Anda mungkin pernah mendengar tentang istilah "failover" dalam konteks replikasi MySQL. Mungkin Anda bertanya-tanya apa itu saat Anda memulai petualangan Anda dengan database. Mungkin Anda tahu apa itu tetapi Anda tidak yakin tentang potensi masalah yang terkait dengannya dan bagaimana cara mengatasinya?
Dalam posting blog ini kami akan mencoba memberikan pengenalan penanganan failover di MySQL &MariaDB.
Kita akan membahas apa itu failover, mengapa tidak bisa dihindari, apa perbedaan antara failover dan switchover. Kami akan membahas proses failover dalam bentuk yang paling umum. Kami juga akan membahas sedikit tentang berbagai masalah yang harus Anda tangani sehubungan dengan proses failover.
Apa Artinya "kegagalan"?
Replikasi MySQL adalah kumpulan node, masing-masing dapat melayani satu peran pada satu waktu. Itu bisa menjadi master atau replika. Hanya ada satu master node pada waktu tertentu. Node ini menerima lalu lintas tulis dan mereplikasi penulisan ke replikanya.
Seperti yang dapat Anda bayangkan, sebagai titik masuk tunggal untuk data ke dalam cluster replikasi, node master cukup penting. Apa yang akan terjadi jika gagal dan menjadi tidak tersedia?
Ini adalah kondisi yang cukup serius untuk cluster replikasi. Itu tidak dapat menerima penulisan apa pun pada saat tertentu. Seperti yang Anda harapkan, salah satu replika harus mengambil alih tugas master dan mulai menerima penulisan. Topologi replikasi lainnya mungkin juga harus diubah - replika yang tersisa harus mengubah masternya dari node lama yang gagal ke node yang baru dipilih. Proses "mempromosikan" replika untuk menjadi master setelah master lama gagal disebut "failover".
Di sisi lain, "peralihan" terjadi ketika pengguna memicu promosi replika. Master baru dipromosikan dari replika yang ditunjuk oleh pengguna dan master lama, biasanya, menjadi replika master baru.
Perbedaan paling penting antara "failover" dan "switchover" adalah status master lama. Ketika failover dilakukan, master lama, dalam beberapa hal, tidak dapat dijangkau. Mungkin macet, mungkin mengalami partisi jaringan. Itu tidak dapat digunakan pada saat tertentu dan statusnya, biasanya, tidak diketahui.
Di sisi lain, ketika peralihan dilakukan, master lama masih hidup dan sehat. Ini memiliki konsekuensi serius. Jika master tidak dapat dijangkau, ini mungkin berarti bahwa beberapa data belum dikirim ke slave (kecuali jika replikasi semi-sinkron digunakan). Beberapa data mungkin rusak atau terkirim sebagian.
Ada mekanisme untuk menghindari penyebaran korupsi semacam itu pada budak tetapi intinya adalah bahwa beberapa data mungkin hilang dalam proses. Di sisi lain, saat melakukan peralihan, master lama tersedia dan konsistensi data tetap terjaga.
Proses Kegagalan
Mari luangkan waktu untuk membahas bagaimana sebenarnya proses failover itu.
Master Crash Terdeteksi
Sebagai permulaan, master harus crash sebelum failover akan dilakukan. Setelah tidak tersedia, failover dipicu. Sejauh ini, kelihatannya sederhana tetapi kenyataannya, kita sudah berada di tanah yang licin.
Pertama-tama, bagaimana kesehatan master diuji? Apakah itu diuji dari satu lokasi atau apakah tes didistribusikan? Apakah perangkat lunak manajemen failover hanya mencoba menyambung ke master atau menerapkan verifikasi lebih lanjut sebelum kegagalan master dinyatakan?
Mari kita bayangkan topologi berikut:
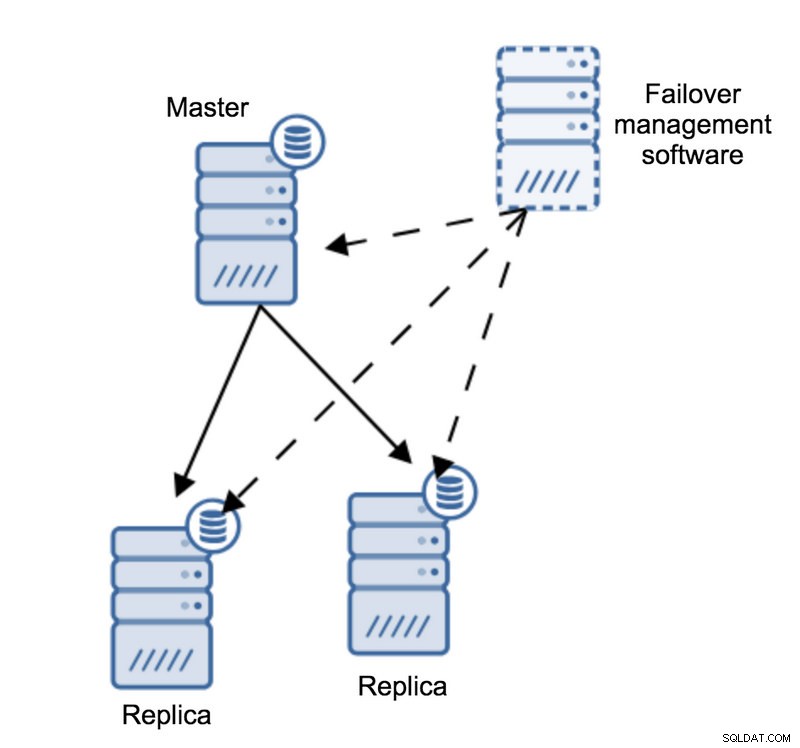
Kami memiliki master dan dua replika. Kami juga memiliki perangkat lunak manajemen failover yang terletak di beberapa host eksternal. Apa yang akan terjadi jika koneksi jaringan antara host dengan perangkat lunak failover dan master gagal?
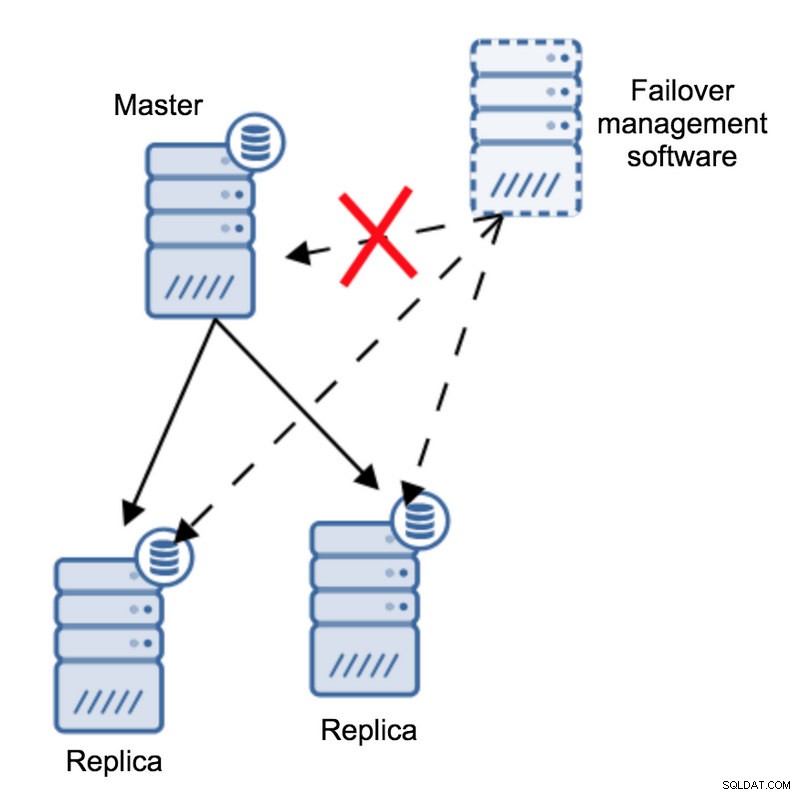
Menurut perangkat lunak manajemen failover, master mogok - tidak ada konektivitas ke sana. Namun, replikasi itu sendiri berfungsi dengan baik. Apa yang seharusnya terjadi di sini adalah bahwa perangkat lunak manajemen failover akan mencoba menyambung ke replika dan melihat apa sudut pandang mereka.
Apakah mereka mengeluh tentang replikasi yang rusak atau mereka dengan senang hati mereplikasi?
Hal-hal mungkin menjadi lebih kompleks. Bagaimana jika kita akan menambahkan proxy (atau satu set proxy)? Ini akan digunakan untuk merutekan lalu lintas - menulis ke master dan membaca ke replika. Bagaimana jika proxy tidak dapat mengakses master? Bagaimana jika tidak ada proxy yang dapat mengakses master?
Ini berarti bahwa aplikasi tidak dapat berfungsi dalam kondisi tersebut. Haruskah failover (sebenarnya, itu akan lebih merupakan peralihan karena master secara teknis masih hidup) dipicu?
Secara teknis, master masih hidup tetapi tidak dapat digunakan oleh aplikasi. Di sini, logika bisnis harus masuk dan keputusan harus dibuat.
Mencegah Tuan Tua Berlari
Tidak peduli bagaimana dan mengapa, jika ada keputusan untuk mempromosikan salah satu replika menjadi master baru, master lama harus dihentikan dan, idealnya, tidak boleh memulai lagi.
Bagaimana hal ini dapat dicapai tergantung pada detail dari lingkungan tertentu; oleh karena itu bagian dari proses failover ini biasanya diperkuat oleh skrip eksternal yang diintegrasikan ke dalam proses failover melalui berbagai kait.
Skrip tersebut dapat dirancang untuk menggunakan alat yang tersedia di lingkungan tertentu untuk menghentikan master lama. Ini bisa berupa panggilan CLI atau API yang akan menghentikan VM; itu bisa berupa kode shell yang menjalankan perintah melalui semacam perangkat "manajemen mati"; itu bisa berupa skrip yang mengirimkan jebakan SNMP ke Unit Distribusi Daya yang menonaktifkan stopkontak yang digunakan master lama (tanpa daya listrik, kami dapat yakin itu tidak akan mulai lagi).
Jika perangkat lunak manajemen failover adalah bagian dari produk yang lebih kompleks, yang juga menangani pemulihan node (seperti halnya ClusterControl), master lama dapat ditandai sebagai dikecualikan dari rutinitas pemulihan.
Anda mungkin bertanya-tanya mengapa sangat penting untuk mencegah master lama tersedia lagi?
Masalah utamanya adalah bahwa dalam pengaturan replikasi, hanya satu node yang dapat digunakan untuk menulis. Biasanya Anda memastikannya dengan mengaktifkan variabel read_only (dan super_read_only, jika berlaku) di semua replika dan menonaktifkannya hanya di master.
Setelah master baru dipromosikan, read_only akan dinonaktifkan. Masalahnya adalah, jika master lama tidak tersedia, kita tidak dapat mengubahnya kembali ke read_only=1. Jika MySQL atau host mogok, ini bukan masalah besar karena praktik yang baik adalah mengkonfigurasi my.cnf dengan pengaturan itu, jadi, begitu MySQL dimulai, selalu dimulai dalam mode hanya baca.
Masalahnya muncul ketika itu bukan crash tetapi masalah jaringan. Master lama masih berjalan dengan read_only dinonaktifkan, hanya saja tidak tersedia. Ketika jaringan bertemu, Anda akan berakhir dengan dua node yang dapat ditulisi. Ini mungkin atau mungkin tidak menjadi masalah. Beberapa proxy menggunakan pengaturan read_only sebagai indikator apakah sebuah node adalah master atau replika. Dua master yang muncul pada saat tertentu dapat menyebabkan masalah besar karena data ditulis ke kedua host, tetapi replika hanya mendapatkan setengah dari lalu lintas tulis (bagian yang mengenai master baru).
Terkadang ini tentang pengaturan hardcode di beberapa skrip yang dikonfigurasi untuk terhubung ke host tertentu saja. Biasanya mereka akan gagal dan seseorang akan menyadari bahwa master telah berubah.
Dengan tersedianya master lama, mereka akan dengan senang hati terhubung dengannya dan perbedaan data akan muncul. Seperti yang Anda lihat, memastikan master lama tidak akan memulai adalah item prioritas yang cukup tinggi.
Tentukan Calon Master
Master lama telah turun dan tidak akan kembali dari kuburnya, sekarang saatnya untuk memutuskan host mana yang harus kita gunakan sebagai master baru. Biasanya ada lebih dari satu replika untuk dipilih, jadi keputusan harus dibuat. Ada banyak alasan mengapa satu replika dapat diambil dari yang lain, oleh karena itu pemeriksaan harus dilakukan.
Daftar putih dan daftar hitam
Sebagai permulaan, tim yang mengelola database mungkin memiliki alasan untuk memilih satu replika di atas yang lain ketika memutuskan tentang kandidat master. Mungkin menggunakan perangkat keras yang lebih lemah atau memiliki tugas tertentu yang ditugaskan padanya (replika itu menjalankan pencadangan, kueri analitik, pengembang memiliki akses ke sana dan menjalankan kueri buatan tangan yang dibuat sendiri). Mungkin ini adalah replika pengujian di mana versi baru sedang menjalani tes penerimaan sebelum melanjutkan dengan peningkatan. Sebagian besar perangkat lunak manajemen failover mendukung daftar putih dan hitam, yang dapat digunakan untuk secara tepat menentukan replika mana yang harus atau tidak dapat digunakan sebagai kandidat master.
Replikasi semi-sinkron
Pengaturan replikasi mungkin merupakan campuran replika asinkron dan semi-sinkron. Ada perbedaan besar di antara mereka - replika semi-sinkron dijamin berisi semua peristiwa dari master. Replika asinkron mungkin tidak menerima semua data sehingga kegagalan untuk itu dapat mengakibatkan hilangnya data. Kami lebih suka melihat replika semi-sinkron untuk dipromosikan.
Keterlambatan replikasi
Meskipun replika semi-sinkron akan berisi semua peristiwa, peristiwa tersebut mungkin masih berada di log relai saja. Dengan lalu lintas yang padat, semua replika, baik semi-sinkron atau asinkron, mungkin tertinggal.
Masalah dengan jeda replikasi adalah, ketika Anda mempromosikan replika, Anda harus mengatur ulang pengaturan replikasi sehingga tidak akan mencoba menyambung ke master lama. Ini juga akan menghapus semua log relai, meskipun belum diterapkan - yang menyebabkan hilangnya data.
Bahkan jika Anda tidak akan mengatur ulang pengaturan replikasi, Anda masih tidak dapat membuka master baru ke koneksi jika belum menerapkan semua peristiwa dari log relai. Jika tidak, Anda akan mengambil risiko bahwa kueri baru akan memengaruhi transaksi dari log relai, memicu semua jenis masalah (misalnya, aplikasi dapat menghapus beberapa baris yang diakses oleh transaksi dari log relai).
Mempertimbangkan semua ini, satu-satunya pilihan yang aman adalah menunggu log relai diterapkan. Namun, mungkin perlu beberapa saat jika replika sangat tertinggal. Keputusan harus dibuat mengenai replika mana yang akan menjadi master yang lebih baik - asinkron, tetapi dengan jeda kecil atau semi-sinkron, tetapi dengan jeda yang akan membutuhkan banyak waktu untuk diterapkan.
Transaksi salah
Meskipun replika tidak boleh ditulis, masih bisa terjadi bahwa seseorang (atau sesuatu) telah menulisnya.
Ini mungkin hanya satu cara transaksi di masa lalu, tetapi mungkin masih memiliki efek serius pada kemampuan untuk melakukan failover. Masalah ini sangat terkait dengan Global Transaction ID (GTID), sebuah fitur yang memberikan ID berbeda untuk setiap transaksi yang dijalankan pada node MySQL tertentu.
Saat ini, ini adalah penyiapan yang cukup populer karena menghadirkan tingkat fleksibilitas yang tinggi dan memungkinkan kinerja yang lebih baik (dengan replika multi-utas).
Masalahnya adalah, saat melakukan re-slaving ke master baru, replikasi GTID mengharuskan semua peristiwa dari master tersebut (yang belum dieksekusi pada replika) untuk direplikasi ke replika.
Mari kita pertimbangkan skenario berikut:di beberapa titik di masa lalu, penulisan terjadi pada replika. Sudah lama sekali dan peristiwa ini telah dihapus dari log biner replika. Pada titik tertentu master telah gagal dan replika ditunjuk sebagai master baru. Semua replika yang tersisa akan dikeluarkan dari master baru. Mereka akan bertanya tentang transaksi yang dilakukan pada master baru. Ini akan merespons dengan daftar GTID yang berasal dari master lama dan GTID tunggal yang terkait dengan penulisan lama itu. GTID dari master lama tidak menjadi masalah karena semua replika yang tersisa berisi setidaknya sebagian besar (jika tidak semua) dan semua peristiwa yang hilang harus cukup baru untuk tersedia di log biner master baru.
Skenario terburuk, beberapa peristiwa yang hilang akan dibaca dari log biner dan ditransfer ke replika. Masalahnya adalah dengan penulisan lama itu - itu terjadi hanya pada master baru, sementara itu masih replika, sehingga tidak ada pada host yang tersisa. Ini adalah peristiwa lama oleh karena itu tidak ada cara untuk mengambilnya dari log biner. Akibatnya, tidak ada replika yang dapat menggantikan master baru. Satu-satunya solusi di sini adalah mengambil tindakan manual dan menyuntikkan acara kosong dengan GTID bermasalah itu di semua replika. Ini juga berarti bahwa, tergantung pada apa yang terjadi, replika mungkin tidak sinkron dengan master baru.
Seperti yang Anda lihat, sangat penting untuk melacak transaksi yang salah dan menentukan apakah aman untuk mempromosikan replika tertentu untuk menjadi master baru. Jika berisi transaksi yang salah, itu mungkin bukan pilihan terbaik.
Penanganan Failover untuk Aplikasi
Sangat penting untuk diingat bahwa master switch, dipaksa atau tidak, memiliki efek pada keseluruhan topologi. Menulis harus diarahkan ke node baru. Ini dapat dilakukan dengan berbagai cara dan sangat penting untuk memastikan bahwa perubahan ini setransparan mungkin ke aplikasi. Di bagian ini kita akan melihat beberapa contoh bagaimana failover dapat dibuat transparan untuk aplikasi.
DNS
Salah satu cara di mana aplikasi dapat diarahkan ke master adalah dengan memanfaatkan entri DNS. Dengan TTL rendah, dimungkinkan untuk mengubah alamat IP yang menjadi tujuan entri DNS seperti 'master.dc1.example.com'. Perubahan seperti itu dapat dilakukan melalui skrip eksternal yang dieksekusi selama proses failover.
Penemuan layanan
Alat seperti Consul atau etc.d juga dapat digunakan untuk mengarahkan lalu lintas ke lokasi yang benar. Alat tersebut mungkin berisi informasi bahwa IP master saat ini diatur ke beberapa nilai. Beberapa dari mereka juga memberikan kemampuan untuk menggunakan pencarian nama host untuk menunjuk ke IP yang benar. Sekali lagi, entri dalam alat penemuan layanan harus dipertahankan dan salah satu cara untuk melakukannya adalah dengan membuat perubahan tersebut selama proses failover, menggunakan kait yang dijalankan pada berbagai tahap failover.
Proksi
Proxy juga dapat digunakan sebagai sumber kebenaran tentang topologi. Secara umum, tidak peduli bagaimana mereka menemukan topologi (dapat berupa proses otomatis atau proxy harus dikonfigurasi ulang ketika topologi berubah), mereka harus berisi status rantai replikasi saat ini karena jika tidak, mereka tidak akan dapat merutekan kueri dengan benar.
Pendekatan untuk menggunakan proxy sebagai sumber kebenaran bisa sangat umum dalam hubungannya dengan pendekatan untuk menempatkan proxy pada host aplikasi. Ada banyak keuntungan untuk menempatkan proxy dan server web:komunikasi yang cepat dan aman menggunakan soket Unix, menjaga lapisan caching (karena beberapa proxy, seperti ProxySQL juga dapat melakukan caching) dekat dengan aplikasi. Dalam kasus seperti itu, masuk akal jika aplikasi hanya terhubung ke proxy dan menganggapnya akan merutekan kueri dengan benar.
Kegagalan di ClusterControl
ClusterControl menerapkan praktik terbaik industri untuk memastikan bahwa proses failover dilakukan dengan benar. Ini juga memastikan bahwa proses akan aman - pengaturan default dimaksudkan untuk membatalkan failover jika kemungkinan masalah terdeteksi. Setelan tersebut dapat diganti oleh pengguna jika mereka ingin memprioritaskan failover daripada keamanan data.
Setelah kegagalan master terdeteksi oleh ClusterControl, proses failover dimulai dan hook failover pertama segera dieksekusi:

Selanjutnya, ketersediaan master diuji.

ClusterControl melakukan tes ekstensif untuk memastikan master memang tidak tersedia. Perilaku ini diaktifkan secara default dan dikelola oleh variabel berikut:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.Sebagai langkah berikut, ClusterControl memastikan bahwa master lama tidak aktif dan jika tidak, ClusterControl tidak akan mencoba memulihkannya:

Langkah selanjutnya adalah menentukan host mana yang dapat digunakan sebagai kandidat master. ClusterControl tidak memeriksa apakah daftar putih atau daftar hitam ditentukan.
Anda dapat melakukannya dengan menggunakan variabel berikut dalam file konfigurasi cmon:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.Dimungkinkan juga untuk mengonfigurasi ClusterControl untuk mencari perbedaan dalam filter log biner di semua replika. Itu dapat dilakukan dengan menggunakan variabel replica_check_binlog_filtration_bf_failover. Secara default, pemeriksaan tersebut dinonaktifkan. ClusterControl juga memverifikasi bahwa tidak ada transaksi yang salah, yang dapat menyebabkan masalah.

Anda juga dapat meminta ClusterControl untuk membangun kembali replika yang tidak dapat direplikasi dari master baru menggunakan pengaturan berikut dalam file konfigurasi cmon:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Setelah itu skrip kedua dijalankan:itu didefinisikan dalam pengaturan replikasi_pre_failover_script. Selanjutnya, seorang kandidat menjalani proses persiapan.


ClusterControl menunggu redo log diterapkan (memastikan kehilangan data minimal). Itu juga memeriksa apakah ada transaksi lain yang tersedia di replika yang tersisa, yang belum diterapkan ke kandidat master. Kedua perilaku tersebut dapat dikontrol oleh pengguna, menggunakan pengaturan berikut dalam file konfigurasi cmon:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Seperti yang Anda lihat, Anda dapat memaksa failover meskipun tidak semua peristiwa redo log telah diterapkan - ini memungkinkan pengguna untuk memutuskan apa yang memiliki prioritas lebih tinggi - konsistensi data atau kecepatan failover.


Terakhir, master dipilih dan skrip terakhir dijalankan (skrip yang dapat didefinisikan sebagai skrip replikasi_post_failover_.
Jika Anda belum mencoba ClusterControl, sebaiknya Anda mengunduhnya (gratis) dan mencobanya.
Deteksi Master di ClusterControl
ClusterControl memberi Anda kemampuan untuk menerapkan tumpukan Ketersediaan Tinggi penuh termasuk database dan lapisan proxy. Penemuan master selalu menjadi salah satu masalah yang harus dihadapi.
Bagaimana cara kerjanya di ClusterControl?
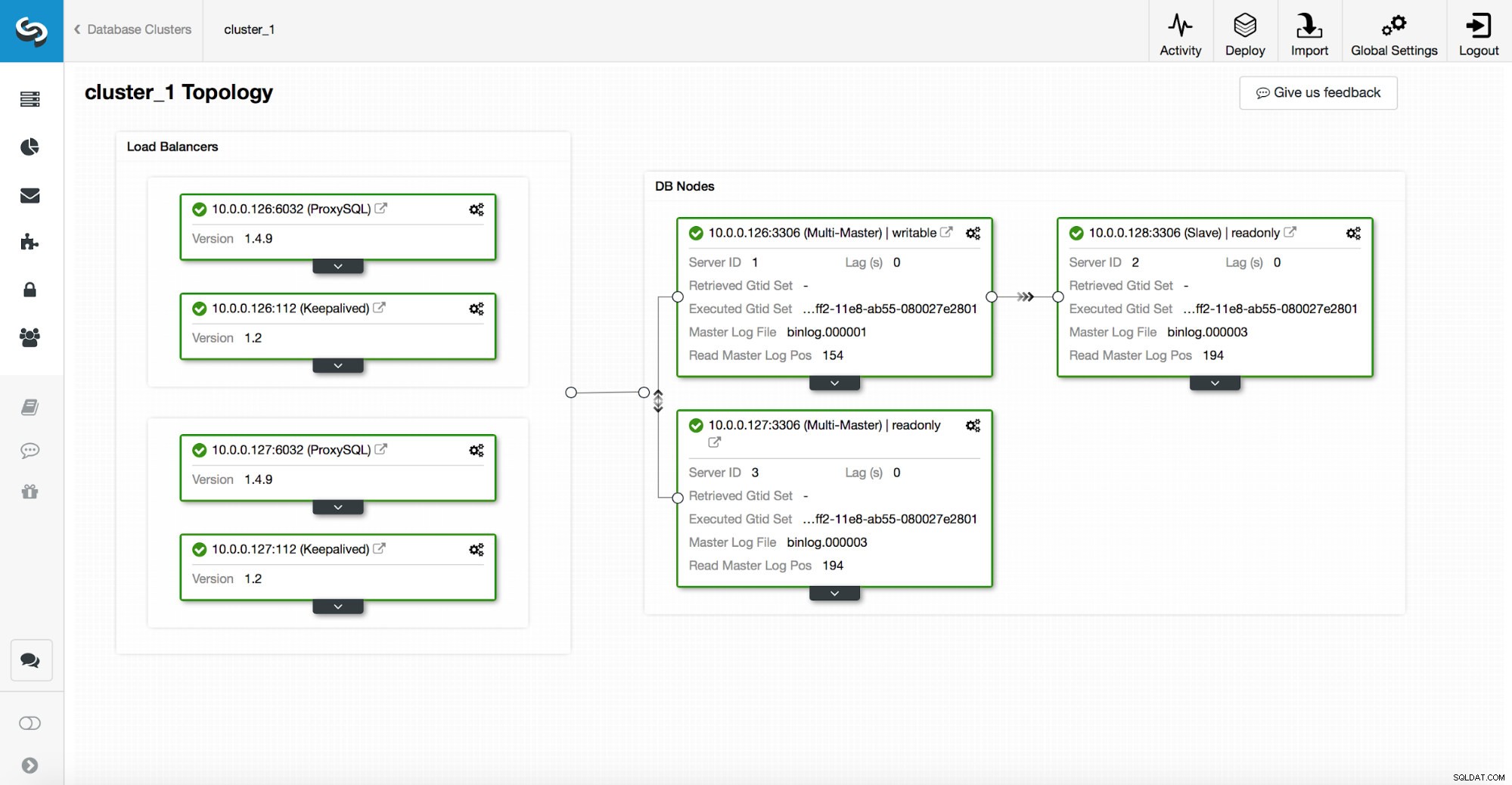
Tumpukan ketersediaan tinggi, yang disebarkan melalui ClusterControl, terdiri dari tiga bagian:
- lapisan basis data
- lapisan proxy yang dapat berupa HAProxy atau ProxySQL
- lapisan tetap, yang, dengan penggunaan IP Virtual, memastikan ketersediaan tinggi lapisan proxy
Proxy bergantung pada variabel read_only pada node.
Seperti yang Anda lihat pada tangkapan layar di atas, hanya satu simpul di topologi yang ditandai sebagai "dapat ditulis". Ini adalah master dan ini adalah satu-satunya node yang akan menerima penulisan.
Proxy (dalam contoh ini, ProxySQL) akan memantau variabel ini dan akan mengonfigurasi ulang dirinya sendiri secara otomatis.
Di sisi lain dari persamaan itu, ClusterControl menangani perubahan topologi:failover dan switchover. Ini akan membuat perubahan yang diperlukan dalam nilai read_only untuk mencerminkan keadaan topologi setelah perubahan. Jika master baru dipromosikan, itu akan menjadi satu-satunya node yang dapat ditulis. Jika master dipilih setelah failover, itu akan menonaktifkan read_only.
Di atas lapisan proxy, keepalive dikerahkan. Ini menyebarkan VIP dan memonitor keadaan node proxy yang mendasarinya. VIP menunjuk ke satu node proxy pada waktu tertentu. Jika node ini turun, IP virtual dialihkan ke node lain, memastikan bahwa lalu lintas yang diarahkan ke VIP akan mencapai node proxy yang sehat.
Singkatnya, aplikasi terhubung ke database menggunakan alamat IP virtual. IP ini menunjuk ke salah satu proxy. Proxy mengarahkan lalu lintas sesuai dengan struktur topologi. Informasi tentang topologi berasal dari status read_only. Variabel ini dikelola oleh ClusterControl dan diatur berdasarkan perubahan topologi yang diminta pengguna atau ClusterControl dilakukan secara otomatis.



