Peragaan penjelasan yang mungkin.
Buat Skrip tabel
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
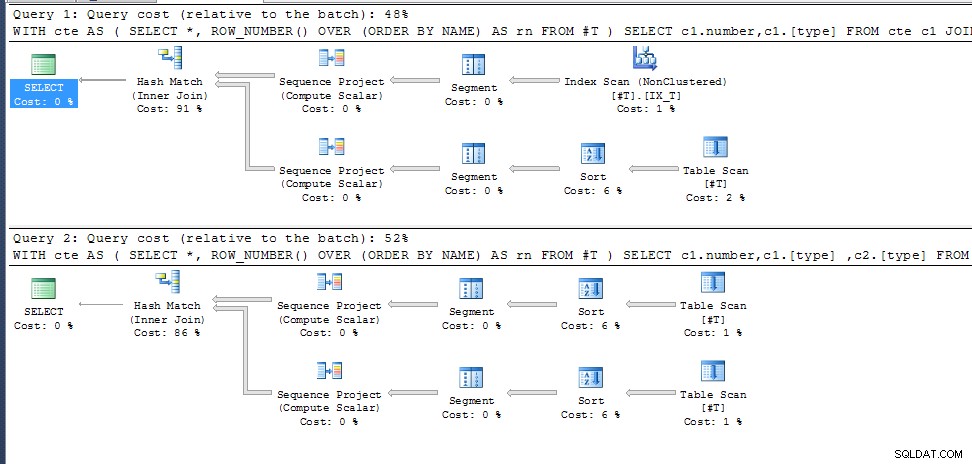
Kueri satu (Mengembalikan 35 hasil)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Kueri Dua (Sama seperti sebelumnya tetapi menambahkan c2.[type] ke daftar pilih membuatnya mengembalikan 0 hasil);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Mengapa?
row_number() untuk NAMA duplikat tidak ditentukan sehingga hanya memilih mana yang cocok dengan rencana eksekusi terbaik untuk kolom keluaran yang diperlukan. Dalam kueri kedua ini sama untuk kedua pemanggilan cte, pada kueri pertama ia memilih jalur akses yang berbeda dengan hasil penomoran baris yang berbeda.
Solusi yang Disarankan
Anda sendiri bergabung dengan CTE pada ROW_NUMBER() over (order by t.[Date])
Bertentangan dengan apa yang mungkin diharapkan, CTE kemungkinan akan tidak terwujud
yang akan memastikan konsistensi untuk self join dan dengan demikian Anda mengasumsikan korelasi antara ROW_NUMBER() di kedua sisi yang mungkin tidak ada untuk catatan di mana duplikat [Date] ada dalam data.
Bagaimana jika Anda mencoba ROW_NUMBER() over (order by t.[Date], t.[id]) untuk memastikan bahwa jika ada tanggal yang terikat, penomoran_baris dalam urutan yang dijamin konsisten. (Atau beberapa kolom/kombinasi kolom lain yang dapat membedakan record jika id tidak melakukannya)