Pengantar
Sebuah tabel adalah struktur logis. Saat Anda membuat tabel, Anda biasanya tidak akan peduli drive mana yang ada di lapisan penyimpanan. Namun, jika Anda adalah administrator basis data, pengetahuan ini mungkin menjadi penting jika Anda perlu memindahkan bagian basis data tertentu ke penyimpanan atau volume alternatif. Kemudian, Anda mungkin ingin tabel tertentu berada pada volume atau kumpulan disk tertentu.
Filegroups di SQL Server menawarkan lapisan abstraksi yang memungkinkan kita untuk mengontrol lokasi fisik dari struktur logis kita – tabel, indeks, dll.
Filegroup
Filegroup adalah struktur logis untuk mengelompokkan file data di SQL Server. Jika kita membuat grup file dan mengaitkannya dengan sekumpulan file data, objek logis apa pun yang dibuat pada grup file tersebut akan secara fisik ditempatkan pada kumpulan file fisik tersebut.
Tujuan utama pengelompokan file fisik tersebut adalah alokasi data dan penempatan data. Misalnya, kami ingin data transaksi kami disimpan di satu set disk cepat. Secara bersamaan, kita memerlukan data historis yang disimpan pada set disk lain yang lebih murah. Dalam skenario seperti itu, kami akan membuat Trans tabel pada filegroup TXN dan TranHist tabel pada grup file HIST yang berbeda. Lebih lanjut dalam artikel ini, kita akan melihat bagaimana ini berarti memiliki data pada disk yang berbeda.
Membuat Filegroups
Sintaks untuk membuat filegroup ditampilkan di Listing 1 . Catatan :Konteks basis data adalah master basis data. Dalam mengeluarkan pernyataan, kami mengubah database DB2 dengan menambahkan grup file baru ke dalamnya. Pada dasarnya, grup file ini hanyalah konstruksi logis pada saat ini. Mereka tidak berisi data apa pun.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Menambahkan File ke Filegroups
Langkah selanjutnya adalah menambahkan file ke masing-masing grup file. Kami dapat menambahkan lebih dari satu file, tetapi kami membuatnya sederhana untuk tujuan demonstrasi. Perhatikan bahwa setiap file berada pada drive yang berbeda seluruhnya, dan sintaks memungkinkan kita untuk menentukan grup file yang dimaksud.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Membuat Tabel ke Filegroups
Di sini kami memastikan tabel berada di disk yang diinginkan. Sintaks untuk membuat tabel memungkinkan kita untuk menentukan grup file yang kita inginkan.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Mengambil langkah mundur, kami mencatat bahwa kami sekarang telah mencapai hal berikut:
- Membuat dua grup file.
- Menentukan file data (dan disk) yang terkait dengan setiap grup file.
- Menentukan tabel yang terkait dengan setiap grup file.
Intinya, filegroup adalah lapisan abstraksi .
Memeriksa Grup File Tempat Tabel Kami Berada
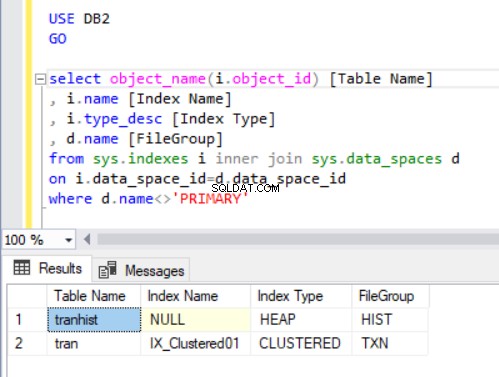
Untuk memeriksa filegroup apa yang dimiliki setiap tabel, kami akan mengeksekusi kode di Listing 4. Kami menggunakan dua tampilan katalog sistem utama:sys.indexes dan sys.data_spaces . sys.data_spaces tampilan katalog berisi informasi tentang grup file dan partisi, dan struktur logika utama tempat tabel dan indeks disimpan.
Catatan:Kami tidak menggunakan sys.tables . SQL Server mengaitkan indeks dalam tabel dengan ruang data, bukan tabel, seperti yang mungkin kita pikirkan secara intuitif.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
Keluaran kueri di Listing 4 menampilkan dua tabel yang baru saja kita buat. Perhatikan bahwa transhist tabel tidak memiliki indeks. Namun, itu muncul di kumpulan hasil, yang diidentifikasi sebagai heap .
Sebuah tumpukan adalah tabel yang tidak memiliki indeks berkerumun yang menentukan urutan data yang tersimpan secara fisik dalam sebuah tabel. Hanya ada satu indeks berkerumun dalam sebuah tabel.
Mengisi Tabel Trans
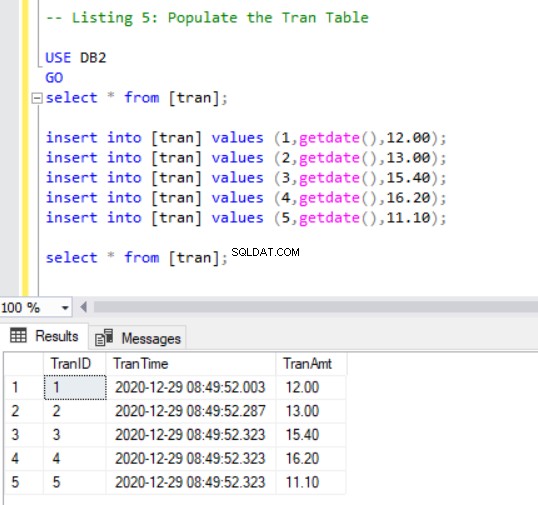
Sekarang, kita harus menambahkan beberapa record ke trans tabel menggunakan kode berikut:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Memindahkan Tabel ke Filegroup Lain
Untuk memindahkan trans tabel ke filegroup lain, kita hanya perlu membangun kembali indeks berkerumun dan tentukan filegroup baru saat melakukan pembangunan kembali ini. Daftar 5 menunjukkan pendekatan ini.
Kami melakukan dua langkah:pertama, jatuhkan indeks, lalu buat ulang. Di antaranya, kami memeriksa untuk mengonfirmasi bahwa data dan lokasi dari dua tabel yang kami buat sebelumnya tetap utuh.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
Dalam menjatuhkan indeks berkerumun dari trans tabel, kami telah mengonversinya menjadi heap :
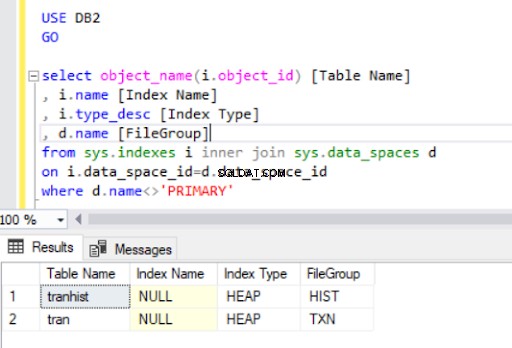
Saat kami membuat ulang indeks berkerumun, indeks tersebut juga akan ditunjukkan dalam output Listing 4.
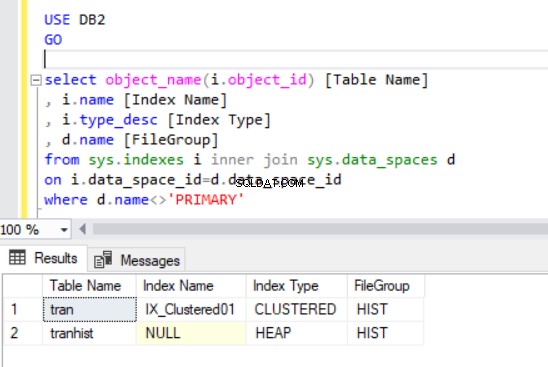
Sekarang kita memiliki trans tabel pada filegroup HIST.
Kesimpulan
Artikel ini menunjukkan hubungan antara tabel, indeks, file, dan grup file dalam hal penyimpanan data SQL Server kami. Kami juga telah menjelaskan memindahkan tabel dari satu grup file ke grup file lainnya dengan membuat ulang indeks berkerumun.
Keterampilan ini akan membantu saat Anda perlu memigrasikan data ke penyimpanan baru (disk yang lebih cepat atau lebih lambat untuk pengarsipan). Dalam skenario yang lebih maju, Anda dapat menggunakan grup file untuk mengelola siklus hidup data dengan mengimplementasikan partisi tabel.
Referensi
- File Database dan Filegroups
- Mematikan Partisi Tabel – Sebuah Panduan