Tambahan: SQL Server 2012 menunjukkan beberapa peningkatan kinerja di area ini tetapi tampaknya tidak mengatasi masalah spesifik yang disebutkan di bawah ini. Ini tampaknya harus diperbaiki di versi utama berikutnya setelah SQL Server 2012!
Rencana Anda menunjukkan bahwa sisipan tunggal menggunakan prosedur berparameter (mungkin berparameter otomatis) sehingga waktu parse/kompilasi untuk ini harus minimal.
Saya pikir saya akan melihat ini sedikit lebih, jadi siapkan loop (skrip) dan coba sesuaikan jumlah VALUES klausa dan merekam waktu kompilasi.
Saya kemudian membagi waktu kompilasi dengan jumlah baris untuk mendapatkan waktu kompilasi rata-rata per klausa. Hasilnya ada di bawah
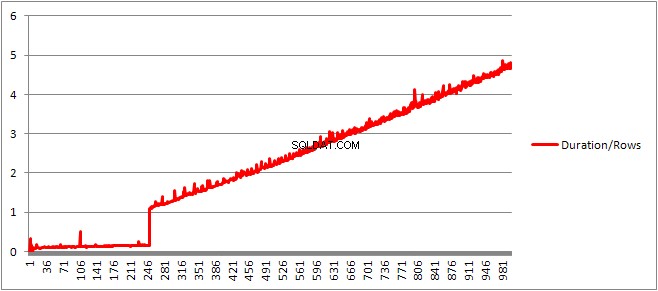
Hingga 250 VALUES klausa menyajikan waktu kompilasi / jumlah klausa memiliki tren sedikit meningkat tetapi tidak terlalu dramatis.
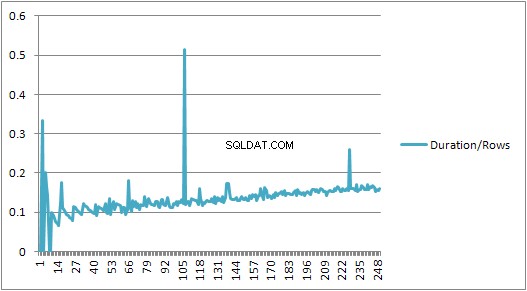
Tapi kemudian ada perubahan mendadak.
Bagian data tersebut ditunjukkan di bawah ini.
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
Ukuran paket yang di-cache yang telah tumbuh secara linier tiba-tiba turun tetapi CompileTime meningkat 7 kali lipat dan CompileMemory meningkat. Ini adalah titik potong antara rencana yang berparameter otomatis (dengan 1.000 parameter) ke yang tidak berparameter. Setelah itu tampaknya menjadi kurang efisien secara linier (dalam hal jumlah klausa nilai yang diproses dalam waktu tertentu).
Tidak yakin mengapa ini harus terjadi. Agaknya ketika menyusun rencana untuk nilai literal tertentu, ia harus melakukan beberapa aktivitas yang tidak berskala linier (seperti menyortir).
Tampaknya tidak memengaruhi ukuran paket kueri yang di-cache ketika saya mencoba kueri yang seluruhnya terdiri dari baris duplikat dan tidak memengaruhi urutan output tabel konstanta (dan saat Anda memasukkan ke dalam tumpukan waktu yang dihabiskan untuk menyortir toh akan sia-sia bahkan jika itu terjadi).
Terlebih lagi jika indeks berkerumun ditambahkan ke tabel, rencana tersebut masih menunjukkan langkah pengurutan yang eksplisit sehingga tampaknya tidak mengurutkan pada waktu kompilasi untuk menghindari pengurutan pada waktu berjalan.

Saya mencoba melihat ini di debugger tetapi simbol publik untuk versi SQL Server 2008 saya tampaknya tidak tersedia, jadi saya harus melihat UNION ALL yang setara konstruksi di SQL Server 2005.
Jejak tumpukan tipikal ada di bawah
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
Jadi, menghilangkan nama dalam pelacakan tumpukan tampaknya menghabiskan banyak waktu untuk membandingkan string.
Artikel KB ini menunjukkan bahwa DeriveNormalizedGroupProperties dikaitkan dengan apa yang dulu disebut tahap normalisasi pemrosesan kueri
Tahap ini sekarang disebut pengikatan atau aljabar dan dibutuhkan ekspresi pohon parse keluaran dari tahap penguraian sebelumnya dan keluaran pohon ekspresi aljabar (pohon pemroses kueri) untuk maju ke pengoptimalan (pengoptimalan rencana sepele dalam kasus ini) [ref].
Saya mencoba satu eksperimen lagi (Script) yang menjalankan kembali pengujian asli tetapi melihat tiga kasus yang berbeda.
- Nama Depan dan Nama Belakang String dengan panjang 10 karakter tanpa duplikat.
- Nama Depan dan Nama Belakang String sepanjang 50 karakter tanpa duplikat.
- Nama Depan dan Nama Belakang String dengan panjang 10 karakter dengan semua duplikatnya.
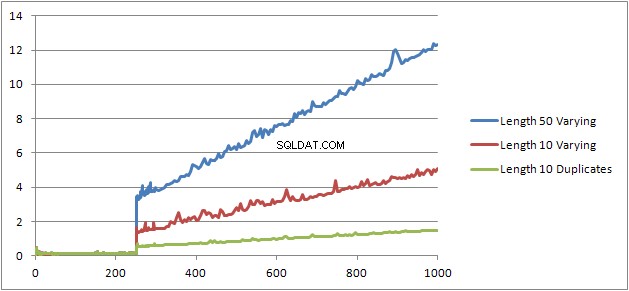
Dapat dilihat dengan jelas bahwa semakin panjang senar semakin buruk hal-hal yang didapat dan sebaliknya semakin banyak duplikat semakin baik. Seperti yang disebutkan sebelumnya, duplikat tidak memengaruhi ukuran paket yang di-cache, jadi saya menganggap bahwa harus ada proses identifikasi duplikat saat membangun pohon ekspresi aljabar itu sendiri.
Sunting
Satu tempat di mana informasi ini dimanfaatkan ditunjukkan oleh @Lieven di sini
SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
Karena pada waktu kompilasi dapat menentukan bahwa Name kolom tidak memiliki duplikat, kolom ini melompati urutan dengan 1/ (ID - ID) ekspresi saat run time (sort dalam rencana hanya memiliki satu ORDER BY kolom) dan tidak ada kesalahan bagi dengan nol yang dimunculkan. Jika duplikat ditambahkan ke tabel maka operator sortir menunjukkan dua urutan menurut kolom dan kesalahan yang diharapkan akan muncul.