Dalam artikel ini, kami akan membahas beberapa masalah yang mungkin Anda hadapi saat membuat, mengonfigurasi, atau memelihara situs Always on Availability Group.
Sebelum membaca artikel ini, disarankan untuk membaca artikel sebelumnya, Menyiapkan dan Mengonfigurasi Always on Availability Group di SQL Server, agar terbiasa dengan konsep Always on Availability Group dan wizard Grup Ketersediaan Baru yang ditampilkan di artikel ini.
Fitur Grup Selalu Tersedia Tidak Diaktifkan
Asumsikan bahwa, saat mencoba membuat Grup Always on Availability baru, dari node Always On High Availability, di bawah Object Explorer dari SQL Server Management Studio, Anda menghadapi pesan kesalahan di bawah ini:
Fitur Always On Availability Groups harus diaktifkan untuk instance server 'SQL1' sebelum Anda dapat membuat grup ketersediaan pada instance ini. Untuk mengaktifkan fitur ini, buka SQL Server Configuration Manager, pilih SQL Server Services, klik kanan pada nama layanan SQL Server, pilih Properties, dan gunakan tab Always On Availability Groups pada dialog Server Properties. Mengaktifkan Always On Availability Groups mungkin mengharuskan server instance di-host oleh node Windows Server Failover Cluster (WSFC). (Microsoft.SqlServer.Management.HadrTasks)

Jelas dari pesan kesalahan bahwa, fitur AlwaysOn Availability Groups harus diaktifkan pada setiap instance SQL Server yang berpartisipasi dalam situs Always on Availability Group, sebelum membuat situs tersebut.
Anda dapat dengan mudah mengaktifkan fitur Always on Availability Group, dengan membuka konsol SQL Server Configuration Manager, telusuri tab SQL Server Services lalu klik kanan pada layanan SQL Server Database Engine dan pilih opsi Properties.
Dari jendela Properti SQL Server yang terbuka, pindah ke tab Always on High Availability dan centang kotak di samping Aktifkan Always on Availability Group , dengan mempertimbangkan bahwa perubahan ini memerlukan restart layanan SQL Server untuk diterapkan, seperti yang ditunjukkan di bawah ini:

Masalah Validasi Prasyarat Basis Data
Pada langkah sebelumnya dari panduan Grup Ketersediaan Baru, Anda akan diminta untuk menentukan database yang akan berpartisipasi dalam Grup Ketersediaan Selalu. Sebelum menambahkan database, database harus lulus pemeriksaan validasi prasyarat. Jika tidak, database tidak dapat dipilih dari daftar database, seperti yang ditunjukkan pada pesan kesalahan di bawah ini:
Untuk ditambahkan ke grup ketersediaan, database ini harus disetel ke model pemulihan penuh. Atur properti database Model Pemulihan ke Penuh dan lakukan pencadangan database lengkap atau diferensial pada database. Anda kemudian perlu menjadwalkan pencadangan log di database.

Pesannya jelas. Dimana database harus dikonfigurasi dengan model pemulihan Penuh dan backup Penuh atau Diferensial harus dilakukan pada database tersebut.
Selain itu, wizard memperingatkan Anda untuk menjadwalkan pencadangan log transaksi untuk database tersebut setelah mengubah model pemulihan ke Penuh, untuk memotong file log transaksi secara otomatis dan mencegah menjalankan file log transaksi tersebut dari ruang kosong.
Untuk memperbaiki masalah itu, ubah model pemulihan basis data dari Sederhana ke Penuh, dari tab Opsi di jendela properti basis data, lalu ambil cadangan Penuh dari basis data itu, seperti yang ditunjukkan di bawah ini:

Refresh jendela Select Databases, status database akan berubah menjadi Meet Prequires, seperti yang ditunjukkan di bawah ini:

Masalah Izin Lokasi Jaringan Bersama
Saat mencoba mengonfigurasi situs Grup Ketersediaan Selalu, langkah validasi panduan Grup Ketersediaan Baru gagal dengan pesan kesalahan di bawah ini:
Server utama 'SQL1' tidak dapat menulis ke '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. (Microsoft.SqlServer.Management.HadrModel)
Pencadangan gagal untuk Server 'SQL1'. (Microsoft.SqlServer.SmoExtended)
Tidak dapat membuka perangkat cadangan '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. Kesalahan sistem operasi 5 (Akses ditolak.).
BACKUP DATABASE berhenti secara tidak normal. (Penyedia Data SqlClient Net)
Dalam metode sinkronisasi awal database dan cadangan log lengkap, folder bersama diperlukan untuk menyimpan file cadangan lengkap dan cadangan log transaksi sementara untuk memulihkannya ke semua replika sekunder. Jika replika Utama tidak dapat menulis file cadangan ke dalamnya, atau replika sekunder tidak dapat membaca file cadangan darinya, proses validasi Grup Ketersediaan Baru akan gagal seperti di bawah ini:

Untuk memperbaiki masalah itu, kami perlu memberikan akun Layanan SQL Server dari replika Primer dan Sekunder izin baca dan tulis pada folder bersama yang ditampilkan dalam pesan kesalahan, lalu jalankan kembali proses validasi, untuk memastikan bahwa semua pemeriksaan berhasil , seperti yang ditunjukkan di bawah ini:

Masalah Kluster Failover Windows
Asumsikan Anda sedang memeriksa status situs Always on Availability Group yang ada, dan lihat bahwa:
- Peran utama dipindahkan dari instance SQL1 ke SQL2.
- Dalam SQL2, database berada dalam status Disinkronkan.
- Dalam SQL1, database tidak disinkronkan.
- SQL1 dalam status Menyelesaikan.
Seperti yang dapat Anda lihat dengan jelas dari SSMS Object Explorer di bawah ini:

Memeriksa log SQL Server Error di node yang bermasalah, kita dapat melihat bahwa replika Availability Group menjadi offline dan Availability Group berhenti bekerja karena masalah di Windows Server Failover Cluster, seperti yang ditunjukkan pada kesalahan di bawah ini:
- Grup yang Selalu Tersedia:Node Pengelompokan Failover Server Windows Lokal tidak lagi online . Ini adalah pesan informasi saja. Tidak ada tindakan pengguna yang diperlukan.
- Selalu Aktif:Manajer replika ketersediaan akan offline karena node Windows Server Failover Clustering (WSFC) lokal telah kehilangan kuorum. Ini adalah pesan informasi saja. Tidak ada tindakan pengguna yang diperlukan.
- Selalu Aktif:Replika lokal dari grup ketersediaan 'DemoGroup' berhenti. Ini adalah pesan informasi saja. Tidak ada tindakan pengguna yang diperlukan.

Hal yang sama dapat dideteksi dari Windows Server Event Viewer, yang menunjukkan secara bertahap bagaimana replika mengubah statusnya menjadi status Penyelesaian, seperti di bawah ini:
- Selalu Aktif:Replika lokal grup ketersediaan 'DemoGroup' sedang bersiap untuk transisi ke peran penyelesaian . Ini adalah pesan informasi saja. Tidak ada tindakan pengguna yang diperlukan.
- Grup ketersediaan 'DemoGroup' diminta untuk menghentikan perpanjangan sewa karena grup ketersediaan sedang offline . Ini adalah pesan informasi saja. Tidak ada tindakan pengguna yang diperlukan.
- Status replika ketersediaan lokal di grup ketersediaan 'DemoGroup' telah berubah dari 'PRIMARY_NORMAL' menjadi 'RESOLVING_NORMAL'. Status berubah karena grup ketersediaan akan offline. Replika akan offline karena grup ketersediaan terkait telah dihapus, atau pengguna telah membuat grup ketersediaan terkait offline di konsol manajemen Windows Server Failover Clustering (WSFC), atau grup ketersediaan gagal ke contoh SQL Server lain. Untuk informasi selengkapnya, lihat log galat SQL Server atau log cluster. Jika ini adalah grup ketersediaan Windows Server Failover Clustering (WSFC), Anda juga dapat melihat konsol manajemen WSFC.

Untuk memeriksa status situs Windows Cluster, kita akan menggunakan Failover Cluster Manager untuk melihat bagian mana dari Windows Cluster yang gagal.
Tetapi Failover Cluster Manager menunjukkan bahwa seluruh cluster sedang down, seperti yang ditunjukkan di bawah ini:

Hal pertama yang harus divalidasi di sini dari sisi Windows Failover Cluster adalah Layanan Cluster, yang dapat diperiksa dari konsol Layanan Windows, seperti di bawah ini:

Jelas dari konsol Layanan, bahwa Layanan Cluster tidak berjalan. Untuk memperbaiki masalah itu, mulai layanan dari konsol itu, lalu segarkan konsol Failover Cluster Manager untuk memastikan bahwa situs Windows Cluster aktif dan berjalan, seperti yang ditunjukkan di bawah ini:

Memeriksa Grup Always on Availability lagi, Anda akan melihat bahwa database telah disinkronkan kembali dan situs Always on Availability Group dalam keadaan sehat kembali, seperti yang ditunjukkan di bawah ini:

File Log Transaksi Penuh di Sisi Utama
Misalnya Anda menerima pesan galat di bawah ini saat mencoba menjalankan kueri baru di salah satu database Always on Availability Group:

Memeriksa apa yang memblokir file log transaksi dan mencegahnya terpotong, Anda akan melihat bahwa file log transaksi dari database ini menunggu operasi pencadangan log untuk dipotong, seperti yang ditunjukkan di bawah ini:

Mengambil cadangan log transaksi untuk database tersebut, jika Anda lupa menjadwalkan pekerjaan pencadangan log transaksi, sebagai berikut:

Dan periksa lagi apa yang memblokir log transaksi dari database itu, itu menunjukkan dalam skenario saya bahwa, itu menunggu Availability_Replica. Artinya, log menunggu untuk ditulis ke replika sekunder, tetapi tidak dapat mengirim log transaksi ini ke replika sekunder karena masalah di situs Always on Availability Group, seperti di bawah ini:

Lokasi terbaik untuk memeriksa dan memecahkan masalah situs Always on Availability Group adalah Always on Dashboard, yang dapat dibuka dengan mengklik kanan nama Grup Ketersediaan dan memilih opsi Show Dashboard.
Dari dasbor, Anda dapat melihat bahwa replika SQL2 Sekunder tidak disinkronkan dengan replika Utama, karena masalah konektivitas, seperti yang ditunjukkan di bawah ini:

Memeriksa replika Sekunder, dan memastikan bahwa Layanan SQL Server aktif dan berjalan di sisi sekunder, sebagai berikut:

Kemudian refresh kembali dashboard Availability Group, Anda akan melihat bahwa situs Always on Availability Group sudah sehat kembali. Memeriksa apakah file log transaksi diblokir oleh operasi apa pun, kita akan melihat bahwa itu menunggu OLDEST_PAGE, menunjukkan bahwa halaman database tertua lebih tua dari LSN pos pemeriksaan. Masalah ini dapat diperbaiki dengan mudah dengan mengambil cadangan log transaksi lain dan file log transaksi tidak akan diblokir, seperti yang ditunjukkan dengan jelas di bawah ini:

Selalu di Availability Group Failover Misconfiguration
Misalnya replika utama menjadi offline karena masalah yang tidak direncanakan. Seperti yang diharapkan, sistem tidak akan terpengaruh karena operasi failover otomatis akan dilakukan dan replika sekunder akan bertindak sebagai replika Utama baru.
Namun dalam kasus kami, skenario bahagia ini tidak valid, di mana replika sekunder berubah menjadi status Penyelesaian dan sistem mati!

Memeriksa log kesalahan replika sekunder dan melihat mengapa itu tidak bertindak sebagai Utama baru seperti yang diharapkan, Anda akan melihat bahwa itu gagal karena masalah sinkronisasi peran, seperti yang ditunjukkan di bawah ini:
Database grup ketersediaan "AdventureWorks2017" mengubah peran dari "SECONDARY" menjadi "RESOLVING" karena sesi mirroring atau grup ketersediaan gagal karena sinkronisasi peran. Ini adalah pesan informasi saja. Tidak ada tindakan pengguna yang diperlukan.

Ini berarti ada masalah dengan mode sinkronisasi yang digunakan di Grup Ketersediaan ini. Mode sinkronisasi yang digunakan, dapat diperiksa dari halaman properti Always on Availability Group.
Dari halaman properti di bawah ini, jelas bahwa mode Failover di Grup Ketersediaan ini dikonfigurasi untuk dilakukan secara Manual saja. Dalam hal ini, Anda perlu melakukan operasi failover secara manual sebelum me-reboot atau mematikan server:

Ini dapat diperbaiki dengan mudah dengan mengubah Mode Failover ke Otomatis, di mana operasi failover otomatis akan dilakukan jika ada shutdown atau reboot yang tidak direncanakan:

Masalah yang sama dapat dihadapi ketika kuorum Windows Failover Cluster dikonfigurasi dengan Node Majority untuk jumlah replika yang genap, di mana setiap kegagalan untuk salah satu server akan membuat situs Windows Failover Cluster offline. Untuk informasi selengkapnya, periksa Mode Kuorum Failover Cluster Windows di SQL Server Always On Availability Groups:

Kegagalan dengan Kehilangan Data
Misalnya Anda mencoba melakukan failover manual antara Primer dan salah satu replika Sekunder, tetapi di jendela Select New Primary Replica, Anda melihat pesan peringatan bahwa operasi failover mungkin berakhir dengan kehilangan data sebagai Primer dan yang dipilih Replika sekunder tidak disinkronkan, seperti yang ditunjukkan di bawah ini:

Untuk mengidentifikasi penyebab masalah tersebut, kami akan menelusuri acara Always on Health menggunakan dasbor Always on Availability Group, yang menunjukkan bahwa replika Utama tidak dapat membuka koneksi ke replika Sekunder, seperti yang ditunjukkan di bawah ini:

Setelah memperbaiki masalah konektivitas antara Primer dan Sekunder, segarkan daftar replika dan Anda akan melihat bahwa masalah kehilangan data telah diperbaiki, seperti yang ditunjukkan di bawah ini. Untuk informasi selengkapnya tentang pemecahan masalah konektivitas, periksa Pemecahan masalah penyambungan ke SQL Server Database Engine.

Memantau Selalu Latensi Grup yang Tersedia
Dasbor Grup Ketersediaan dapat dimodifikasi untuk menyertakan kolom tambahan yang menyediakan informasi tentang latensi sinkronisasi antara replika Primer dan Sekunder, termasuk nilai Commit LSN, Sent LSN, dan harden LSN, tanpa menunjukkan mengapa ada latensi, seperti yang ditunjukkan di bawah ini:
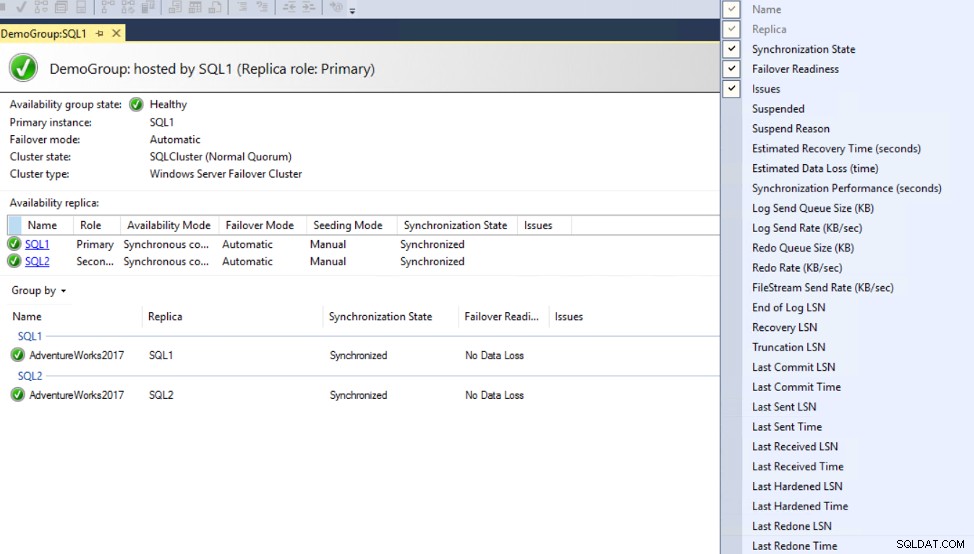
Untuk informasi selengkapnya tentang mengukur latensi, periksa jeda sinkronisasi Pengukuran Grup Ketersediaan.
Mulai dari SSMS 17.4, dasbor Always on Availability Group ditingkatkan untuk menyertakan dua opsi baru yang digunakan untuk penghitungan, analisis, dan pelaporan informasi latensi, yang membantu mengidentifikasi hambatan dalam aliran log transaksi antara replika Primer dan Sekunder dan mempersempit penyebab latensi tersebut.
Untuk informasi lebih lanjut tentang fungsi dan laporan baru, periksa Menggunakan dasbor Grup Selalu Tersedia.
Untuk memicu menggunakan opsi baru ini, klik Kumpulkan Data Latensi dari dasbor Always on Availability Group, yang akan membuat pekerjaan SQL Agent baru di replika Primer dan Sekunder untuk mengumpulkan data latensi, Seperti yang ditunjukkan di bawah ini:

Ketika eksekusi pekerjaan yang dibuat telah selesai pada semua replika Grup Ketersediaan, Anda akan dapat melihat statistik latensi dari laporan latensi dengan mengklik kanan nama Grup Ketersediaan dan memilih laporan Latensi Replika Utama atau Latensi Replika Sekunder, berdasarkan peran replika di Grup Ketersediaan.
Setelah memberikan informasi tentang replika Grup Ketersediaan, laporan latensi akan menampilkan tampilan grafis waktu komit log transaksi pada replika Utama dan waktu Pengerasan jarak jauh untuk replika sekunder, yang digabungkan sebagai nilai rata-rata. Selain itu, laporan memberikan nilai statistik untuk log transaksi yang dikirim, diterima, dikomit, dikompres, didekompresi, dan nilai numerik lainnya berdasarkan peran replika di Grup Ketersediaan.
Untuk informasi selengkapnya tentang laporan latensi, periksa Baru di SSMS - Laporan Latensi Grup yang Selalu Tersedia.
Laporan di bawah ini adalah contoh laporan latensi yang dihasilkan dari replika Sekunder, yang menunjukkan operasi pengangkutan log normal:

Juga, Latensi Blok Log laporan menunjukkan jumlah waktu, dalam md, log transaksi di replika Utama menunggu replika Sekunder melakukan transaksi itu. Setelah mengaktifkannya dari Availability Group Dashboard, Anda dapat menelusurinya dari SSMS yang mirip dengan laporan latensi sebelumnya. Mempertimbangkan bahwa, waktu latensi yang besar menunjukkan bahwa replika Utama menunggu lama hingga replika Sekunder melakukan transaksi terkirim, seperti yang ditunjukkan di bawah ini:




