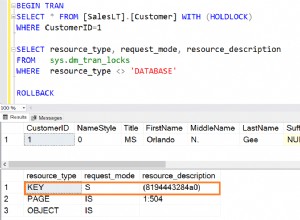
Thilo menemukan perbedaannya dengan tepat... COUNT( column_name ) dapat mengembalikan angka yang lebih rendah dari COUNT( * ) jika column_name bisa NULL .
Namun, jika saya dapat mengambil sudut pandang yang sedikit berbeda dalam menjawab pertanyaan Anda, karena Anda tampaknya berfokus pada kinerja.
Pertama, perhatikan bahwa mengeluarkan SELECT COUNT(*) FROM table; akan berpotensi memblokir penulis, dan juga akan diblokir oleh pembaca/penulis lain kecuali Anda telah mengubah tingkat isolasi (knee-jerk cenderung WITH (NOLOCK) tapi saya melihat sejumlah orang yang menjanjikan akhirnya mulai percaya pada RCSI). Yang berarti bahwa saat Anda membaca data untuk mendapatkan hitungan "akurat", semua permintaan DML ini menumpuk, dan ketika Anda akhirnya melepaskan semua kunci Anda, pintu air terbuka, sekelompok sisipkan/perbarui/hapus aktivitas terjadi, dan begitulah hitungan "akurat" Anda.
Jika Anda membutuhkan jumlah baris yang benar-benar konsisten dan akurat secara transaksional (meskipun hanya valid untuk jumlah milidetik yang diperlukan untuk mengembalikan nomor tersebut kepada Anda), maka SELECT COUNT( * ) adalah satu-satunya pilihan Anda.
Di sisi lain, jika Anda mencoba untuk mendapatkan rata-rata akurat 99,9%, Anda jauh lebih baik dengan kueri seperti ini:
SELECT row_count = SUM(row_count)
FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('dbo.Table')
AND index_id IN (0,1);
(SUM apakah ada untuk memperhitungkan tabel yang dipartisi - jika Anda tidak menggunakan partisi tabel, Anda dapat mengabaikannya.)
DMV ini mempertahankan jumlah baris yang akurat untuk tabel dengan pengecualian baris yang saat ini berpartisipasi dalam transaksi - dan transaksi itulah yang akan membuat SELECT COUNT Anda kueri tunggu (dan akhirnya membuatnya tidak akurat sebelum Anda punya waktu untuk membacanya). Tetapi jika tidak, ini akan menghasilkan jawaban yang jauh lebih cepat daripada kueri yang Anda usulkan, dan tidak kalah akuratnya dengan menggunakan WITH (NOLOCK) .