Pengoptimal SQL Server memang mengandung logika untuk menghapus gabungan yang berlebihan, tetapi ada batasan, dan gabungan harus terbukti berlebihan . Untuk meringkas, bergabung dapat memiliki empat efek:
- Dapat menambahkan kolom tambahan (dari tabel yang digabungkan)
- Dapat menambahkan baris tambahan (tabel yang digabungkan mungkin cocok dengan baris sumber lebih dari satu kali)
- Dapat menghapus baris (tabel yang digabungkan mungkin tidak cocok)
- Dapat memperkenalkan
NULLs (untukRIGHTatauFULL JOIN)
Agar berhasil menghapus gabungan yang berlebihan, kueri (atau tampilan) harus memperhitungkan keempat kemungkinan. Ketika ini dilakukan, dengan benar, efeknya bisa menakjubkan. Misalnya:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
Pengoptimal berhasil dapat menyederhanakan kueri berikut:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
Kepada:

Rob Farley menulis tentang ide-ide ini secara mendalam di buku MVP Deep Dives asli , dan ada rekaman presentasinya tentang topik di SQLBits.
Batasan utama adalah bahwa hubungan kunci asing harus didasarkan pada satu kunci untuk berkontribusi pada proses penyederhanaan, dan waktu kompilasi untuk kueri terhadap tampilan seperti itu mungkin menjadi cukup lama terutama karena jumlah gabungan meningkat. Mungkin cukup sulit untuk menulis tampilan 100 tabel yang membuat semua semantik benar-benar tepat. Saya cenderung mencari solusi alternatif, mungkin menggunakan SQL dinamis .
Yang mengatakan, kualitas tertentu dari tabel denormalized Anda mungkin berarti tampilan cukup sederhana untuk dirakit, hanya membutuhkan FOREIGN KEYs yang dipaksakan. non-NULL kolom yang dapat direferensikan, dan UNIQUE yang sesuai kendala untuk membuat solusi ini bekerja seperti yang Anda harapkan, tanpa overhead 100 operator gabungan fisik dalam rencana.
Contoh
Menggunakan sepuluh tabel daripada seratus:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
Definisi tabel induk (dengan kompresi halaman):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
Pemandangan:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Meretas statistik untuk membuat pengoptimal berpikir tabelnya sangat besar:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Contoh kueri pengguna:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Memberi kami rencana eksekusi ini:
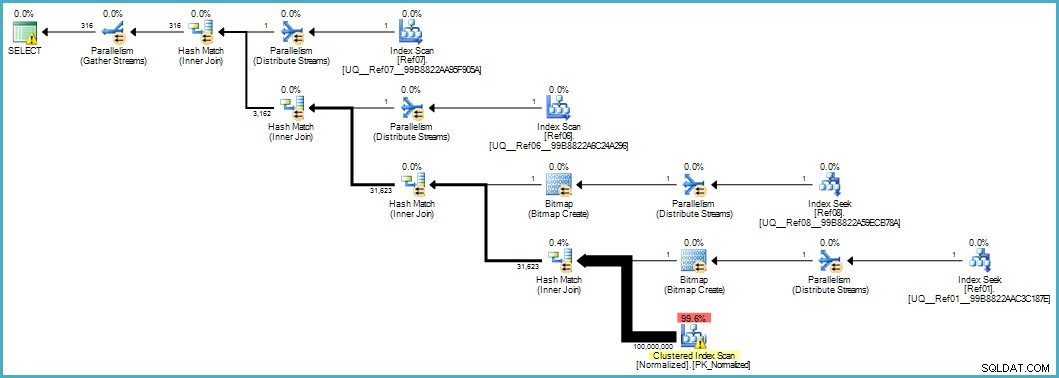
Pemindaian tabel Normalisasi terlihat buruk, tetapi kedua bitmap filter Bloom diterapkan selama pemindaian oleh mesin penyimpanan (sehingga baris yang tidak cocok bahkan tidak muncul sejauh prosesor kueri). Ini mungkin cukup untuk memberikan kinerja yang dapat diterima dalam kasus Anda, dan tentu saja lebih baik daripada memindai tabel asli dengan kolomnya yang meluap.
Jika Anda dapat meningkatkan ke SQL Server 2012 Enterprise pada tahap tertentu, Anda memiliki opsi lain:membuat indeks penyimpanan kolom pada tabel Normalisasi:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
Rencana eksekusi adalah:
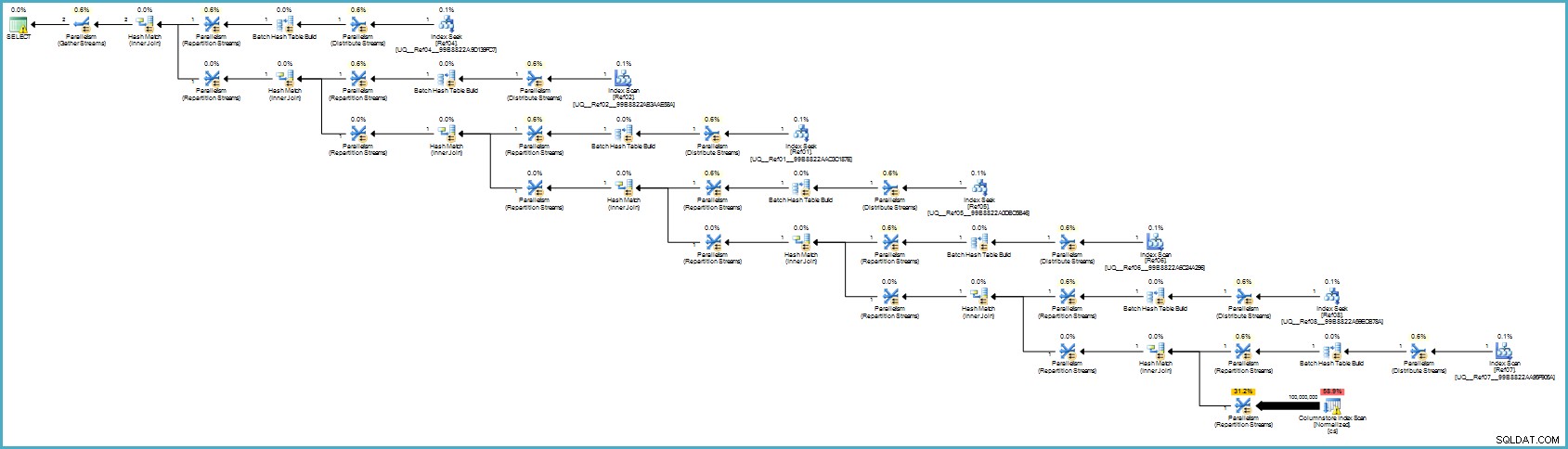
Itu mungkin terlihat lebih buruk bagi Anda, tetapi penyimpanan kolom memberikan kompresi yang luar biasa, dan seluruh rencana eksekusi berjalan dalam Mode Batch dengan filter untuk semua kolom yang berkontribusi. Jika server memiliki utas dan memori yang memadai, alternatif ini dapat benar-benar terbang.
Pada akhirnya, saya tidak yakin normalisasi ini adalah pendekatan yang benar mengingat jumlah tabel dan kemungkinan mendapatkan rencana eksekusi yang buruk atau membutuhkan waktu kompilasi yang berlebihan. Saya mungkin akan memperbaiki skema tabel yang didenormalisasi terlebih dahulu (tipe data yang tepat dan seterusnya), mungkin menerapkan kompresi data...hal-hal yang biasa.
Jika data benar-benar termasuk dalam skema bintang, mungkin diperlukan lebih banyak pekerjaan desain daripada hanya memisahkan elemen data berulang ke dalam tabel terpisah.