Penggabungan yang dikelompokkan adalah masalah umum di SQL Server, tanpa fitur langsung dan disengaja untuk mendukungnya (seperti XMLAGG di Oracle, STRING_AGG atau ARRAY_TO_STRING(ARRAY_AGG()) di PostgreSQL, dan GROUP_CONCAT di MySQL). Telah diminta, tetapi belum berhasil, sebagaimana dibuktikan dalam item Connect berikut:
- Hubungkan #247118 :SQL membutuhkan versi fungsi MySQL group_Concat (Ditunda)
- Hubungkan #728969 :Fungsi Kumpulan yang Diurutkan – DALAM Klausa GRUP (Ditutup karena Tidak Dapat Diperbaiki)
** PEMBARUAN Januari 2017 * :STRING_AGG() akan berada di SQL Server 2017; baca di sini, di sini, dan di sini.
Apa itu Penggabungan Berkelompok?
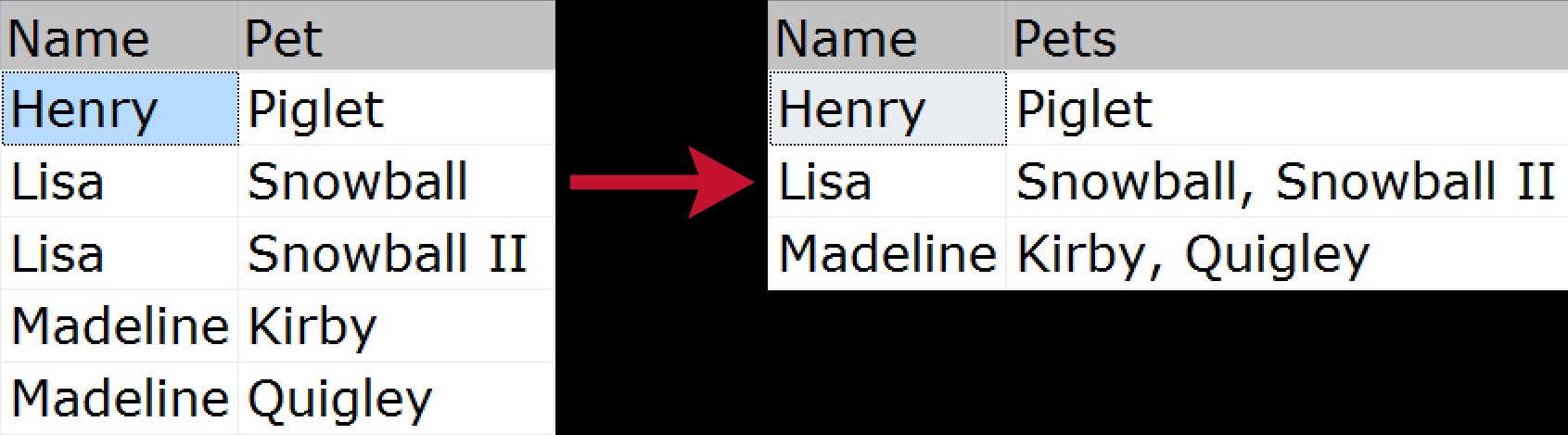
Untuk yang belum tahu, penggabungan yang dikelompokkan adalah saat Anda ingin mengambil beberapa baris data dan mengompresnya menjadi satu string (biasanya dengan pembatas seperti koma, tab, atau spasi). Beberapa orang mungkin menyebut ini sebagai "penggabungan horizontal". Contoh visual cepat yang menunjukkan bagaimana kami akan mengompresi daftar hewan peliharaan milik setiap anggota keluarga, dari sumber yang dinormalisasi hingga keluaran "diratakan":
Ada banyak cara untuk memecahkan masalah ini selama bertahun-tahun; berikut adalah beberapa, berdasarkan data sampel berikut:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Saya tidak akan menunjukkan daftar lengkap dari setiap pendekatan penggabungan yang dikelompokkan yang pernah dibuat, karena saya ingin fokus pada beberapa aspek dari pendekatan yang saya rekomendasikan, tetapi saya ingin menunjukkan beberapa yang lebih umum:
UDF Skalar
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Catatan:ada alasan mengapa kami tidak melakukan ini:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Dengan DISTINCT , fungsi dijalankan untuk setiap baris, kemudian duplikat dihapus; dengan GROUP BY , duplikatnya dihapus terlebih dahulu.
Waktu Proses Bahasa Umum (CLR)
Ini menggunakan GROUP_CONCAT_S fungsi ditemukan di https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
CTE Rekursif
Ada beberapa variasi pada rekursi ini; yang ini mengeluarkan serangkaian nama berbeda sebagai jangkar:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); kursor
Tidak banyak yang bisa dikatakan di sini; kursor biasanya bukan pendekatan yang optimal, tetapi ini mungkin satu-satunya pilihan Anda jika Anda terjebak di SQL Server 2000:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Pembaruan Unik
Beberapa orang *suka* pendekatan ini; Saya sama sekali tidak mengerti daya tariknya.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; UNTUK JALAN XML
Cukup mudah metode pilihan saya, setidaknya sebagian karena itu adalah satu-satunya cara untuk *menjamin* pesanan tanpa menggunakan kursor atau CLR. Yang mengatakan, ini adalah versi yang sangat mentah yang gagal untuk mengatasi beberapa masalah bawaan lainnya yang akan saya bahas lebih lanjut di:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Saya telah melihat banyak orang salah mengira bahwa CONCAT() new yang baru fungsi yang diperkenalkan di SQL Server 2012 adalah jawaban atas permintaan fitur ini. Fungsi itu hanya dimaksudkan untuk beroperasi terhadap kolom atau variabel dalam satu baris; itu tidak dapat digunakan untuk menggabungkan nilai di seluruh baris.
Selengkapnya tentang UNTUK XML PATH
FOR XML PATH('') sendiri tidak cukup baik – ia telah mengetahui masalah dengan entitas XML. Misalnya, jika Anda memperbarui salah satu nama hewan peliharaan untuk menyertakan tanda kurung HTML atau ampersand:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Ini diterjemahkan ke entitas aman XML di suatu tempat di sepanjang jalan:
Qui>gle&y
Jadi saya selalu menggunakan PATH, TYPE).value() , sebagai berikut:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Saya juga selalu menggunakan NVARCHAR , karena Anda tidak pernah tahu kapan beberapa kolom yang mendasari akan berisi Unicode (atau yang lebih baru diubah untuk melakukannya).
Anda mungkin melihat varietas berikut di dalam .value() , atau bahkan yang lain:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Ini dapat dipertukarkan, semuanya pada akhirnya mewakili string yang sama; perbedaan kinerja di antara mereka (lebih lanjut di bawah) dapat diabaikan dan mungkin sama sekali tidak deterministik.
Masalah lain yang mungkin Anda temui adalah karakter ASCII tertentu yang tidak mungkin direpresentasikan dalam XML; misalnya, jika string berisi karakter 0x001A (CHAR(26) ), Anda akan mendapatkan pesan kesalahan ini:
UNTUK XML tidak dapat membuat serial data untuk node 'NoName' karena berisi karakter (0x001A) yang tidak diperbolehkan dalam XML. Untuk mengambil data ini menggunakan FOR XML, konversikan ke tipe data biner, varbinary, atau gambar dan gunakan direktif BINARY BASE64.
Ini tampaknya cukup rumit bagi saya, tetapi mudah-mudahan Anda tidak perlu khawatir karena Anda tidak menyimpan data seperti ini atau setidaknya Anda tidak mencoba menggunakannya dalam rangkaian yang dikelompokkan. Jika ya, Anda mungkin harus kembali ke salah satu pendekatan lainnya.
Kinerja
Data sampel di atas memudahkan untuk membuktikan bahwa semua metode ini melakukan apa yang kita harapkan, tetapi sulit untuk membandingkannya secara bermakna. Jadi saya mengisi tabel dengan set yang jauh lebih besar:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
Bagi saya, ini adalah 575 objek, dengan total 7.080 baris; objek terluas memiliki 142 kolom. Sekarang lagi, harus diakui, saya tidak bermaksud membandingkan setiap pendekatan yang ada dalam sejarah SQL Server; hanya beberapa sorotan yang saya posting di atas. Berikut adalah hasilnya:
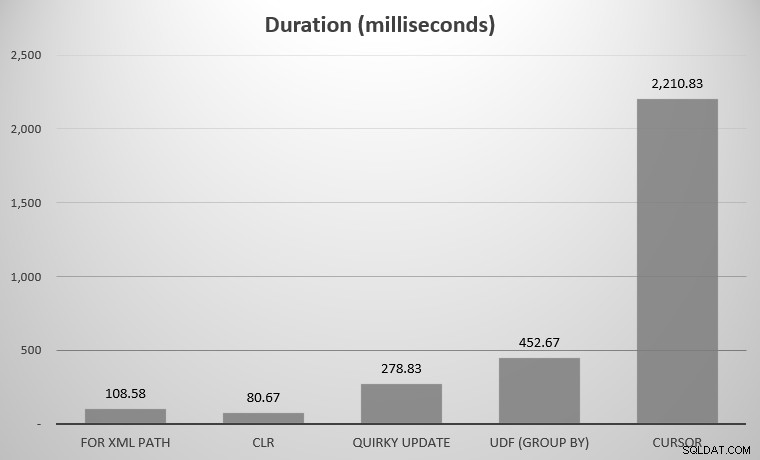
Anda mungkin melihat beberapa pesaing hilang; UDF menggunakan DISTINCT dan CTE rekursif sangat keluar dari grafik sehingga mereka akan mencondongkan skala. Berikut adalah hasil dari ketujuh pendekatan dalam bentuk tabel:
| Pendekatan | Durasi (milidetik) |
|---|---|
| UNTUK JALAN XML | 108,58 |
| CLR | 80,67 |
| Pembaruan Unik | 278,83 |
| UDF (GROUP BY) | 452,67 |
| UDF (DISTINCT) | 5.893,67 |
| Kursor | 2,210,83 |
| CTE Rekursif | 70,240.58 |
Durasi rata-rata, dalam milidetik, untuk semua pendekatan
Perhatikan juga bahwa variasi pada FOR XML PATH diuji secara independen tetapi menunjukkan perbedaan yang sangat kecil jadi saya hanya menggabungkannya untuk rata-rata. Jika Anda benar-benar ingin tahu, .[1] notasi bekerja paling cepat dalam pengujian saya; YMMV.
Kesimpulan
Jika Anda tidak berada di toko di mana CLR adalah penghalang jalan dengan cara apa pun, dan terutama jika Anda tidak hanya berurusan dengan nama sederhana atau string lain, Anda pasti harus mempertimbangkan proyek CodePlex. Jangan mencoba dan menemukan kembali roda, jangan mencoba trik dan peretasan yang tidak intuitif untuk membuat CROSS APPLY atau konstruksi lain bekerja sedikit lebih cepat daripada pendekatan non-CLR di atas. Ambil saja yang berhasil dan pasang. Dan heck, karena Anda mendapatkan kode sumbernya juga, Anda dapat memperbaikinya atau memperluasnya jika Anda mau.
Jika CLR menjadi masalah, maka FOR XML PATH kemungkinan merupakan pilihan terbaik Anda, tetapi Anda masih harus berhati-hati terhadap karakter yang rumit. Jika Anda terjebak pada SQL Server 2000, satu-satunya pilihan yang layak adalah UDF (atau kode serupa yang tidak dibungkus dalam UDF).
Lain kali
Beberapa hal yang ingin saya jelajahi dalam posting lanjutan:menghapus duplikat dari daftar, mengurutkan daftar dengan sesuatu selain nilai itu sendiri, kasus di mana menempatkan salah satu pendekatan ini ke dalam UDF bisa menyakitkan, dan kasus penggunaan praktis untuk fungsi ini.