Replikasi MySQL telah menjadi solusi yang paling umum dan banyak digunakan untuk ketersediaan tinggi oleh organisasi besar seperti Github, Twitter, dan Facebook. Meskipun mudah diatur, ada tantangan yang dihadapi saat menggunakan solusi ini dari pemeliharaan, termasuk peningkatan perangkat lunak, penyimpangan data atau inkonsistensi data di seluruh node replika, perubahan topologi, failover, dan pemulihan. Ketika MySQL merilis versi 5.6, itu membawa sejumlah peningkatan signifikan, terutama untuk replikasi yang mencakup ID Transaksi Global (GTID), checksum peristiwa, budak multi-utas, dan budak/master yang aman dari kerusakan. Replikasi menjadi lebih baik dengan MySQL 5.7 dan MySQL 8.0.
Replikasi memungkinkan data dari satu server MySQL (primer/master) direplikasi ke satu atau lebih server MySQL (replika/slave). Replikasi MySQL sangat mudah disiapkan dan digunakan untuk mengurangi beban kerja baca, menyediakan ketersediaan tinggi dan redundansi geografis, serta membongkar cadangan dan tugas analitik.
Replikasi MySQL di Alam
Mari kita lihat ikhtisar singkat tentang cara kerja Replikasi MySQL di alam. Replikasi MySQL luas, dan ada banyak cara untuk mengonfigurasinya dan bagaimana itu dapat digunakan. Secara default, ini menggunakan replikasi asinkron, yang berfungsi saat transaksi selesai di lingkungan lokal. Tidak ada jaminan bahwa peristiwa apa pun akan mencapai budak mana pun. Ini adalah hubungan tuan-budak yang digabungkan secara longgar, di mana:
-
Utama tidak menunggu replika.
-
Replika menentukan seberapa banyak yang harus dibaca dan dari titik mana dalam log biner.
-
Replika dapat berada di belakang master dalam membaca atau menerapkan perubahan.
Jika primer mogok, transaksi yang telah dilakukan mungkin tidak dikirimkan ke replika apa pun. Akibatnya, failover dari replika utama ke replika paling canggih, dalam hal ini, dapat mengakibatkan failover ke primer yang diinginkan yang sebenarnya tidak memiliki transaksi relatif terhadap server sebelumnya.
Replikasi asinkron memberikan latensi tulis yang lebih rendah karena penulisan diakui secara lokal oleh master sebelum ditulis ke slave. Ini bagus untuk penskalaan baca karena menambahkan lebih banyak replika tidak memengaruhi latensi replikasi. Kasus penggunaan yang baik untuk replikasi asinkron mencakup penerapan replika baca untuk penskalaan baca, salinan cadangan langsung untuk pemulihan bencana, dan analitik/pelaporan.
Replikasi Semi-Sinkron MySQL
MySQL juga mendukung replikasi semi-sinkron, di mana master tidak mengkonfirmasi transaksi ke klien sampai setidaknya satu budak telah menyalin perubahan ke log relai dan membuangnya ke disk. Untuk mengaktifkan replikasi semi-sinkron, langkah-langkah tambahan untuk instalasi plugin diperlukan dan harus diaktifkan pada node master dan slave MySQL yang ditunjuk.
Semi-sinkron tampaknya menjadi solusi yang baik dan praktis untuk banyak kasus di mana ketersediaan tinggi dan tidak ada kehilangan data penting. Tetapi Anda harus mempertimbangkan bahwa semi-sinkron memiliki dampak kinerja karena perjalanan pulang pergi tambahan dan tidak memberikan jaminan yang kuat terhadap kehilangan data. Ketika komit kembali dengan sukses, diketahui bahwa data ada di setidaknya dua tempat (di master dan setidaknya satu budak). Jika master melakukan tetapi crash terjadi saat master menunggu pengakuan dari budak, ada kemungkinan bahwa transaksi mungkin tidak mencapai budak manapun. Ini bukan masalah besar karena komit tidak akan dikembalikan ke aplikasi dalam kasus ini. Ini adalah tugas aplikasi untuk mencoba kembali transaksi di masa mendatang. Yang penting untuk diingat adalah bahwa ketika master gagal, dan seorang budak telah dipromosikan, master lama tidak dapat bergabung dengan rantai replikasi. Dalam beberapa keadaan, ini dapat menyebabkan konflik dengan data pada budak, yaitu, ketika master mengalami crash setelah budak menerima peristiwa log biner tetapi sebelum master mendapat pengakuan dari budak). Jadi satu-satunya cara aman adalah membuang data pada master lama dan menyediakannya dari awal menggunakan data dari master yang baru dipromosikan.
Menggunakan Format Replikasi yang Salah
Sejak MySQL 5.7.7, format log biner default atau variabel binlog_format menggunakan ROW, yang merupakan STATEMENT sebelum 5.7.7. Format replikasi yang berbeda sesuai dengan metode yang digunakan untuk merekam peristiwa log biner sumber. Replikasi berfungsi karena peristiwa yang ditulis ke log biner dibaca dari sumber dan kemudian diproses pada replika. Peristiwa dicatat dalam log biner dalam format replikasi yang berbeda sesuai dengan jenis peristiwa. Tidak tahu pasti apa yang harus digunakan bisa menjadi masalah. MySQL memiliki tiga format metode replikasi:STATEMENT, ROW, dan MIXED.
-
Format replikasi berbasis STATEMENT (SBR) persis seperti apa adanya– aliran replikasi dari setiap pernyataan yang dijalankan pada master yang akan diputar ulang pada node slave. Secara default, replikasi MySQL tradisional (asynchronous) tidak mengeksekusi transaksi yang direplikasi ke budak secara paralel. Artinya, urutan pernyataan dalam aliran replikasi mungkin tidak 100% sama. Juga, memutar ulang pernyataan dapat memberikan hasil yang berbeda ketika tidak dieksekusi pada saat yang sama seperti ketika dieksekusi dari sumbernya. Hal ini menyebabkan keadaan tidak konsisten terhadap primer dan replikanya. Ini bukan masalah selama bertahun-tahun, karena tidak banyak yang menjalankan MySQL dengan banyak utas simultan. Namun, dengan arsitektur multi-CPU modern, hal ini sebenarnya menjadi sangat mungkin terjadi pada beban kerja normal sehari-hari.
-
Format replikasi ROW memberikan solusi yang tidak dimiliki SBR. Saat menggunakan format logging replikasi berbasis baris (RBR), sumber menulis peristiwa ke log biner yang menunjukkan bagaimana baris tabel individual diubah. Replikasi dari sumber ke replika bekerja dengan menyalin kejadian yang mewakili perubahan pada baris tabel ke replika. Ini berarti bahwa lebih banyak data dapat dihasilkan, memengaruhi ruang disk di replika dan memengaruhi lalu lintas jaringan dan I/O disk. Pertimbangkan jika pernyataan mengubah banyak baris, katakanlah dengan pernyataan UPDATE, RBR menulis lebih banyak data ke log biner bahkan untuk pernyataan yang dibatalkan. Menjalankan snapshot point-in-time juga bisa memakan waktu lebih lama. Masalah konkurensi mungkin ikut berperan mengingat waktu penguncian yang diperlukan untuk menulis potongan besar data ke dalam log biner.
-
Lalu ada metode di antara keduanya; replikasi mode campuran. Jenis replikasi ini akan selalu mereplikasi pernyataan, kecuali jika kueri berisi fungsi UUID(), pemicu, prosedur tersimpan, UDF, dan beberapa pengecualian lainnya. Mode campuran tidak akan menyelesaikan masalah penyimpangan data dan, bersama dengan replikasi berbasis pernyataan, harus dihindari.
Berencana Memiliki Pengaturan Multi-Master?
Replikasi Melingkar (juga dikenal sebagai topologi ring) adalah pengaturan umum dan umum untuk replikasi MySQL. Ini digunakan untuk menjalankan pengaturan multi-master (lihat gambar di bawah) dan seringkali diperlukan jika Anda memiliki lingkungan multi-pusat data. Karena aplikasi tidak dapat menunggu master di pusat data lain untuk mengakui penulisan, master lokal lebih disukai. Biasanya offset kenaikan otomatis digunakan untuk mencegah bentrokan data antara master. Memiliki dua master yang melakukan penulisan satu sama lain dengan cara ini adalah solusi yang diterima secara luas.
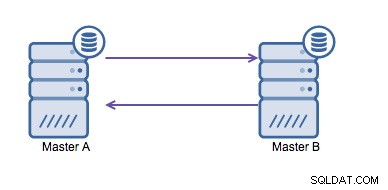
Namun, jika Anda perlu menulis di beberapa pusat data ke dalam database yang sama , Anda berakhir dengan beberapa master yang perlu menulis data mereka satu sama lain. Sebelum MySQL 5.7.6, tidak ada metode untuk melakukan replikasi tipe mesh, jadi alternatifnya adalah menggunakan replikasi cincin melingkar sebagai gantinya.
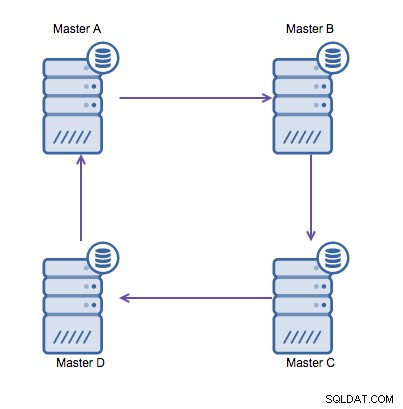
Replikasi dering di MySQL bermasalah karena alasan berikut:latensi, ketersediaan tinggi , dan penyimpangan data. Menulis beberapa data ke server A akan membutuhkan tiga hop untuk berakhir di server D (melalui server B dan C). Karena replikasi MySQL (tradisional) adalah single-threaded, setiap kueri yang berjalan lama dalam replikasi dapat menghentikan seluruh ring. Selain itu, jika salah satu server mati, ring akan rusak, dan saat ini, tidak ada perangkat lunak failover yang dapat memperbaiki struktur ring. Kemudian penyimpangan data dapat terjadi ketika data ditulis ke server A dan diubah secara bersamaan di server C atau D.
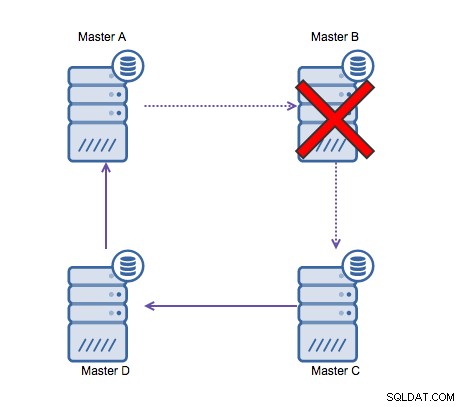
Secara umum, replikasi sirkular tidak cocok dengan MySQL dan harus dihindari dengan segala cara. Karena dirancang dengan pemikiran tersebut, Galera Cluster akan menjadi alternatif yang baik untuk penulisan multi-pusat data.
Menghentikan Replikasi Anda dengan Pembaruan Besar
Berbagai pekerjaan batch housekeeping sering melakukan berbagai tugas, mulai dari membersihkan data lama hingga menghitung rata-rata 'suka' yang diambil dari sumber lain. Ini berarti pekerjaan akan membuat banyak aktivitas basis data pada interval yang ditetapkan dan, kemungkinan besar, menulis banyak data kembali ke basis data. Secara alami, ini berarti aktivitas dalam aliran replikasi akan meningkat secara merata.
Replikasi berbasis pernyataan akan mereplikasi kueri persis yang digunakan dalam tugas batch, jadi jika kueri membutuhkan waktu setengah jam untuk diproses pada master, utas budak akan terhenti setidaknya untuk jumlah yang sama waktu. Ini berarti tidak ada data lain yang dapat direplikasi, dan node slave akan mulai tertinggal dari master. Jika ini melebihi ambang batas alat failover atau proxy Anda, mungkin akan menjatuhkan node budak ini dari server yang tersedia di cluster. Jika Anda menggunakan replikasi berbasis pernyataan, Anda dapat mencegahnya dengan mengolah data untuk tugas Anda dalam kumpulan yang lebih kecil.
Sekarang, Anda mungkin berpikir replikasi berbasis baris tidak terpengaruh oleh ini, karena ini akan mereplikasi informasi baris alih-alih kueri. Ini sebagian benar karena, untuk perubahan DDL, replikasi kembali ke format berbasis pernyataan. Juga, sejumlah besar operasi CRUD (Buat, Baca, Perbarui, Hapus) akan memengaruhi aliran replikasi. Dalam kebanyakan kasus, ini masih merupakan operasi utas tunggal, dan dengan demikian setiap transaksi akan menunggu yang sebelumnya diputar ulang melalui replikasi. Ini berarti bahwa jika Anda memiliki konkurensi yang tinggi pada master, slave dapat menghentikan transaksi yang berlebihan selama replikasi.
Untuk menyiasatinya, MariaDB dan MySQL menawarkan replikasi paralel. Implementasinya mungkin berbeda per vendor dan versi. MySQL 5.6 menawarkan replikasi paralel selama kueri dipisahkan oleh skema. MariaDB 10.0 dan MySQL 5.7 keduanya dapat menangani replikasi paralel di seluruh skema tetapi memiliki batasan lain. Menjalankan kueri melalui utas budak paralel dapat mempercepat aliran replikasi Anda jika Anda menulis dengan berat. Jika tidak, akan lebih baik untuk tetap menggunakan replikasi utas tunggal tradisional.
Menangani Perubahan Skema atau DDL Anda
Sejak rilis 5.7, mengelola perubahan skema atau perubahan DDL (Data Definition Language ) di MySQL telah meningkat pesat. Hingga MySQL 8.0, algoritma perubahan DDL yang didukung adalah COPY dan INPLACE.
-
COPY:Algoritme ini membuat tabel sementara baru dengan skema yang diubah. Setelah memigrasikan data sepenuhnya ke tabel sementara yang baru, ia menukar dan menghapus tabel lama.
-
INPLACE:Algoritme ini melakukan operasi di tempat ke tabel asli dan menghindari salinan tabel dan membangun kembali bila memungkinkan.
-
INSTANT:Algoritma ini telah diperkenalkan sejak MySQL 8.0 tetapi masih memiliki keterbatasan.
Di MySQL 8.0, algoritme INSTANT diperkenalkan, membuat perubahan tabel instan dan di tempat untuk penambahan kolom dan memungkinkan DML bersamaan dengan peningkatan respons dan ketersediaan di lingkungan produksi yang sibuk. Hal ini membantu menghindari kelambatan dan kemacetan besar dalam replika yang biasanya merupakan masalah besar dalam perspektif aplikasi, menyebabkan data usang diambil karena pembacaan di slave belum diperbarui karena kelambatan.
Meskipun itu adalah peningkatan yang menjanjikan, masih ada keterbatasan, dan terkadang tidak mungkin untuk menerapkan algoritme INSTAN dan INPLACE tersebut. Misalnya, untuk algoritma INSTANT dan INPLACE, mengubah tipe data kolom juga merupakan tugas DBA yang biasa, terutama dalam perspektif pengembangan aplikasi karena perubahan data. Kesempatan ini tidak bisa dihindari; dengan demikian, Anda tidak dapat melanjutkan dengan algoritma COPY karena ini mengunci tabel yang menyebabkan penundaan pada slave. Ini juga berdampak pada server utama/master selama eksekusi ini karena menumpuk transaksi masuk yang juga merujuk tabel yang terpengaruh. Anda tidak dapat melakukan ALTER atau perubahan skema langsung pada server yang sibuk karena ini menyertai waktu henti atau mungkin merusak database Anda jika Anda kehilangan kesabaran, terutama jika tabel target sangat besar.
Memang benar bahwa melakukan perubahan skema pada penyiapan produksi yang berjalan selalu merupakan tugas yang menantang. Solusi yang sering digunakan adalah menerapkan perubahan skema ke node slave terlebih dahulu. Ini berfungsi dengan baik untuk replikasi berbasis pernyataan, tetapi ini hanya dapat berfungsi hingga tingkat tertentu untuk replikasi berbasis baris. Replikasi berbasis baris memungkinkan kolom tambahan ada di akhir tabel, jadi selama itu bisa menulis kolom pertama, itu akan baik-baik saja. Pertama, terapkan perubahan ke semua budak, lalu failover ke salah satu budak dan kemudian terapkan perubahan ke master dan lampirkan itu sebagai budak. Jika perubahan Anda melibatkan penyisipan kolom di tengah atau menghapus kolom, ini akan berfungsi dengan replikasi berbasis baris.
Ada alat yang tersedia yang dapat melakukan perubahan skema online dengan lebih andal. Perubahan Skema Online Percona (dikenal sebagai pt-osc) dan gh-ost oleh Schlomi Noach biasanya digunakan oleh DBA. Alat-alat ini menangani perubahan skema secara efektif dengan mengelompokkan baris yang terpengaruh ke dalam potongan, dan potongan ini dapat dikonfigurasi sesuai dengan jumlah yang ingin Anda kelompokkan.
Jika Anda akan melompat dengan pt-osc, alat ini akan membuat tabel bayangan dengan struktur tabel baru, menyisipkan data baru melalui pemicu dan mengisi ulang data di latar belakang. Setelah selesai membuat tabel baru, itu hanya akan menukar yang lama dengan tabel baru di dalam transaksi. Ini tidak berfungsi di semua kasus, terutama jika tabel Anda yang ada sudah memiliki pemicu.
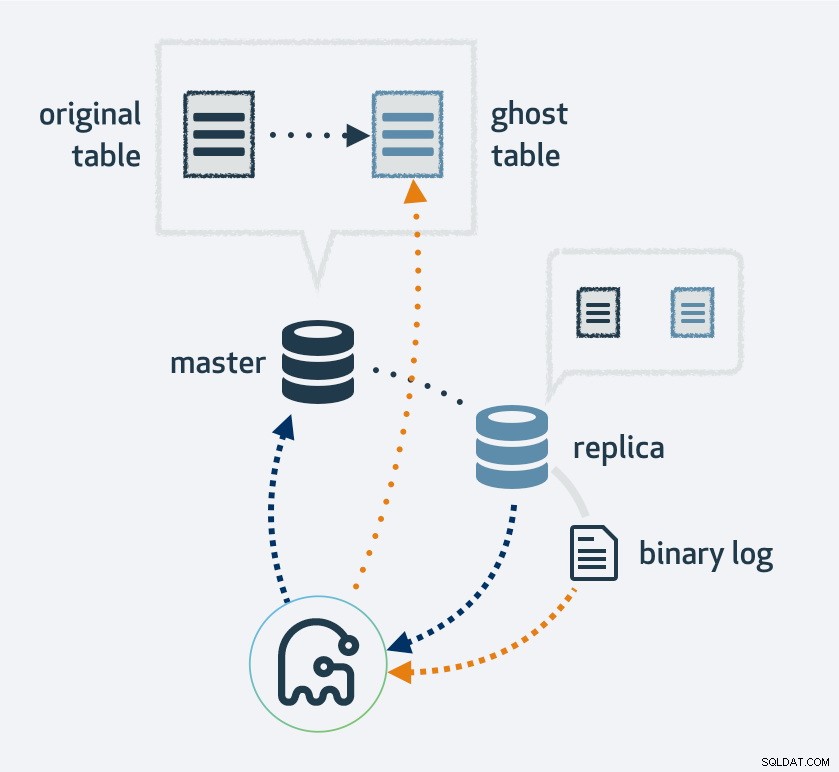
Menggunakan gh-ost pertama-tama akan membuat salinan tata letak tabel yang ada, ubah tabel ke tata letak baru, lalu sambungkan prosesnya sebagai replika MySQL. Ini akan menggunakan aliran replikasi untuk menemukan baris baru yang telah dimasukkan ke dalam tabel asli dan, pada saat yang sama, mengisi ulang tabel. Setelah pengisian ulang selesai, tabel asli dan baru akan beralih. Secara alami, semua operasi ke tabel baru akan berakhir di aliran replikasi; jadi, pada setiap replika, migrasi terjadi secara bersamaan.
Tabel dan Replikasi Memori
Sementara kita membahas DDL, masalah umum adalah pembuatan tabel memori. Tabel memori adalah tabel non-persisten, struktur tabelnya tetap ada, tetapi mereka kehilangan datanya setelah restart MySQL. Saat membuat tabel memori baru pada master dan slave, mereka akan memiliki tabel kosong, yang akan berfungsi dengan baik. Setelah salah satu dimulai ulang, tabel akan dikosongkan, dan kesalahan replikasi akan terjadi.
Replikasi berbasis baris akan rusak setelah data di node slave mengembalikan hasil yang berbeda, dan replikasi berbasis pernyataan akan berhenti setelah mencoba memasukkan data yang sudah ada. Untuk tabel memori, ini adalah pemutus replikasi yang sering. Cara mengatasinya mudah:buat salinan data baru, ubah mesin ke InnoDB, dan sekarang seharusnya replikasi aman.
Menyetel read_only={Benar|1}
Tentu saja, ini adalah kasus yang mungkin terjadi saat Anda menggunakan topologi ring, dan kami tidak menyarankan penggunaan topologi ring jika memungkinkan. Kami jelaskan sebelumnya, bahwa tidak memiliki data yang sama di node budak dapat merusak replikasi. Seringkali, ini disebabkan oleh sesuatu (atau seseorang) yang mengubah data pada node slave tetapi tidak pada node master. Setelah data master node diubah, ini akan direplikasi ke slave di mana ia tidak dapat menerapkan perubahan, dan ini menyebabkan replikasi terputus. Hal ini juga dapat menyebabkan korupsi data di tingkat cluster, terutama jika slave telah dipromosikan atau gagal karena crash. Itu bisa menjadi bencana.
Pencegahan mudah untuk hal ini adalah dengan memastikan read_only dan super_read_only (hanya pada> 5.6) disetel ke ON atau 1. Anda mungkin telah memahami perbedaan kedua variabel ini dan pengaruhnya jika Anda menonaktifkan atau mengaktifkan mereka. Dengan super_read_only (sejak MySQL 5.7.8) dinonaktifkan, pengguna root dapat mencegah perubahan apa pun pada target atau replika. Jadi ketika keduanya dinonaktifkan, ini akan melarang siapa pun untuk membuat perubahan pada data, kecuali untuk replikasi. Sebagian besar pengelola failover, seperti ClusterControl, menyetel tanda ini secara otomatis untuk mencegah pengguna menulis ke master yang digunakan selama failover. Beberapa dari mereka bahkan mempertahankan ini setelah failover.
Mengaktifkan GTID
Dalam replikasi MySQL, memulai slave dari posisi yang benar dalam log biner sangat penting. Memperoleh posisi ini dapat dilakukan saat membuat cadangan (xtrabackup dan mysqldump mendukung ini) atau ketika Anda telah berhenti bekerja pada simpul yang Anda buat salinannya. Memulai replikasi dengan perintah CHANGE MASTER TO akan terlihat seperti ini:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Memulai replikasi di tempat yang salah dapat berakibat fatal:data mungkin ditulis ganda atau tidak diperbarui. Hal ini menyebabkan penyimpangan data antara master dan node slave.
Juga, kegagalan dari master ke slave melibatkan menemukan posisi yang benar dan mengubah master ke host yang sesuai. MySQL tidak menyimpan log dan posisi biner dari masternya, melainkan membuat log dan posisi binernya sendiri. Ini bisa menjadi masalah serius untuk menyelaraskan kembali node budak ke master baru. Posisi yang tepat dari master pada failover harus ditemukan pada master baru, dan kemudian semua slave dapat diatur kembali.
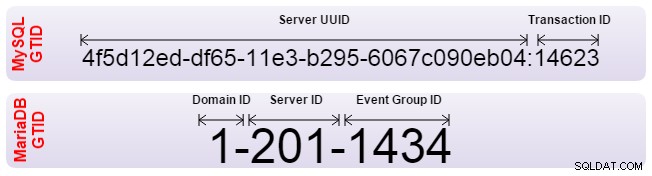
Baik Oracle MySQL dan MariaDB telah mengimplementasikan Pengidentifikasi Transaksi Global (GTID) untuk memecahkan masalah ini. GTID memungkinkan penyelarasan otomatis budak, dan server menentukan sendiri posisi yang benar. Namun, keduanya menerapkan GTID secara berbeda dan karenanya tidak kompatibel. Jika Anda perlu mengatur replikasi dari satu ke yang lain, replikasi harus diatur dengan pemosisian log biner tradisional. Selain itu, perangkat lunak failover Anda harus diberi tahu agar tidak menggunakan GTID.
Budak yang Aman dari Kecelakaan
Crash safe berarti meskipun MySQL/OS slave mogok, Anda dapat memulihkan slave dan melanjutkan replikasi tanpa mengembalikan database MySQL ke slave. Untuk membuat slave aman crash, Anda harus menggunakan mesin penyimpanan InnoDB saja, dan di 5.6, Anda perlu mengatur relay_log_info_repository=TABLE dan relay_log_recovery=1.
Kesimpulan
Latihan memang membuat sempurna, tetapi tanpa pelatihan dan pengetahuan yang tepat tentang teknik-teknik penting ini, itu bisa merepotkan atau menyebabkan bencana. Praktik ini biasanya dipatuhi oleh para ahli di MySQL dan diadaptasi oleh industri besar sebagai bagian dari pekerjaan rutin harian mereka saat mengelola Replikasi MySQL di server database produksi.
Jika Anda ingin membaca lebih lanjut tentang Replikasi MySQL, lihat tutorial ini tentang replikasi MySQL untuk ketersediaan tinggi.
Untuk pembaruan lebih lanjut tentang solusi manajemen basis data dan praktik terbaik untuk basis data berbasis sumber terbuka Anda, ikuti kami di Twitter dan LinkedIn dan berlangganan buletin kami.