliki kontak satu sama lain. Kasus paling sederhana akan terlihat seperti ini:
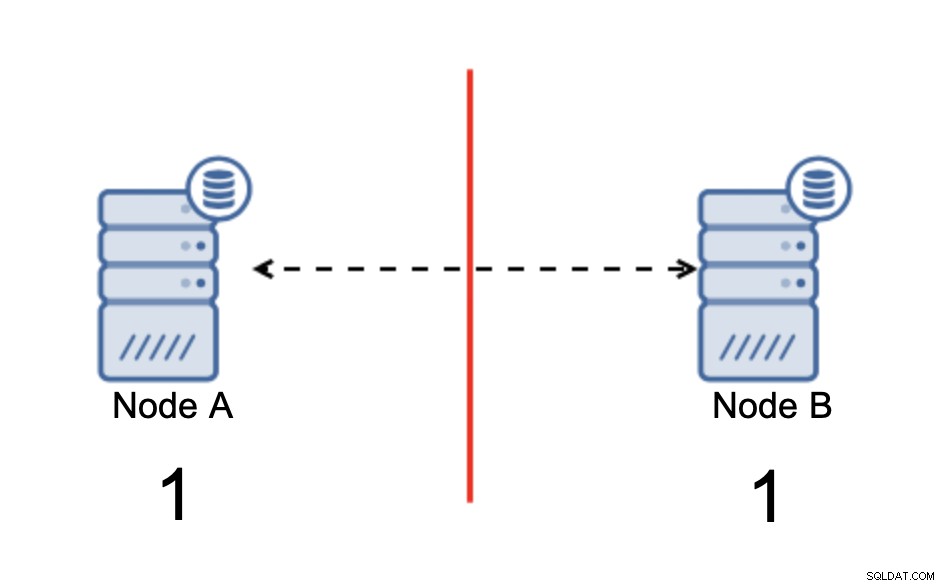
Kami memiliki dua node, A dan B, terhubung melalui jaringan menggunakan bi -replikasi asinkron arah. Kemudian koneksi jaringan terputus antara node tersebut. Akibatnya, kedua node tidak dapat terhubung satu sama lain dan setiap perubahan yang dilakukan pada node A tidak dapat ditransmisikan ke node B dan sebaliknya. Kedua node, A dan B, aktif dan menerima koneksi, mereka tidak dapat bertukar data. Hal ini dapat menyebabkan masalah serius karena aplikasi dapat membuat perubahan pada kedua node yang mengharapkan untuk melihat status penuh dari database sementara, pada kenyataannya, itu hanya beroperasi pada status data yang diketahui sebagian. Akibatnya, tindakan yang salah dapat diambil oleh aplikasi, hasil yang salah dapat disajikan kepada pengguna, dan seterusnya. Kami pikir jelas bahwa otak terbelah berpotensi menjadi kondisi yang sangat berbahaya dan salah satu prioritasnya adalah menanganinya sampai batas tertentu. Apa yang bisa dilakukan?
Cara Menghindari Otak Terbelah
Singkatnya, itu tergantung. Masalah utama yang harus dihadapi adalah kenyataan bahwa node aktif dan berjalan tetapi tidak memiliki konektivitas di antara mereka sehingga mereka tidak mengetahui keadaan node lainnya. Secara umum, replikasi asinkron MySQL tidak memiliki mekanisme apa pun yang secara internal akan memecahkan masalah otak terbelah. Anda dapat mencoba menerapkan beberapa solusi yang membantu Anda menghindari otak terbelah, tetapi solusi tersebut memiliki keterbatasan atau masih belum sepenuhnya menyelesaikan masalah.
Saat kami menjauh dari replikasi asinkron, segalanya terlihat berbeda. MySQL Group Replication dan MySQL Galera Cluster adalah teknologi yang memanfaatkan kesadaran cluster build-it. Kedua solusi tersebut menjaga komunikasi antar node dan memastikan bahwa cluster mengetahui keadaan node. Mereka menerapkan mekanisme kuorum yang mengatur apakah cluster dapat beroperasi atau tidak.
Mari kita bahas kedua solusi tersebut (replikasi asinkron dan cluster berbasis kuorum) secara lebih rinci.
Pengelompokan Berbasis Kuorum
Kami tidak akan membahas perbedaan implementasi antara MySQL Galera Cluster dan MySQL Group Replication, kami akan fokus pada ide dasar di balik pendekatan berbasis kuorum dan bagaimana ia dirancang untuk memecahkan masalah split-brain di cluster Anda.
Intinya adalah bahwa:cluster, untuk beroperasi, membutuhkan sebagian besar node yang tersedia. Dengan persyaratan ini, kita dapat yakin bahwa minoritas tidak akan pernah benar-benar mempengaruhi cluster lainnya karena minoritas tidak boleh melakukan tindakan apa pun. Ini juga berarti bahwa, untuk dapat menangani kegagalan satu node, sebuah cluster harus memiliki setidaknya tiga node. Jika Anda hanya memiliki dua node:
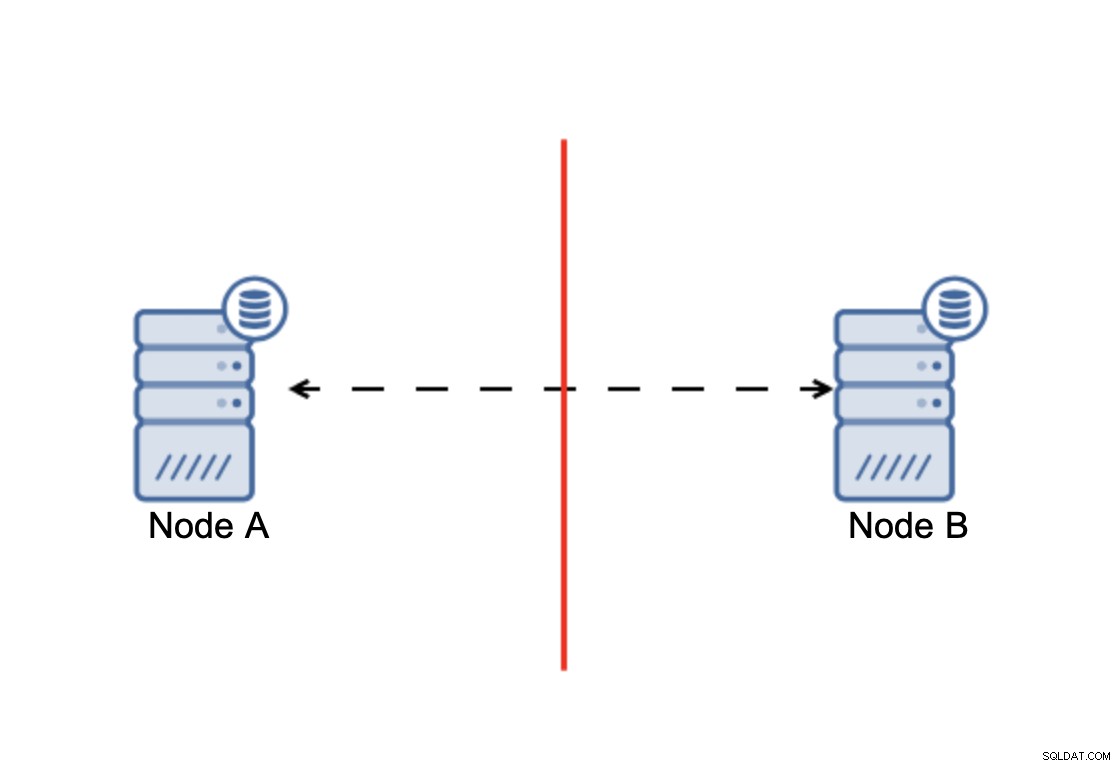
Bila ada pemisahan jaringan, Anda akan mendapatkan dua bagian cluster, masing-masing terdiri dari tepat 50% dari total node dalam cluster. Tak satu pun dari bagian ini memiliki mayoritas. Namun, jika Anda memiliki tiga simpul, semuanya berbeda:
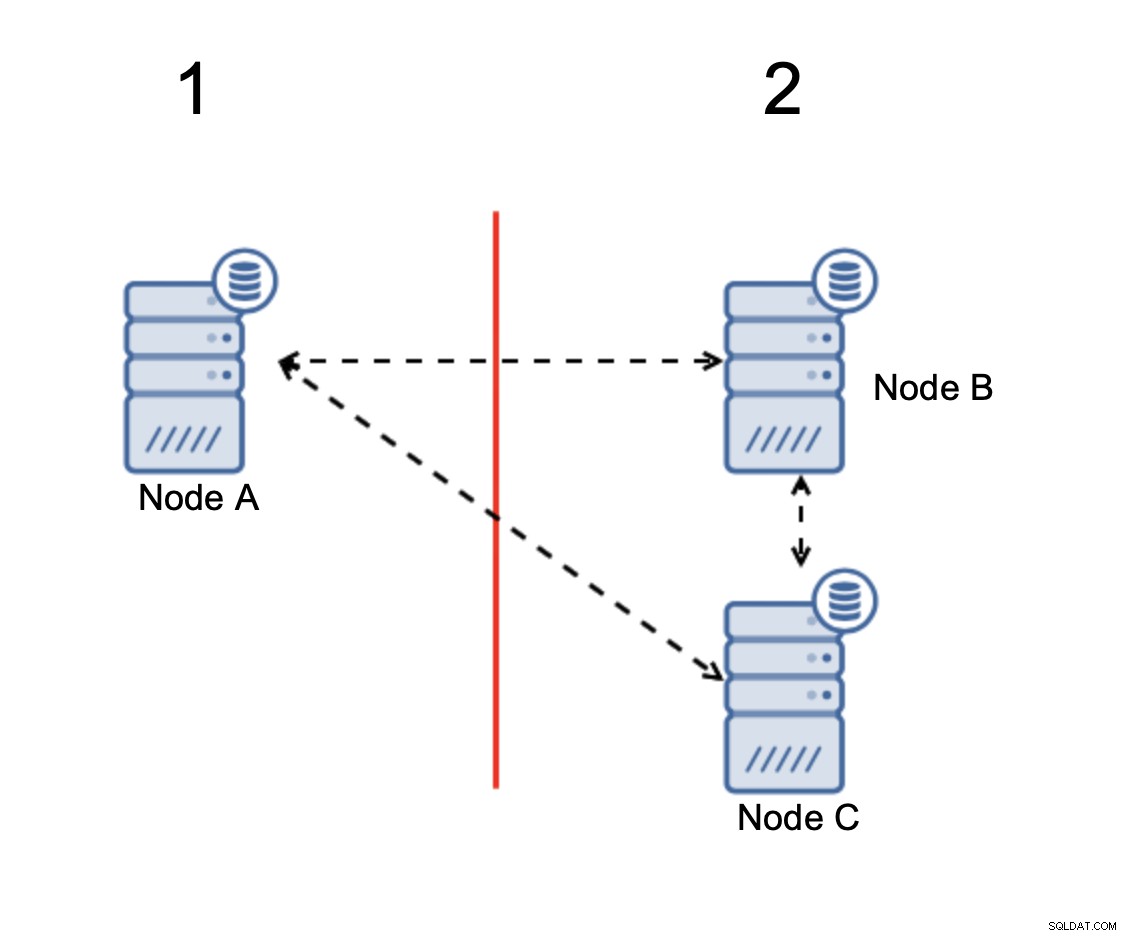
Node B dan C memiliki mayoritas:bagian itu terdiri dari dua node keluar dari tiga sehingga dapat terus beroperasi. Di sisi lain, node A hanya mewakili 33% dari node dalam cluster sehingga tidak memiliki mayoritas dan akan berhenti menangani lalu lintas untuk menghindari split brain.
Dengan implementasi seperti itu, split-brain sangat tidak mungkin terjadi (itu harus diperkenalkan melalui beberapa keadaan jaringan yang aneh dan tidak terduga, kondisi balapan atau bug dalam kode pengelompokan. Meskipun bukan tidak mungkin untuk ditemui kondisi seperti itu, menggunakan salah satu solusi yang berbasis kuorum adalah pilihan terbaik untuk menghindari perpecahan otak yang ada saat ini.
Replikasi Asinkron
Meskipun bukan pilihan ideal untuk menangani split-brain, replikasi asinkron masih merupakan pilihan yang layak. Ada beberapa hal yang harus Anda pertimbangkan sebelum menerapkan database multi-cloud dengan replikasi asinkron.
Pertama, failover. Replikasi asinkron dilengkapi dengan satu penulis - hanya master yang dapat ditulis dan node lain hanya boleh melayani lalu lintas baca-saja. Tantangannya adalah bagaimana menghadapi kegagalan master?
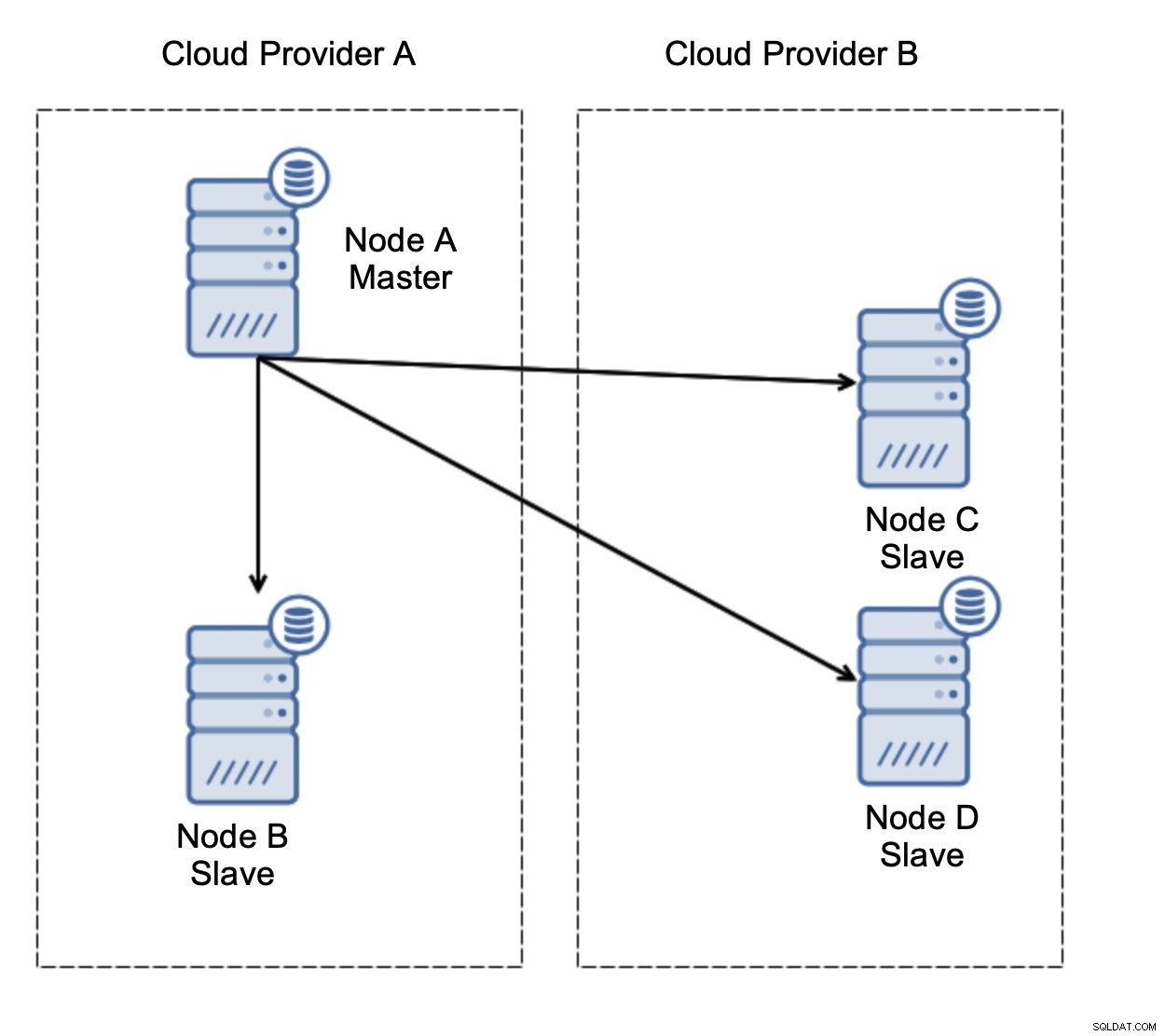
Mari kita pertimbangkan pengaturan seperti pada diagram di atas. Kami memiliki dua penyedia cloud, masing-masing dua node. Penyedia A menghosting juga master. Apa yang harus terjadi jika master gagal? Salah satu budak harus dipromosikan untuk memastikan bahwa database akan terus beroperasi. Idealnya, ini harus menjadi proses otomatis untuk mengurangi waktu yang dibutuhkan untuk membawa database ke keadaan operasional. Namun, apa yang akan terjadi jika ada partisi jaringan? Bagaimana kita diharapkan untuk memverifikasi status cluster?
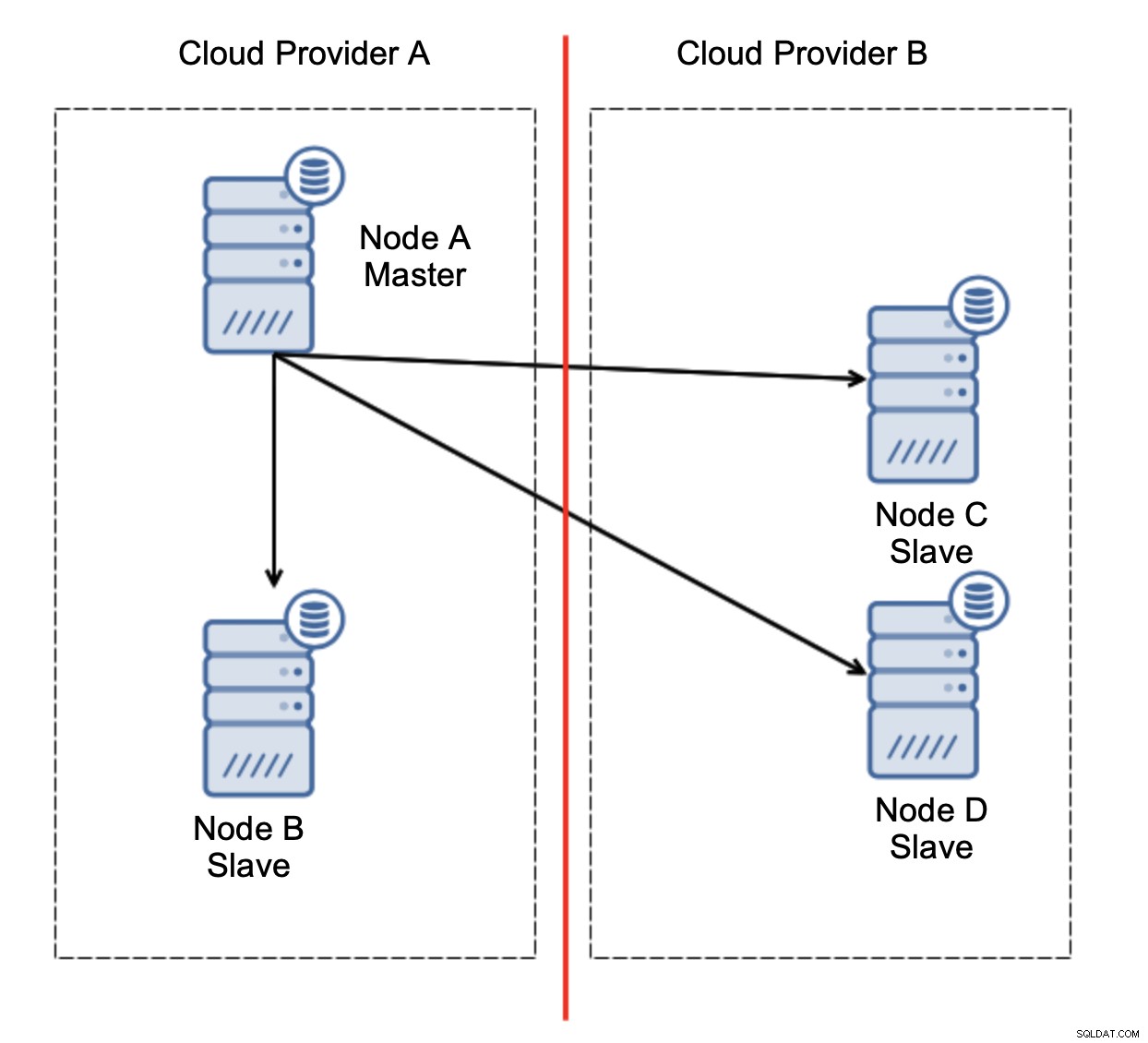
Inilah tantangannya. Konektivitas jaringan hilang antara dua penyedia cloud. Dari sudut pandang node C dan D baik node B dan master, node A offline. Haruskah node C atau D dipromosikan menjadi master? Tetapi master lama masih aktif - tidak macet, hanya tidak dapat dijangkau melalui jaringan. Jika kami akan mempromosikan salah satu node yang terletak di penyedia B, kami akan mendapatkan dua master yang dapat ditulis, dua set data, dan otak terpisah:
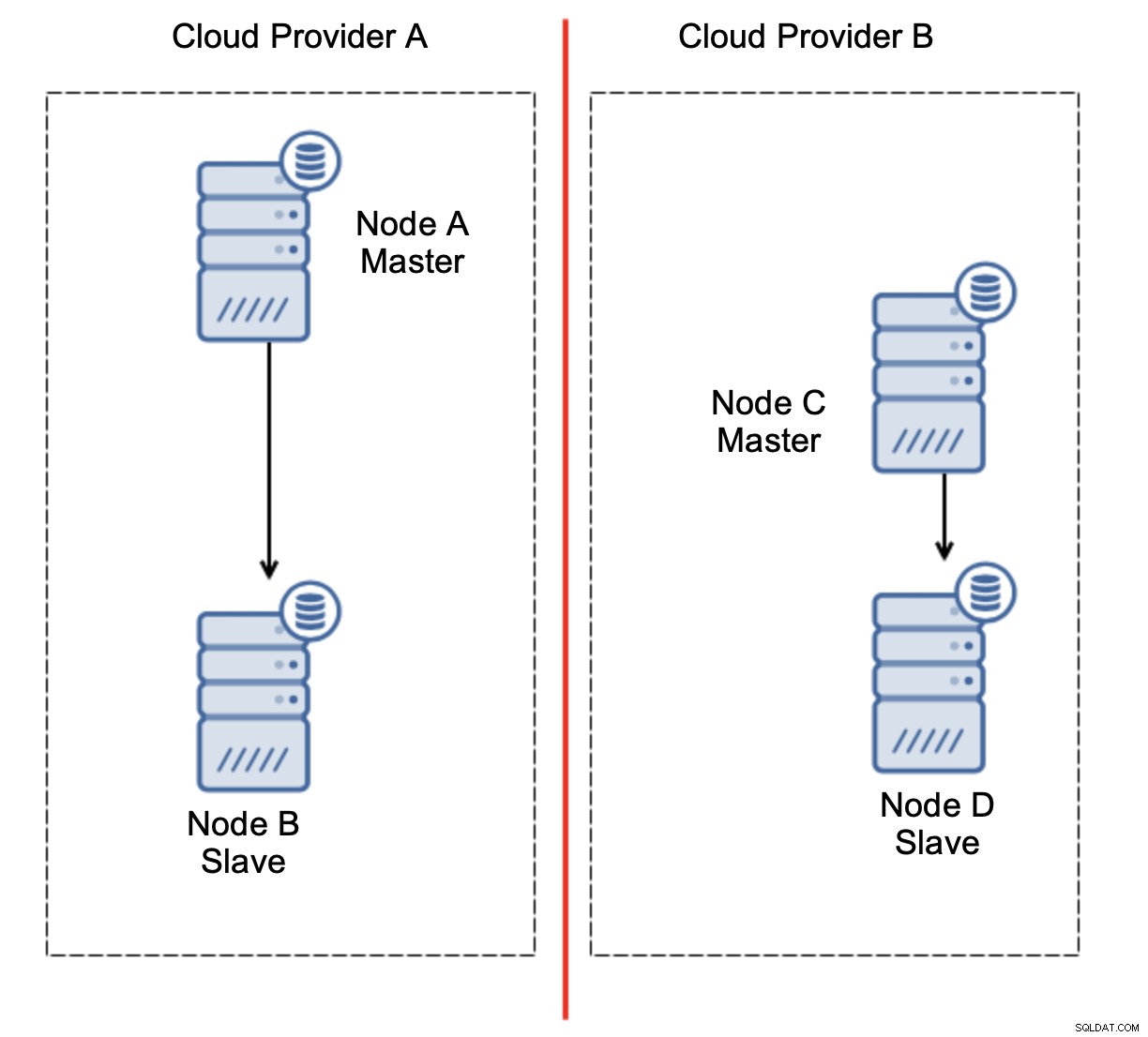
Ini jelas bukan sesuatu yang kita inginkan. Ada beberapa pilihan di sini. Pertama, kita dapat mendefinisikan aturan failover sedemikian rupa sehingga failover hanya dapat terjadi di salah satu segmen jaringan, di mana master berada. Dalam kasus kami ini berarti bahwa hanya node B yang dapat secara otomatis dipromosikan menjadi master. Dengan begitu kita dapat memastikan bahwa failover otomatis akan terjadi jika node A down tetapi tidak ada tindakan yang akan diambil jika ada partisi jaringan. Beberapa alat yang dapat membantu Anda menangani failover otomatis (seperti ClusterControl) mendukung daftar putih dan hitam, memungkinkan pengguna untuk menentukan node mana yang dapat dianggap sebagai kandidat untuk failover dan yang tidak boleh digunakan sebagai master.
Opsi lain adalah menerapkan semacam solusi "kesadaran topologi". Misalnya, seseorang dapat mencoba memeriksa status master menggunakan layanan eksternal seperti penyeimbang beban.
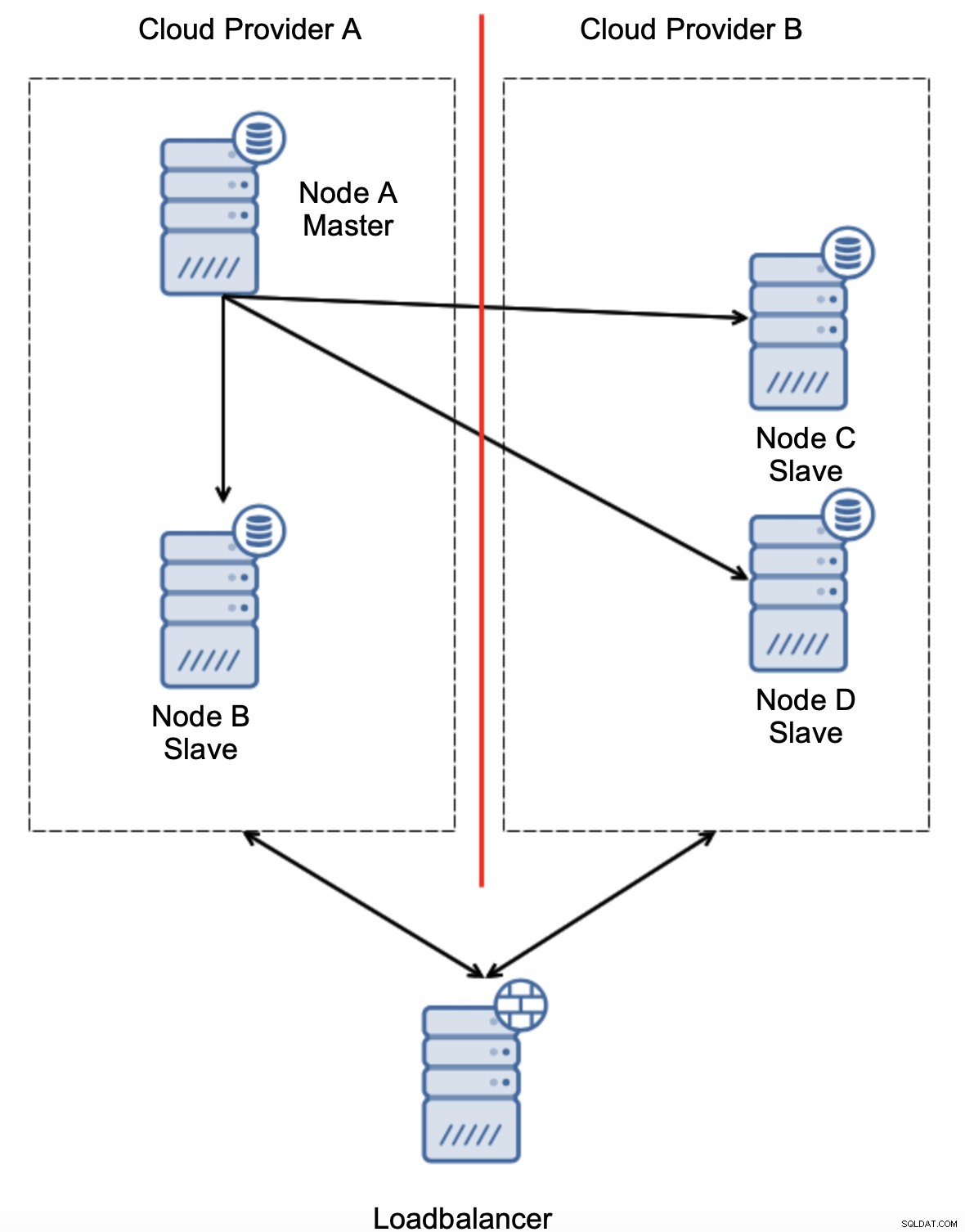
Jika otomatisasi failover dapat memeriksa status topologi seperti yang terlihat oleh penyeimbang beban, mungkin penyeimbang beban, yang terletak di lokasi ketiga, sebenarnya dapat menjangkau kedua pusat data dan memperjelas bahwa node di penyedia cloud A tidak down, mereka hanya tidak dapat dijangkau dari penyedia cloud B. Seperti itu lapisan pemeriksaan tambahan diimplementasikan di ClusterControl.
Akhirnya, alat apa pun yang Anda gunakan untuk mengimplementasikan failover otomatis, alat itu juga dapat dirancang agar sadar kuorum. Kemudian, dengan tiga node di tiga lokasi, Anda dapat dengan mudah mengetahui bagian infrastruktur mana yang harus tetap hidup dan mana yang tidak.
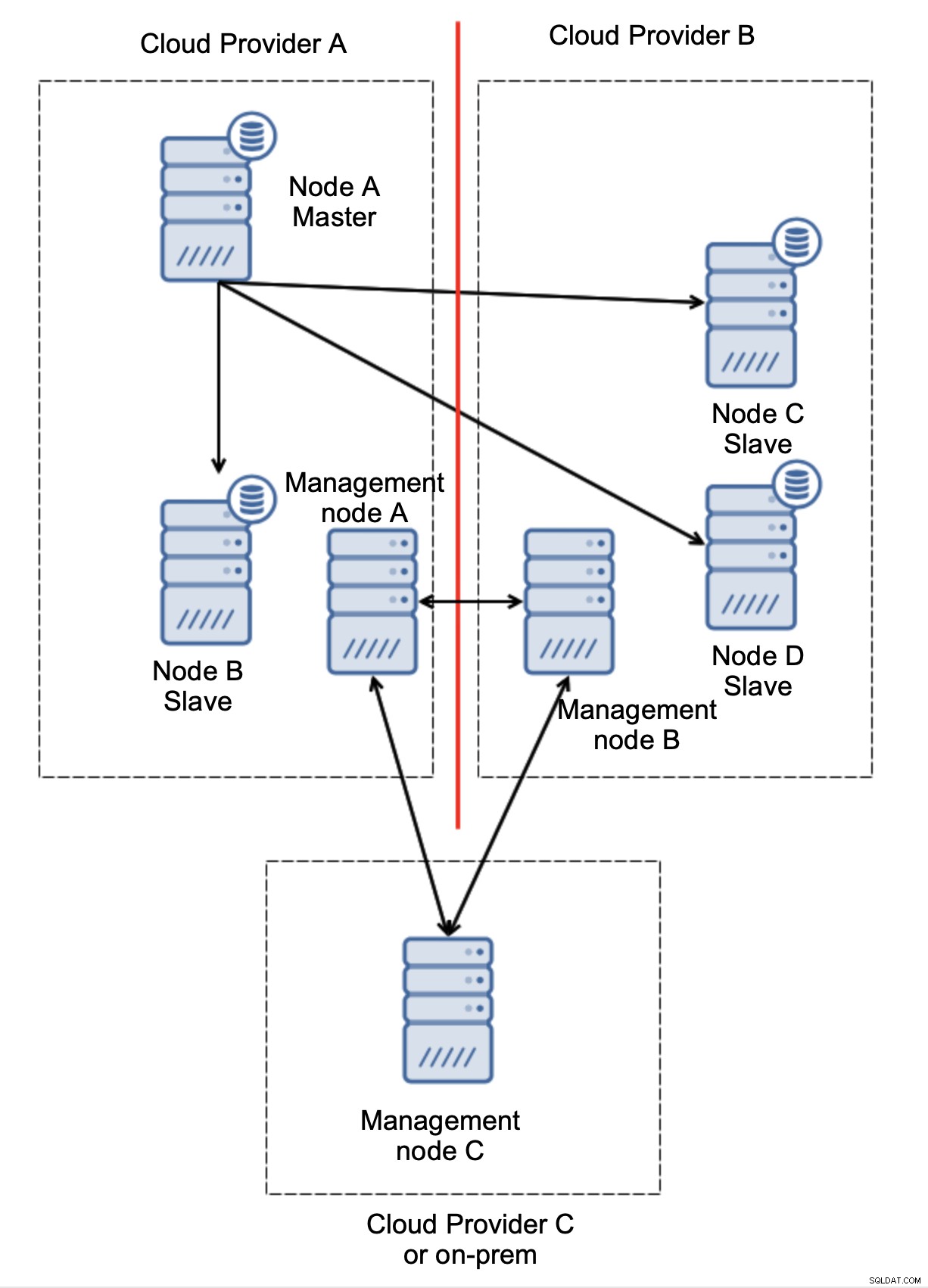
Di sini, kita dapat dengan jelas melihat bahwa masalah hanya terkait dengan konektivitas antara penyedia A dan B. Manajemen node C akan bertindak sebagai relai dan, sebagai hasilnya, tidak ada failover yang harus dimulai. Di sisi lain, jika satu pusat data terputus sepenuhnya:

Apa yang terjadi juga cukup jelas. Node manajemen A akan melaporkan tidak dapat menjangkau mayoritas cluster sementara node manajemen B dan C akan membentuk mayoritas. Dimungkinkan untuk membangun ini dan, misalnya, menulis skrip yang akan mengelola topologi sesuai dengan status node manajemen. Itu bisa berarti bahwa skrip yang dijalankan di penyedia cloud A akan mendeteksi bahwa node manajemen A tidak membentuk mayoritas dan mereka akan menghentikan semua node database untuk memastikan tidak ada penulisan yang akan terjadi di penyedia cloud yang dipartisi.
ClusterControl, ketika digunakan dalam mode Ketersediaan Tinggi dapat diperlakukan sebagai node manajemen yang kami gunakan dalam contoh kami. Tiga node ClusterControl, di atas protokol RAFT, dapat membantu Anda menentukan apakah segmen jaringan tertentu dipartisi atau tidak.
Kesimpulan
Kami harap postingan blog ini memberi Anda beberapa gagasan tentang skenario split-brain yang mungkin terjadi untuk penerapan MySQL di berbagai platform cloud.



