Ada beberapa hal yang perlu diperhatikan di sini:
-
Jika Anda ingin melihat dengan tepat karakter mana yang ada, Anda dapat mengonversi nilainya menjadi
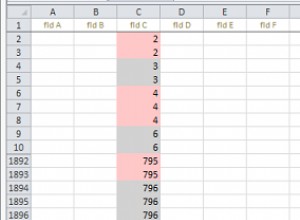
VARBINARYyang akan memberi Anda nilai hex / biner dari semua karakter dalam string dan tidak ada konsep karakter "tersembunyi" dalam hex:DECLARE @PostalCode NVARCHAR(20); SET @PostalCode = N'053000'+ NCHAR(0x2008); -- 0x2008 = "Punctuation Space" SELECT @PostalCode AS [NVarCharValue], CONVERT(VARCHAR(20), @PostalCode) AS [VarCharValue], CONVERT(VARCHAR(20), RTRIM(@PostalCode)) AS [RTrimmedVarCharValue], CONVERT(VARBINARY(20), @PostalCode) AS [VarBinaryValue];Pengembalian:
NVarCharValue VarCharValue RTrimmedVarCharValue VarBinaryValue 053000 053000? 053000? 0x3000350033003000300030000820NVARCHARdata disimpan sebagai UTF-16 yang bekerja dalam set 2-byte. Melihat 4 digit hex terakhir untuk melihat apa set 2-byte yang tersembunyi, kita melihat "0820". Karena Windows dan SQL Server adalah UTF-16 Little Endian (yaitu UTF-16LE), byte berada dalam urutan terbalik. Membalik 2 byte terakhir --08dan20-- kita mendapatkan "2008", yang merupakan "Ruang Tanda Baca" yang kita tambahkan melaluiNCHAR(0x2008).Juga, harap perhatikan bahwa
RTRIMtidak membantu sama sekali di sini. -
Sederhananya, Anda bisa mengganti tanda tanya dengan apa-apa:
SELECT REPLACE(CONVERT(VARCHAR(20), [PostalCode]), '?', ''); -
Lebih penting lagi, Anda harus mengonversi
[PostalCode]bidang keVARCHARsehingga tidak menyimpan karakter ini. Tidak ada negara yang menggunakan huruf yang tidak terwakili dalam rangkaian karakter ASCII dan yang tidak valid untuk tipe data VARCHAR, setidaknya sejauh yang pernah saya baca (lihat bagian bawah untuk referensi). Faktanya, apa yang diperbolehkan adalah subset ASCII yang agak kecil, yang berarti Anda dapat dengan mudah memfilter saat masuk (atau cukup lakukanREPLACEyang sama seperti yang ditunjukkan di atas saat memasukkan atau memperbarui):ALTER TABLE [table] ALTER COLUMN [PostalCode] VARCHAR(20) [NOT]? NULL;Pastikan untuk memeriksa
NULLsaat ini /NOT NULLsetting untuk kolom dan buat sama dengan pernyataan ALTER di atas, kalau tidak bisa diubah karena defaultnya adalahNULLjika tidak ditentukan. -
Jika Anda tidak dapat mengubah skema tabel dan perlu melakukan "pembersihan" berkala dari data yang buruk, Anda dapat menjalankan yang berikut:
;WITH cte AS ( SELECT * FROM TableName WHERE [PostalCode] <> CONVERT(NVARCHAR(50), CONVERT(VARCHAR(50), [PostalCode])) ) UPDATE cte SET cte.[PostalCode] = REPLACE(CONVERT(VARCHAR(50), [PostalCode]), '?', '');Harap diingat bahwa kueri di atas tidak dimaksudkan untuk bekerja secara efisien jika tabel memiliki jutaan baris. Pada saat itu perlu ditangani dalam set yang lebih kecil melalui loop.
Untuk referensi, berikut adalah artikel wikipedia untuk Kode pos , yang saat ini menyatakan bahwa satu-satunya karakter yang pernah digunakan adalah:
Dan mengenai ukuran maksimum bidang, berikut adalah Daftar kode pos Wikipedia