SQL Server 2014 CTP1 telah keluar selama beberapa minggu sekarang, dan Anda mungkin telah melihat sedikit pers tentang tabel yang dioptimalkan memori dan indeks columnstore yang dapat diperbarui. Meskipun ini tentu patut diperhatikan, dalam posting ini saya ingin menjelajahi peningkatan paralelisme SELECT … INTO yang baru. Peningkatannya adalah salah satu perubahan siap pakai yang, dari tampilannya, tidak memerlukan perubahan kode yang signifikan untuk mulai memanfaatkannya. Eksplorasi saya dilakukan menggunakan versi Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Edisi Evaluasi Perusahaan.
PILIH Paralel … INTO
SQL Server 2014 memperkenalkan SELECT ... INTO yang diaktifkan secara paralel untuk database dan untuk menguji fitur ini saya menggunakan database AdventureWorksDW2012 dan versi tabel FactInternetSales yang memiliki 61.847.552 baris di dalamnya (saya bertanggung jawab untuk menambahkan baris tersebut; baris tersebut tidak disertakan dengan database secara default).
Karena fitur ini, pada CTP1, memerlukan tingkat kompatibilitas basis data 110, untuk tujuan pengujian saya mengatur basis data ke tingkat kompatibilitas 100 dan menjalankan kueri berikut untuk pengujian pertama saya:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; Durasi eksekusi kueri adalah 3 menit 19 detik pada VM pengujian saya dan rencana eksekusi kueri aktual yang dihasilkan adalah sebagai berikut:

SQL Server menggunakan paket serial, seperti yang saya harapkan. Perhatikan juga bahwa tabel saya memiliki indeks columnstore nonclustered di atasnya yang dipindai (saya membuat indeks columnstore nonclustered ini untuk digunakan dengan tes lain, tetapi saya akan menunjukkan rencana eksekusi kueri indeks columnstore clustered nanti juga). Paket tidak menggunakan paralelisme dan Pemindaian Indeks Columnstore menggunakan mode eksekusi baris alih-alih mode eksekusi batch.
Jadi selanjutnya, saya memodifikasi tingkat kompatibilitas database (dan perhatikan bahwa belum ada tingkat kompatibilitas SQL Server 2014 di CTP1):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Saya menjatuhkan tabel FactInternetSales_V2 dan kemudian menjalankan kembali SELECT ... INTO asli saya operasi. Kali ini durasi eksekusi kueri adalah 1 menit 7 detik dan rencana eksekusi kueri sebenarnya adalah sebagai berikut:
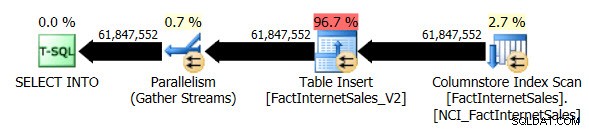
Kami sekarang memiliki paket paralel dan satu-satunya perubahan yang harus saya lakukan adalah pada tingkat kompatibilitas database untuk AdventureWorksDW2012. VM pengujian saya memiliki empat vCPU yang dialokasikan untuknya, dan rencana eksekusi kueri mendistribusikan baris ke empat utas:

Pemindaian Indeks Columnstore nonclustered, saat menggunakan paralelisme, tidak menggunakan mode eksekusi batch. Sebaliknya itu menggunakan mode eksekusi baris.
Berikut adalah tabel untuk menunjukkan hasil tes sejauh ini:
| Jenis Pemindaian | Tingkat kompatibilitas | PILIH Paralel … INTO | Mode Eksekusi | Durasi |
|---|---|---|---|---|
| Pemindaian Indeks Columnstore Tanpa Gugus | 100 | Tidak | Baris | 3:19 |
| Pemindaian Indeks Columnstore Tanpa Gugus | 110 | Ya | Baris | 1:07 |
Jadi sebagai tes berikutnya, saya menjatuhkan indeks columnstore nonclustered dan menjalankan kembali SELECT ... INTO kueri menggunakan tingkat kompatibilitas database 100 dan 110.
Tes tingkat kompatibilitas 100 membutuhkan waktu 5 menit dan 44 detik untuk dijalankan, dan rencana berikut dibuat:
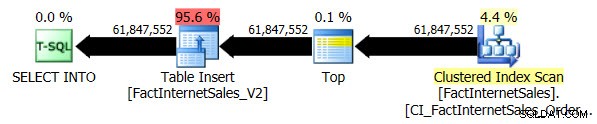
Pemindaian Indeks Clustered serial membutuhkan waktu 2 menit dan 25 detik lebih lama daripada Pemindaian Indeks Columnstore serial nonclustered.
Menggunakan tingkat kompatibilitas 110, kueri membutuhkan waktu 1 menit dan 55 detik untuk dijalankan, dan rencana berikut dibuat:

Mirip dengan tes Pemindaian Indeks Columnstore paralel nonclustered, Pemindaian Indeks Clustered paralel mendistribusikan baris di empat utas:
Tabel berikut merangkum dua pengujian yang disebutkan di atas:
| Jenis Pemindaian | Tingkat kompatibilitas | PILIH Paralel … INTO | Mode Eksekusi | Durasi |
|---|---|---|---|---|
| Pemindaian Indeks Berkelompok | 100 | Tidak | Baris (T/A) | 5:44 |
| Pemindaian Indeks Berkelompok | 110 | Ya | Baris (T/A) | 1:55 |
Jadi saya bertanya-tanya tentang kinerja untuk indeks columnstore berkerumun (baru di SQL Server 2014), jadi saya menjatuhkan indeks yang ada dan membuat indeks columnstore berkerumun di tabel FactInternetSales. Saya juga harus menghapus delapan batasan kunci asing yang berbeda yang ditentukan pada tabel sebelum saya dapat membuat indeks penyimpanan kolom berkerumun.
Diskusi menjadi agak akademis, karena saya membandingkan SELECT ... INTO kinerja pada tingkat kompatibilitas database yang tidak menawarkan indeks columnstore berkerumun di tempat pertama – juga tidak tes sebelumnya untuk indeks columnstore nonclustered pada tingkat kompatibilitas basis data 100 – namun menarik untuk melihat dan membandingkan karakteristik kinerja secara keseluruhan.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
Selain itu, operasi untuk membuat indeks penyimpanan kolom terklaster pada tabel baris 61.847.552 juta membutuhkan waktu 11 menit dan 25 detik dengan empat vCPU yang tersedia (di mana operasi tersebut memanfaatkan semuanya), RAM 4 GB, dan penyimpanan tamu virtual pada SSD OCZ Vertex. Selama waktu tersebut, CPU tidak dipatok sepanjang waktu, melainkan menampilkan puncak dan lembah (contoh aktivitas CPU selama 60 detik ditunjukkan di bawah):
Setelah indeks clustered columnstore dibuat, saya menjalankan kembali dua SELECT ... INTO tes. Tes tingkat kompatibilitas 100 membutuhkan waktu 3 menit dan 22 detik untuk dijalankan, dan rencananya adalah serial seperti yang diharapkan (Saya menunjukkan versi SQL Server Management Studio dari paket sejak Pemindaian Indeks Columnstore berkerumun, pada SQL Server 2014 CTP1 , belum sepenuhnya dikenali oleh Plan Explorer):

Selanjutnya saya mengubah tingkat kompatibilitas basis data menjadi 110 dan menjalankan ulang pengujian, yang kali ini kuerinya membutuhkan waktu 1 menit 11 detik dan memiliki rencana eksekusi aktual berikut:

Rencana tersebut mendistribusikan baris ke empat utas, dan seperti indeks penyimpanan kolom yang tidak terkelompok, mode eksekusi Pemindaian Indeks Toko Kolom yang dikelompokkan adalah baris dan bukan kumpulan.
Tabel berikut merangkum semua pengujian dalam postingan ini (dalam urutan durasi, rendah ke tinggi):
| Jenis Pemindaian | Tingkat kompatibilitas | PILIH Paralel … INTO | Mode Eksekusi | Durasi |
|---|---|---|---|---|
| Pemindaian Indeks Columnstore Tanpa Gugus | 110 | Ya | Baris | 1:07 |
| Pemindaian Indeks Toko Kolom Terkelompok | 110 | Ya | Baris | 1:11 |
| Pemindaian Indeks Berkelompok | 110 | Ya | Baris (T/A) | 1:55 |
| Pemindaian Indeks Columnstore Tanpa Gugus | 100 | Tidak | Baris | 3:19 |
| Pemindaian Indeks Toko Kolom Terkelompok | 100 | Tidak | Baris | 3:22 |
| Pemindaian Indeks Berkelompok | 100 | Tidak | Baris (T/A) | 5:44 |
Beberapa pengamatan:
- Saya tidak yakin apakah perbedaan antara paralel
SELECT ... INTOoperasi terhadap indeks columnstore nonclustered versus indeks columnstore berkerumun signifikan secara statistik. Saya perlu melakukan lebih banyak tes, tetapi saya pikir saya akan menunggu untuk melakukannya sampai RTM. - Saya dapat mengatakan bahwa paralel
SELECT ... INTOmelakukan secara signifikan mengungguli ekuivalen serial di seluruh indeks berkerumun, uji indeks columnstore nonclustered dan indeks columnstore berkerumun.
Perlu disebutkan bahwa hasil ini adalah untuk versi produk CTP, dan pengujian saya harus dilihat sebagai sesuatu yang dapat mengubah perilaku oleh RTM – jadi saya kurang tertarik pada durasi mandiri versus bagaimana durasi tersebut dibandingkan antara serial dan paralel kondisi.
Beberapa fitur kinerja memerlukan pemfaktoran ulang yang signifikan – tetapi untuk SELECT ... INTO peningkatan, yang harus saya lakukan hanyalah meningkatkan tingkat kompatibilitas database untuk mulai melihat manfaatnya, yang tentunya merupakan sesuatu yang saya hargai.



