Saat server sedang down, hal itu dapat menyebabkan gangguan pada tujuan bisnis Anda dan mengakibatkan hilangnya pendapatan. Misalnya, maskapai penerbangan mungkin tidak dapat memesan penerbangan untuk pelanggan jika instans dan database tidak tersedia. Sistem dapat gagal karena berbagai alasan, seperti kebakaran, kesalahan manusia, kegagalan komputer, kegagalan disk, dan kesalahan pemrograman.
Untuk menghindari gangguan dan memastikan bahwa ada kesinambungan dalam layanan bisnis, sangat penting untuk memiliki strategi ketersediaan tinggi (HA) dan pemulihan bencana (DR). HA dan DR sering dibahas bersama. HA berupaya mengurangi waktu henti server sebanyak mungkin, tetapi karena tidak ada sistem yang sempurna, DR berfokus pada proses penggunaan media cadangan untuk memulihkan data yang hilang jika sistem basis data tidak berfungsi.
AlwaysOn adalah istilah merek/pemasaran yang digunakan sejak SQL Server 2012 untuk menggambarkan fitur HADR Microsoft yang disempurnakan. Sebelum AlwaysOn, mesin database mendukung solusi kepemilikan bawaan lainnya, seperti pencerminan database, kluster failover, dan pengiriman log. Namun, masing-masing teknik tersebut memiliki manfaat dan keterbatasan. Seringkali, tergantung pada tujuannya, sebuah organisasi harus menggabungkan beberapa metode bersama untuk mencapai strategi HADR yang diinginkan.
Fitur AlwaysOn diperkenalkan sehingga Anda tidak perlu berurusan dengan waktu dan sumber daya tambahan untuk menerapkan dan memperkenalkan kompleksitas dalam penerapan untuk memperhitungkan redundansi server dan database, mengalami masalah dengan penskalaan, atau memiliki perangkat keras siaga yang tidak digunakan secara efisien. Fitur-fitur ini dengan mudah memadukan banyak praktik lama dan meningkatkan area di mana mereka gagal. Untuk benar-benar memahami nilai penawaran AlwaysOn, penting untuk meninjau kembali konsep dasar awal tentang bagaimana mesin database memastikan sistem HADR di masa lalu.
Pencerminan Basis Data
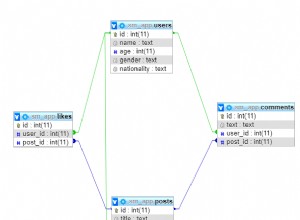
Redundansi database dapat dicapai melalui mirroring. Misalnya, Anda dapat memiliki aplikasi klien front-end yang menghasilkan pendapatan yang memungkinkan siswa memesan buku teks secara online. Seorang pelanggan memilih pembelian mereka, dan permintaan dibuat terhadap database PsychologyBooks di bagian belakang. Jika terjadi bencana yang membuat database PsychologyBooks tidak tersedia, siswa tidak akan dapat menyelesaikan pesanannya.
Untuk menghindari gangguan ini, Anda dapat memiliki instans utama yang digunakan dalam produksi yang berisi database PsychologyBooks dan memiliki salinan tambahan dari database PsychologyBooks tersebut di server cermin di standby. Aplikasi klien dapat terhubung kembali ke salinan yang dicerminkan alih-alih mengalami gangguan dan harus menunggu pemulihan selesai pada salinan utama. Salinan mengikuti perubahan yang dibuat pada aslinya dengan menerima log transaksi dan kemudian mengulangi perubahan yang direkam tersebut.
Sesi mirroring dapat beroperasi dalam mode yang berbeda tergantung pada kinerja atau justifikasi keamanan tinggi. Dengan mudah, failover otomatis didukung saat sesi mirroring dioperasikan dalam mode sinkron dengan keamanan tinggi dan konsensus kuorum dibuat dengan adanya server saksi opsional.
Terlepas dari manfaat mirroring, itu gagal karena hanya menyediakan redundansi basis data, bukan redundansi server. Itu berarti jika instance server utama turun, kedua instance akan turun, dan tidak masalah jika ada salinan data cadangan di tingkat basis data. Siaga tidak mendukung operasi pengguna, dan snapshot akan diperlukan untuk mendapatkan salinan data hanya-baca pada instans yang dicerminkan. Basis data dilindungi, tetapi objek tingkat server, seperti keanggotaan peran server, informasi login, dan pekerjaan agen, tidak.
Misalnya, jika ada tim pemasaran yang besar dan setiap anggota memiliki login mereka sendiri, mereka harus melalui proses pembuatan ulang login untuk setiap orang dari awal lagi. Ketika failover benar-benar terjadi, itu berdasarkan basis data independen dan bukan sebagai grup.
Pengelompokan Kegagalan
Pengelompokan failover menawarkan redundansi pada tingkat instans dan memberikan perlindungan dari kegagalan perangkat keras dan sistem operasi. Misalnya, katakanlah sebuah node di Queen Anne terbakar, menyebabkan kegagalan peralatan. Seluruh instance—yang mencakup objek tingkat instance, seperti login atau pekerjaan tertentu yang dibuat untuk melakukan tugas tertentu—akan dilindungi dan dapat dimulai ulang secara otomatis pada node lain yang termasuk dalam cluster. Aplikasi dan layanan klien akan terus tersedia untuk pelanggan.
Skenario di atas berfungsi karena penyimpanan dibagi antara server fisik yang berlebihan di grup Windows Server Failover Cluster (WSFC). Baik OS dan SQL Server bekerja bersama sehingga hanya satu node yang memiliki grup sumber daya WSFC pada satu waktu.
Sayangnya, dengan penyimpanan umum, solusi ini tidak menyediakan redundansi basis data yang disediakan oleh strategi pencerminan sebelumnya. Memiliki penyimpanan bersama menimbulkan risiko karena menghasilkan satu titik kegagalan. Misalnya, disk eksternal mungkin berisi satu-satunya salinan database PsychologyBooks yang penting dan, meskipun instance berhasil gagal ke node Ballard, masih akan ada gangguan pada tujuan bisnis jika satu-satunya komponen penyimpanan dikompromikan. Pengelompokan failover juga mengusulkan kendala dalam hal skalabilitas karena aplikasi klien tidak mampu menangani peningkatan jumlah pekerjaan yang meluas lebih jauh daripada klaster.
Pengiriman Log
Metode lain untuk mencapai redundansi database adalah melalui pengiriman log. Log transaksi dicadangkan di server utama dan dikirim ke satu atau beberapa server sekunder untuk dipulihkan. Tidak seperti mirroring, database sekunder dapat memenuhi syarat untuk aktivitas hanya-baca, dan frekuensi pengiriman log dapat dikonfigurasi untuk interval yang berbeda. Ada manfaat kinerja dalam skenario di mana database sekunder tidak perlu disinkronkan dengan database utama secara real time.
Misalnya, menjalankan laporan ringkasan statistik di penghujung malam untuk melihat buku psikologi apa yang dijual sepanjang hari tidak memerlukan basis data salinan untuk benar-benar sinkron dengan basis data utama. Aktivitas baca-intensif menempatkan kunci pada objek database dan dapat meningkatkan waktu tunggu. Oleh karena itu, menjalankan pelaporan di server sekunder akan mengurangi permintaan beban kerja di server penghasil pendapatan utama.
Kekurangannya adalah pengiriman log tidak mendukung failover otomatis. Oleh karena itu, jika server sumber gagal, database perlu dipulihkan secara manual. Seperti mirroring, pengiriman log tidak menyediakan redundansi server dan merupakan solusi tingkat basis data.
Memahami AlwaysOn
Teknologi lama masing-masing memiliki manfaat dan pengorbanan. Tetapi menerapkan solusi HADR yang disesuaikan dapat dengan cepat menjadi rumit dan memerlukan lebih banyak manajemen karena strategi yang berbeda ini dicampur dan dicocokkan secara sewenang-wenang untuk memenuhi kebutuhan bisnis. Oleh karena itu, fitur AlwaysOn diperkenalkan dan memberikan versi strategi sebelumnya yang telah ditingkatkan dan digabungkan.
SQL Server menawarkan dua fitur:AlwaysOn Availability Groups (AG) dan AlwaysOn Failover Cluster Instances (FCI). Keduanya membutuhkan Windows Server Failover Clustering (WSFC) untuk diimplementasikan.

AG adalah sekelompok database yang akan failover bersama-sama. Anda akan memerlukan beberapa node fisik yang berlebihan dengan instance SQL Server yang diinstal pada setiap node untuk meng-host replika ketersediaan. Setiap replika harus berada di node berbeda dari WSFC yang sama. Dalam skema di atas, replika utama di-host di Node 01, dan semua replika sekunder lainnya memenuhi syarat untuk failover ketika WSFC merasakan ada masalah.
Cara replika sekunder tetap sinkron dengan primer adalah dengan mengirimkan log transaksi dan mengulang perubahan. AG mendukung mode komit asinkron dan sinkron. Replika utama memenuhi syarat untuk membaca dan menulis, sedangkan replika sekunder memenuhi syarat untuk hanya baca. Pencadangan dapat dilakukan di lokasi sekunder.
Langsung saja, ada keuntungan dengan AlwaysOn AG. Ingat dari sebelumnya bahwa beberapa kelemahan dengan pencerminan basis data adalah bahwa basis data hanya dapat dicerminkan ke satu server sekunder dan ketika failover terjadi, setiap basis data dicerminkan secara independen. Dengan AG, database dibuat berlebihan di banyak tempat, seperti Node 02, Node 03, Node 04, dan Node 05 pada contoh di atas. Dukungan ketersediaan database memungkinkan hingga sembilan replika ketersediaan.
Selanjutnya, pengiriman log akan diperlukan untuk mencapai data hanya-baca di server sekunder. Tetapi dengan AG, data hanya-baca sudah diperhitungkan. Aktivitas membaca intensif seperti pelaporan dapat dilakukan pada salah satu replika sekunder. Perhatikan juga bahwa tidak ada batasan penyimpanan bersama.
Namun, AG dapat digabungkan dengan AlwaysOn FCI untuk memungkinkan redundansi server. Instans FCI dapat digunakan untuk menghosting replika ketersediaan sehingga objek tingkat server seperti login dan pekerjaan agen juga dapat dilindungi. Pendekatan ini akan membutuhkan penyimpanan bersama. Namun, ketidaknyamanan seperti harus melakukan konfigurasi ulang untuk aplikasi klien akan dihilangkan.