Strategi pengindeksan tabel adalah salah satu kunci penyetelan kinerja dan pengoptimalan yang paling penting. Di SQL Server, indeks (indeks clustered dan non-clustered) dibuat menggunakan struktur B-tree, di mana setiap halaman bertindak sebagai node daftar tertaut ganda, yang memiliki informasi tentang halaman sebelumnya dan halaman berikutnya. Struktur B-tree ini, disebut Forward Scan, memudahkan membaca baris dari indeks dengan memindai atau mencari halamannya dari awal hingga akhir. Meskipun pemindaian ke depan adalah metode pemindaian indeks default dan sangat dikenal, SQL Server memberi kami kemampuan untuk memindai baris indeks dalam struktur pohon-B dari akhir hingga awal. Kemampuan ini disebut dengan Backward Scan. Dalam artikel ini, kita akan melihat bagaimana ini terjadi dan apa pro dan kontra dari metode pemindaian Mundur.
SQL Server memberi kita kemampuan untuk membaca data dari indeks tabel dengan memindai node struktur pohon B indeks dari awal hingga akhir menggunakan metode Pemindaian Teruskan, atau membaca node struktur pohon B dari akhir ke awal menggunakan Metode Pemindaian Mundur. Seperti namanya, pemindaian Mundur dilakukan saat membaca berlawanan dengan urutan kolom yang disertakan dalam indeks, yang dilakukan dengan opsi DESC dalam pernyataan penyortiran ORDER BY T-SQL, yang menentukan arah operasi pemindaian.
Dalam situasi tertentu, SQL Server Engine menemukan bahwa membaca data indeks dari akhir ke awal dengan metode pemindaian Mundur lebih cepat daripada membacanya dalam urutan normal dengan metode pemindaian Teruskan, yang mungkin memerlukan proses penyortiran yang mahal oleh SQL Mesin. Kasus tersebut mencakup penggunaan fungsi agregat MAX() dan situasi ketika pengurutan hasil kueri berlawanan dengan urutan indeks. Kelemahan utama metode pemindaian Mundur adalah SQL Server Query Optimizer akan selalu memilih untuk mengeksekusinya menggunakan eksekusi paket serial, tanpa dapat mengambil manfaat dari rencana eksekusi paralel.
Asumsikan kita memiliki tabel berikut yang akan berisi informasi tentang karyawan perusahaan. Tabel dapat dibuat menggunakan pernyataan CREATE TABLE T-SQL di bawah ini:
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
Setelah membuat tabel, kita akan mengisinya dengan 10K dummy record, menggunakan pernyataan INSERT di bawah ini:
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000 Jika kita mengeksekusi pernyataan SELECT di bawah ini untuk mengambil data dari tabel yang dibuat sebelumnya, baris akan diurutkan sesuai dengan nilai kolom ID dalam urutan menaik, yang sama dengan urutan indeks berkerumun:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
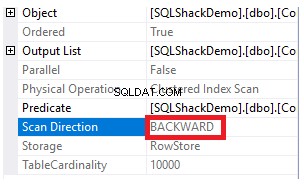
Kemudian memeriksa rencana eksekusi untuk kueri itu, pemindaian akan dilakukan pada indeks berkerumun untuk mendapatkan data yang diurutkan dari indeks seperti yang ditunjukkan pada rencana eksekusi di bawah ini:
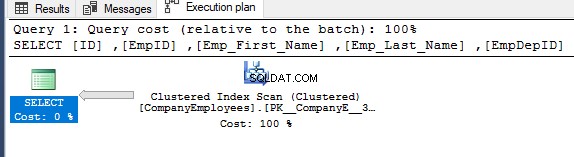
Untuk mendapatkan arah pemindaian yang dilakukan pada indeks berkerumun, klik kanan node pemindaian indeks untuk menelusuri properti node. Dari properti node Clustered Index Scan, properti Scan Direction akan menampilkan arah scan yang dilakukan pada indeks dalam query tersebut, yaitu Forward Scan seperti yang ditunjukkan pada snapshot di bawah ini:

Arah pemindaian indeks juga dapat diambil dari rencana eksekusi XML dari properti ScanDirection di bawah node IndexScan, seperti yang ditunjukkan di bawah ini:
Asumsikan bahwa kita perlu mengambil nilai ID maksimum dari tabel CompanyEmployees yang dibuat sebelumnya, menggunakan kueri T-SQL di bawah ini:
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
Kemudian tinjau rencana eksekusi yang dihasilkan dari mengeksekusi kueri tersebut. Anda akan melihat bahwa pemindaian akan dilakukan pada indeks berkerumun seperti yang ditunjukkan pada rencana eksekusi di bawah ini:
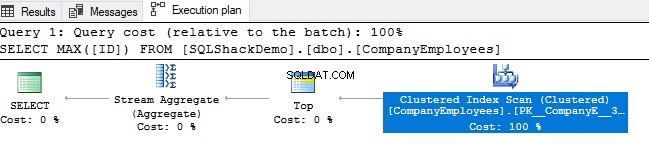
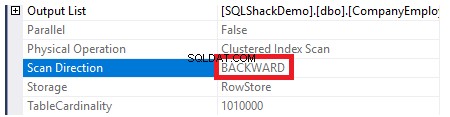
Untuk memeriksa arah pemindaian indeks, kami akan menelusuri properti node Clustered Index Scan. Hasilnya akan menunjukkan kepada kita bahwa, SQL Server Engine lebih suka memindai indeks berkerumun dari akhir ke awal, yang akan lebih cepat dalam hal ini, untuk mendapatkan nilai maksimum kolom ID, karena fakta bahwa indeks sudah diurutkan menurut kolom ID, seperti gambar di bawah ini:
Juga, jika kami mencoba untuk mengambil data tabel yang dibuat sebelumnya menggunakan pernyataan SELECT berikut, catatan akan diurutkan menurut nilai kolom ID, tetapi kali ini, berlawanan dengan urutan indeks berkerumun, dengan menentukan opsi pengurutan DESC di ORDER Klausa BY ditunjukkan di bawah ini:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
Jika Anda memeriksa rencana eksekusi yang dihasilkan setelah mengeksekusi kueri SELECT sebelumnya, Anda akan melihat bahwa pemindaian akan dilakukan pada indeks berkerumun untuk mendapatkan catatan tabel yang diminta, seperti yang ditunjukkan di bawah ini:
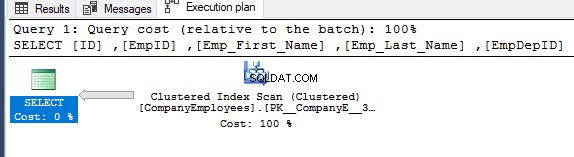
Properti node Pemindaian Indeks Clustered akan menunjukkan bahwa arah pemindaian yang lebih disukai oleh Mesin SQL Server adalah arah Pemindaian Mundur, yang lebih cepat dalam hal ini, karena pengurutan data yang berlawanan dengan pengurutan sebenarnya dari indeks berkerumun, dengan mempertimbangkan bahwa indeks sudah diurutkan dalam urutan menaik sesuai dengan kolom ID, seperti yang ditunjukkan di bawah ini:
Perbandingan Kinerja
Asumsikan bahwa kita memiliki pernyataan SELECT di bawah ini yang mengambil informasi tentang semua karyawan yang telah dipekerjakan mulai dari 2010, dua kali; pertama kali kumpulan hasil yang dikembalikan akan diurutkan dalam urutan menaik sesuai dengan nilai kolom ID, dan kedua kalinya kumpulan hasil yang dikembalikan akan diurutkan dalam urutan menurun sesuai dengan nilai kolom ID menggunakan pernyataan T-SQL di bawah ini:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
Memeriksa rencana eksekusi yang dihasilkan dengan mengeksekusi dua kueri SELECT, hasilnya akan menunjukkan bahwa pemindaian akan dilakukan pada indeks berkerumun di dua kueri untuk mengambil data, tetapi arah pemindaian pada kueri pertama akan Forward Scan karena penyortiran data ASC, dan Backward Scan pada query kedua karena menggunakan pengurutan data DESC, untuk menggantikan kebutuhan untuk menyusun ulang data, seperti yang ditunjukkan di bawah ini:
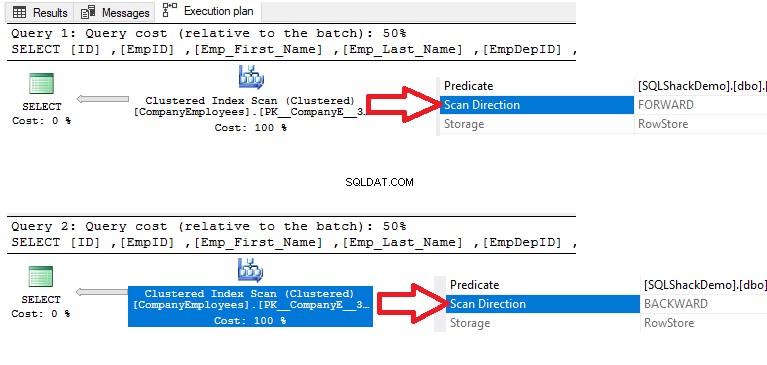
Selain itu, jika kita memeriksa statistik eksekusi IO dan TIME dari dua kueri, kita akan melihat bahwa kedua kueri melakukan operasi IO yang sama dan menggunakan nilai eksekusi dan waktu CPU yang mendekati.
Nilai-nilai ini menunjukkan kepada kita seberapa pintar SQL Server Engine ketika memilih arah pemindaian indeks yang paling cocok dan tercepat untuk mengambil data bagi pengguna, yaitu Pemindaian Maju dalam kasus pertama dan Pemindaian Mundur dalam kasus kedua, seperti yang jelas dari statistik di bawah ini :

Mari kita kunjungi lagi contoh MAX sebelumnya. Asumsikan bahwa kita perlu mengambil ID maksimum dari karyawan yang telah dipekerjakan pada tahun 2010 dan yang lebih baru. Untuk ini, kami akan menggunakan pernyataan SELECT berikut yang akan mengurutkan data yang dibaca menurut nilai kolom ID dengan pengurutan ASC di kueri pertama dan dengan pengurutan DESC di kueri kedua:
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Anda akan melihat dari rencana eksekusi yang dihasilkan dari eksekusi dua pernyataan SELECT, bahwa kedua kueri akan melakukan operasi pemindaian pada indeks berkerumun untuk mengambil nilai ID maksimum, tetapi dalam arah pemindaian yang berbeda; Pemindaian Maju di kueri pertama dan Pemindaian Mundur di kueri kedua, karena opsi pengurutan ASC dan DESC, seperti yang ditunjukkan di bawah ini:
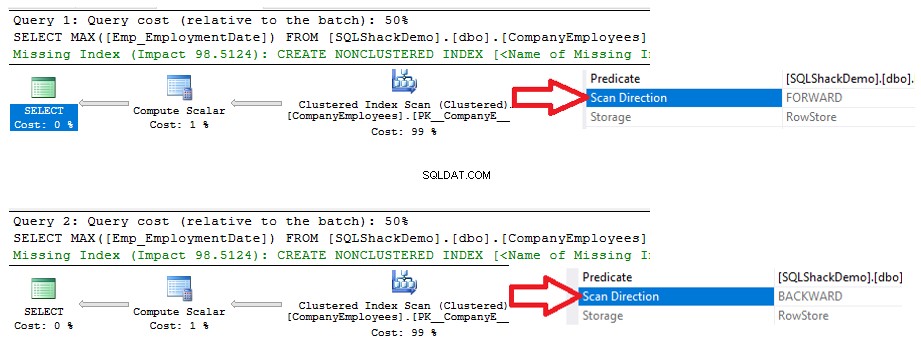
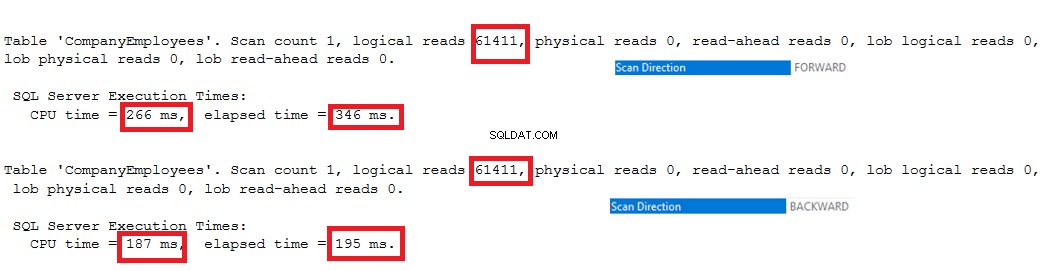
Statistik IO yang dihasilkan oleh dua kueri tidak akan menunjukkan perbedaan antara dua arah pemindaian. Tetapi statistik TIME menunjukkan perbedaan besar antara menghitung ID maksimum baris ketika baris-baris ini dipindai dari awal hingga akhir menggunakan metode Forward Scan dan pemindaian dari akhir ke awal menggunakan metode Backward Scan. Dari hasil dibawah terlihat jelas bahwa metode Backward Scan merupakan metode scanning yang optimal untuk mendapatkan nilai ID yang maksimal:
Optimalisasi Kinerja
Seperti yang saya sebutkan di awal artikel ini, pengindeksan kueri adalah kunci terpenting dalam penyetelan kinerja dan proses pengoptimalan. Pada query sebelumnya, jika kita mengatur untuk menambahkan indeks non-clustered pada kolom EmploymentDate dari tabel CompanyEmployees, menggunakan pernyataan CREATE INDEX T-SQL di bawah ini:
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
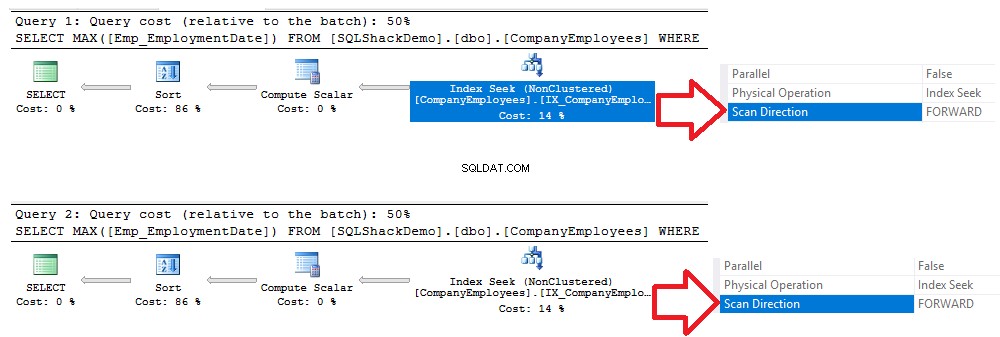
Memeriksa rencana eksekusi yang dihasilkan setelah eksekusi dua kueri, Anda akan melihat bahwa pencarian akan dilakukan pada indeks non-cluster yang baru dibuat, dan kedua kueri akan memindai indeks dari awal hingga akhir menggunakan metode Pindai Teruskan, tanpa kebutuhan untuk melakukan Pemindaian Mundur untuk mempercepat pengambilan data, meskipun kami menggunakan opsi pengurutan DESC dalam kueri kedua. Hal ini terjadi karena pencarian indeks secara langsung tanpa perlu melakukan pemindaian indeks penuh, seperti yang ditunjukkan pada perbandingan rencana eksekusi di bawah ini:
Hasil yang sama dapat diturunkan dari statistik IO dan TIME yang dihasilkan dari dua kueri sebelumnya, di mana kedua kueri tersebut akan mengkonsumsi jumlah waktu eksekusi, operasi CPU dan IO yang sama, dengan perbedaan yang sangat kecil, seperti yang ditunjukkan pada snapshot statistik di bawah ini. :

Alat Berguna:
dbForge Index Manager – add-in SSMS yang berguna untuk menganalisis status indeks SQL dan memperbaiki masalah dengan fragmentasi indeks.