Hai,
Penggunaan Indeks dalam database SQL Server terjadi di lingkungan yang membutuhkan kinerja, kecepatan, dan penghematan memori paling banyak.
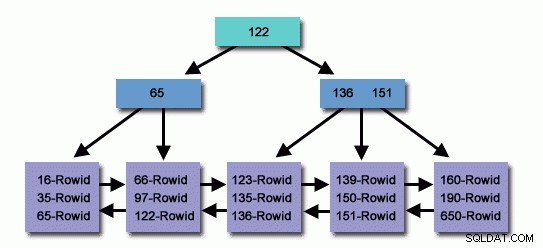
Dalam tabel dengan jutaan atau miliaran catatan, kita dapat menggunakan Indeks untuk membaca lebih sedikit catatan dan lebih sedikit menelusuri untuk menemukan catatan terkait.
Indeks yang dibuat secara akurat, jutaan catatan dalam database kami telah mencari dalam waktu yang sangat singkat untuk membawa catatan kenyamanan pemanggil, sementara pada saat yang sama kurang membaca catatan dengan mencapai catatan target, kami menggunakan sumber daya sistem operasi secara efektif.
Anda harus membuat indeks untuk sebagian besar kueri hanya baca di tabel. Jika Hapus, operasi pembaruan lebih dari sekadar kueri baca, Anda tidak boleh membuat indeks tabel itu.
Anda dapat melihat rekomendasi indeks yang hilang dari SQL Server dengan skrip berikut. Anda dapat membuat indeks yang hilang tetapi Anda harus memantau indeks ini, Jika tidak berguna, Anda harus menghapusnya.
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;