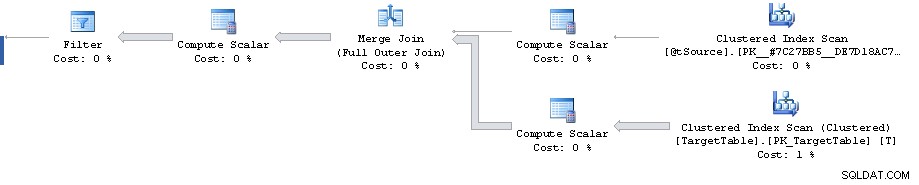
Biaya subpohon harus diambil dengan sebutir garam yang besar (dan terutama ketika Anda memiliki kesalahan kardinalitas yang besar). SET STATISTICS IO ON; SET STATISTICS TIME ON; keluaran adalah indikator kinerja aktual yang lebih baik.
Pengurutan baris nol tidak membutuhkan 87% sumber daya. Masalah dalam rencana Anda ini adalah salah satu estimasi statistik. Biaya yang ditampilkan dalam rencana sebenarnya masih merupakan biaya perkiraan. Itu tidak menyesuaikan mereka untuk memperhitungkan apa yang sebenarnya terjadi.
Ada titik dalam rencana di mana filter mengurangi 1.911.721 baris menjadi 0 tetapi perkiraan baris ke depan adalah 1.860.310. Setelah itu semua biaya palsu yang berpuncak pada perkiraan biaya 87% 3.348.560 baris.
Kesalahan estimasi kardinalitas dapat direproduksi di luar Merge pernyataan dengan melihat perkiraan rencana untuk Full Outer Join dengan predikat yang setara (memberikan perkiraan baris 1.860.310 yang sama).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
Meski begitu, rencananya hingga filternya sendiri memang terlihat cukup sub optimal. Itu melakukan pemindaian indeks berkerumun penuh ketika mungkin Anda menginginkan rencana dengan 2 pencarian rentang indeks berkerumun. Satu untuk mengambil satu baris yang cocok dengan kunci utama dari gabungan pada sumber dan yang lainnya untuk mengambil T.Key1 = @id range (meskipun mungkin ini untuk menghindari kebutuhan untuk mengurutkan ke dalam urutan kunci berkerumun nanti?)
Mungkin Anda dapat mencoba penulisan ulang ini dan melihat apakah ini berfungsi lebih baik atau lebih buruk
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;