Pengantar Indeks SQL Server
Microsoft SQL Server dianggap sebagai salah satu sistem manajemen basis data relasional (RDBMS ), di mana data secara logis diatur ke dalam baris dan kolom yang disimpan dalam wadah data yang disebut tabel. Secara fisik, tabel disimpan sebagai 8 KB halaman yang dapat diatur ke dalam tabel Heap atau B-Tree Clustered. Di Heap tabel, tidak ada urutan penyortiran yang mengontrol urutan data di dalam halaman data dan urutan halaman di dalam tabel itu, karena tidak ada indeks Clustered yang ditentukan pada tabel itu untuk menegakkan mekanisme penyortiran. Jika indeks Clustered ditentukan pada satu kolom dari grup kolom tabel, data akan diurutkan di dalam halaman data berdasarkan nilai kolom kunci indeks Clustered, dan halaman akan ditautkan bersama berdasarkan nilai kunci indeks ini. Tabel yang diurutkan ini disebut Tabel Berkelompok .
Di SQL Server, indeks dianggap sebagai kunci penting dan efektif dalam proses penyetelan kinerja. Tujuan pembuatan indeks adalah untuk mempercepat akses ke tabel dasar dan mengambil data yang diminta tanpa harus memindai semua baris tabel untuk mengembalikan data yang diminta. Anda dapat menganggap indeks basis data sebagai indeks buku yang membantu Anda menemukan kata-kata dalam buku dengan cepat, tanpa harus membaca seluruh buku untuk menemukan kata itu. Misalnya, Anda perlu mengambil informasi tentang pelanggan tertentu menggunakan ID pelanggan. Jika tidak ada indeks yang ditentukan untuk kolom ID Pelanggan dalam tabel ini, Mesin SQL Server memeriksa semua baris tabel, satu per satu, untuk mengambil pelanggan dengan ID yang diberikan. Jika indeks ditentukan untuk kolom ID Pelanggan dalam tabel ini, SQL Server Engine akan mencari nilai ID Pelanggan yang diminta dalam indeks yang diurutkan, bukan di tabel dasar, untuk mengambil informasi tentang pelanggan, mengurangi jumlah pemindaian baris untuk mengambil data.
Di SQL Server, indeks disusun secara logis sebagai halaman 8K, atau node indeks, dalam bentuk B-tree. Struktur B-Tree berisi tiga level:Tingkat Root yang menyertakan satu halaman indeks di bagian atas pohon-B, Leaf Level yang terletak di bagian bawah pohon-B dan berisi laman data, dan Tingkat Menengah yang mencakup semua simpul yang terletak di antara tingkat akar dan daun, dengan nilai kunci indeks dan penunjuk ke halaman berikut. Bentuk B-tree ini menyediakan cara cepat untuk menavigasi halaman data dari kiri ke kanan dan dari atas ke bawah, berdasarkan kunci indeks.
Di SQL Server, ada dua jenis indeks utama, indeks Berkelompok, di mana data aktual disimpan di halaman tingkat daun indeks, dengan kemampuan untuk membuat hanya satu indeks berkerumun untuk setiap tabel, karena data di dalam halaman data dan urutan halaman akan diurutkan berdasarkan indeks berkerumun kunci. Jika Anda menentukan batasan kunci utama di tabel Anda, indeks berkerumun akan dibuat secara otomatis jika tidak ada indeks berkerumun yang sebelumnya ditentukan untuk tabel itu. Jenis indeks kedua adalah Indeks yang tidak berkerumun yang menyertakan salinan kolom kunci indeks yang diurutkan dan penunjuk ke kolom lainnya di tabel dasar atau indeks berkerumun, dengan kemampuan untuk membuat hingga 999 indeks non-cluster untuk setiap tabel.
SQL Server memberi kami jenis indeks khusus lainnya, seperti indeks Unik yang dibuat secara otomatis saat batasan unik ditentukan untuk menerapkan keunikan nilai kolom tertentu, Indeks komposit di mana lebih dari satu kolom kunci akan berpartisipasi dalam kunci indeks, Indeks penutup di mana semua kolom yang diminta oleh kueri tertentu akan berpartisipasi dalam kunci indeks, Indeks yang difilter yang merupakan indeks non-cluster yang dioptimalkan dengan predikat filter untuk mengindeks hanya sebagian kecil dari baris tabel, indeks Spasial yang dibuat pada kolom yang menyimpan data spasial, indeks XML yang dibuat pada objek besar biner biner (BLOB) XML dalam kolom tipe data XML, Indeks penyimpanan kolom di mana data diatur dalam format data kolom, Indeks teks lengkap yang dibuat oleh Mesin Teks Lengkap SQL Server, dan indeks hash yang digunakan dalam tabel Memory-Optimized.
Seperti yang biasa saya sebut indeks SQL Server, ini adalah pedang bermata dua , di mana SQL Server Query Optimizer dapat memanfaatkan indeks yang dirancang dengan baik untuk meningkatkan kinerja aplikasi Anda dengan mempercepat proses pengambilan data. Sebaliknya, indeks yang dirancang dengan cara yang buruk tidak akan dipilih oleh SQL Server Query Optimizer dan akan menurunkan kinerja aplikasi Anda dengan memperlambat operasi modifikasi data dan menghabiskan penyimpanan Anda tanpa memanfaatkannya dalam data. proses pengambilan. Oleh karena itu, lebih baik untuk terlebih dahulu mengikuti praktik dan panduan terbaik pembuatan indeks, memeriksa efeknya jika membuat lingkungan pengembangan, dan menemukan kompromi antara kecepatan operasi pengambilan data dan biaya tambahan untuk menambahkan indeks itu pada operasi modifikasi data. dan persyaratan ruang dari indeks itu, sebelum menerapkannya ke lingkungan produksi.
Sebelum membuat indeks, Anda perlu mempelajari berbagai aspek yang memengaruhi pembuatan dan penggunaan indeks. Ini termasuk jenis beban kerja database, Pemrosesan Transaksi Online (OLTP) atau Pemrosesan Analitik Online (OLAP), ukuran tabel , karakteristik kolom tabel , urutan penyortiran kolom dalam kueri, jenis indeks yang sesuai dengan kueri dan properti penyimpanan seperti FILLFACTOR dan PAD_INDEX opsi yang mengontrol persentase ruang pada setiap tingkat daun dan halaman tingkat menengah untuk diisi dengan data.
Fragmentasi Indeks SQL Server
Pekerjaan Anda sebagai DBA tidak terbatas pada pembuatan indeks yang tepat. Setelah indeks dibuat, Anda harus memantau penggunaan indeks dan statistik, misalnya, Anda perlu mengetahui apakah indeks ini digunakan dengan buruk atau tidak digunakan sama sekali. Dengan demikian, Anda dapat memberikan solusi yang tepat untuk mempertahankan indeks ini atau menggantinya dengan yang lebih efisien. Dengan cara ini, Anda akan mempertahankan kinerja tertinggi yang dapat diterapkan untuk sistem Anda. Anda mungkin bertanya pada diri sendiri:Mengapa SQL Server Query Optimizer tidak lagi menggunakan indeks saya, meskipun sebelumnya pernah melakukannya?
Jawabannya terutama terkait dengan data berkelanjutan dan perubahan skema yang dilakukan pada tabel dasar yang harus tercermin dalam indeks. Seiring waktu, dan dengan semua perubahan ini, halaman indeks menjadi tidak tersortir, menyebabkan indeks menjadi terfragmentasi. Alasan lain untuk fragmentasi adalah upaya untuk memasukkan nilai baru atau memperbarui nilai saat ini, dan nilai baru tidak sesuai dengan ruang kosong yang tersedia saat ini. Dalam hal ini, halaman akan dipecah menjadi dua halaman, di mana halaman baru akan dibuat secara fisik setelah halaman terakhir. Dan Anda dapat membayangkan membaca dari indeks yang terfragmentasi dan jumlah halaman yang harus dipindai, dan, tentu saja, jumlah operasi I/O yang dilakukan untuk mengambil beberapa catatan karena jarak antara halaman-halaman ini. Dan karena biaya tambahan untuk menggunakan indeks yang terfragmentasi ini, SQL Server Query Optimizer akan mengabaikan indeks ini.
Cara Berbeda untuk Mendapatkan Fragmentasi Indeks
SQL Server memberi kita berbagai cara untuk mendapatkan persentase fragmentasi indeks. Cara pertama adalah memeriksa persentase fragmentasi indeks di Indeks Properti jendela, di bawah Fragmentasi tab, seperti yang ditunjukkan di bawah ini:
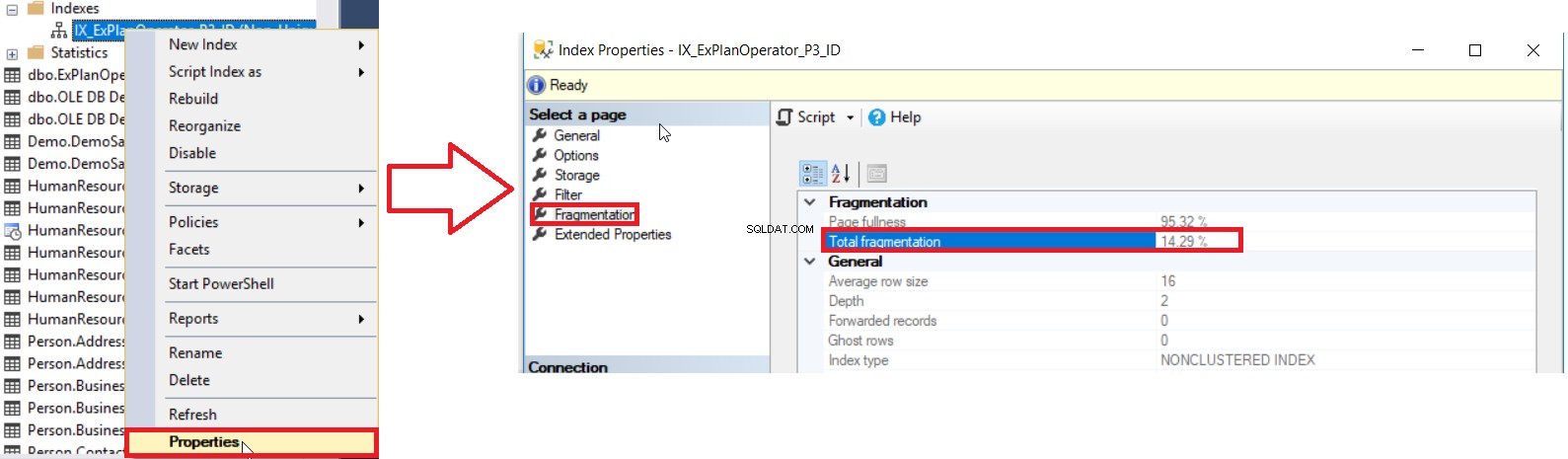
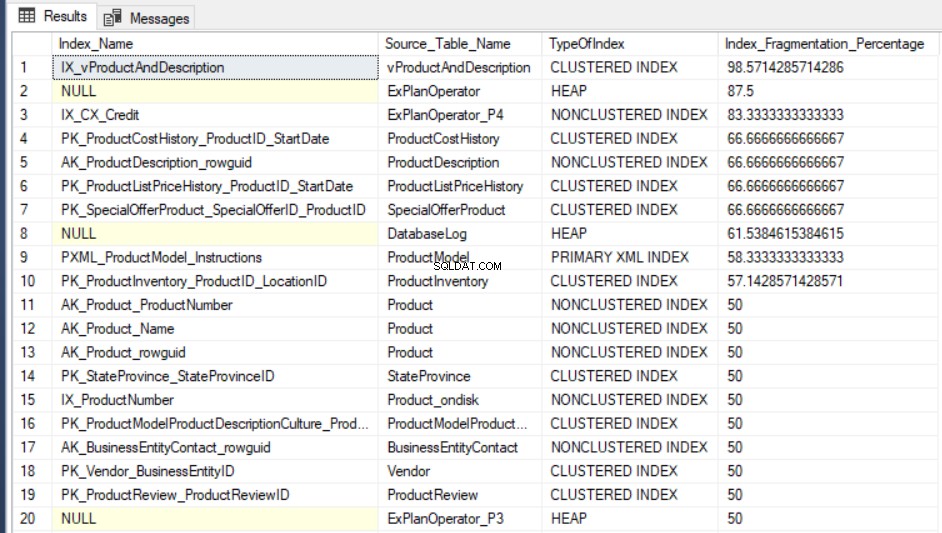
Tetapi untuk memeriksa tingkat fragmentasi beberapa indeks, Anda harus terlebih dahulu melakukan pemeriksaan metode UI untuk semua indeks, satu per satu, yang merupakan operasi yang membuang waktu. Metode kedua yang tersedia untuk memeriksa tingkat fragmentasi semua indeks basis data adalah dengan menanyakan sys.dm_db_index_physical_stats DMF dan menggabungkannya dengan DMV sys.indexes untuk mengambil semua informasi tentang indeks ini, dengan mempertimbangkan bahwa statistik ini akan di-refresh ketika Layanan SQL Server dimulai ulang, menggunakan kueri yang mirip dengan berikut ini:
Hasil keluaran dari query AdventureWorks2016CTP3 database pengujian akan mirip dengan berikut ini:
Metode ketiga untuk mendapatkan persentase fragmentasi adalah dengan menggunakan laporan standar bawaan SQL Server yang disebut Statistik Fisik Indeks. Laporan ini mengembalikan informasi yang berguna tentang partisi indeks, persentase fragmentasi, jumlah halaman di setiap partisi indeks, dan rekomendasi tentang cara memperbaiki masalah fragmentasi indeks dengan membangun kembali atau mengatur ulang indeks. Untuk melihat laporan, klik kanan database Anda, pilih opsi Laporan, Laporan Standar dan pilih Statistik Fisik Indeks seperti di bawah ini:
Dalam kasus kami, laporan yang dihasilkan akan terlihat seperti ini:
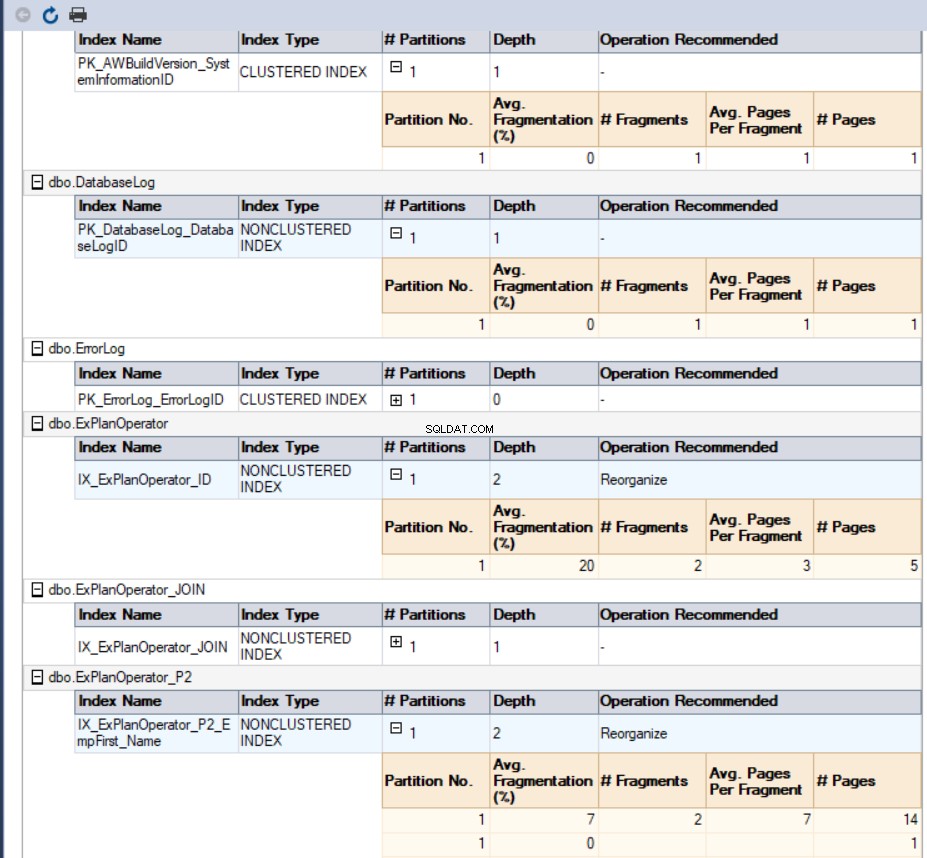
Cara terakhir dan termudah untuk mengambil persentase fragmentasi dari semua indeks database adalah alat Manajer Indeks dbForge. Pengelola Indeks dbForge alat adalah add-in yang dapat ditambahkan ke SQL Server Management Studio Anda untuk menganalisis indeks database SQL Server, memberikan Anda laporan yang sangat berguna dengan status indeks database yang dipilih dan saran pemeliharaan untuk memperbaiki masalah fragmentasi indeks ini.
Setelah menginstal add-in dbForge Index Manager ke SSMS Anda, Anda dapat menjalankannya dengan mengklik kanan database yang akan dipindai, pilih Index Manager , lalu Kelola Fragmentasi Indeks seperti yang ditunjukkan di bawah ini:
Alat Pengelola Indeks dbForge memungkinkan Anda mendapatkan gambaran keseluruhan tentang fragmentasi indeks basis data yang dipilih, dengan rekomendasi tindakan yang tepat untuk memperbaiki masalah ini, seperti yang ditunjukkan di bawah ini:

Alat Pengelola Indeks dbForge memungkinkan Anda juga untuk beralih di antara basis data, memberi Anda laporan baru setelah memindai basis data ini seperti yang ditunjukkan di bawah ini:
Laporan fragmentasi indeks yang dihasilkan oleh alat Pengelola Indeks dbForge dapat diekspor ke file CSV untuk menganalisis status fragmentasi indeks, seperti yang ditunjukkan di bawah ini:
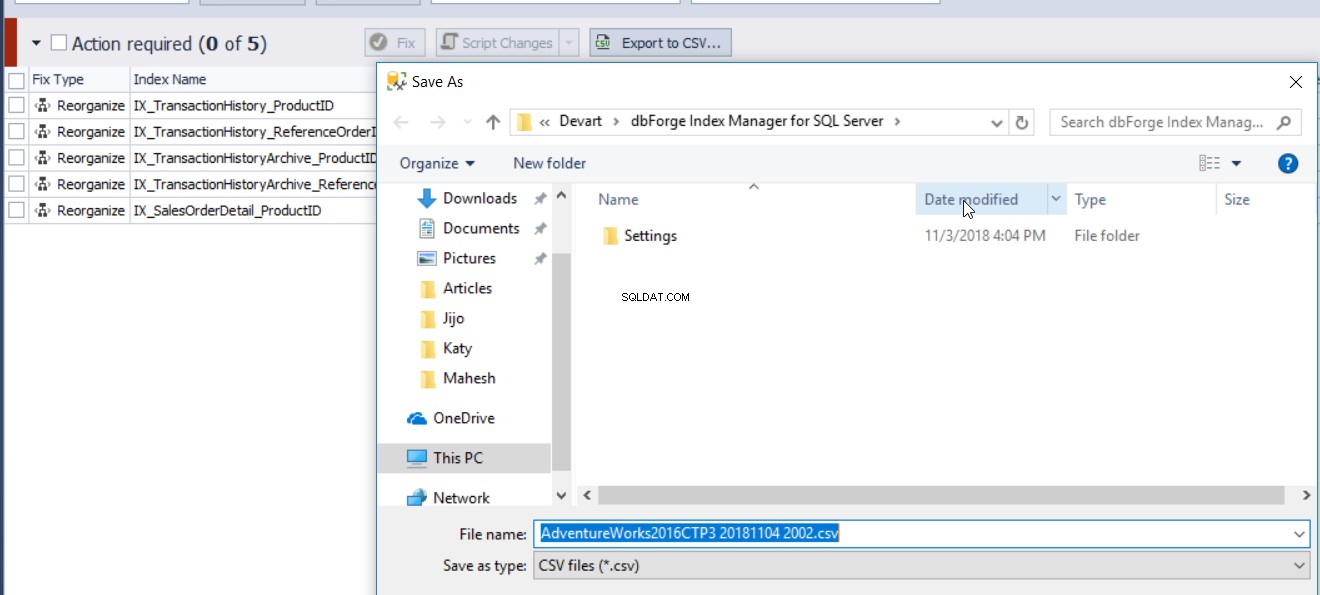
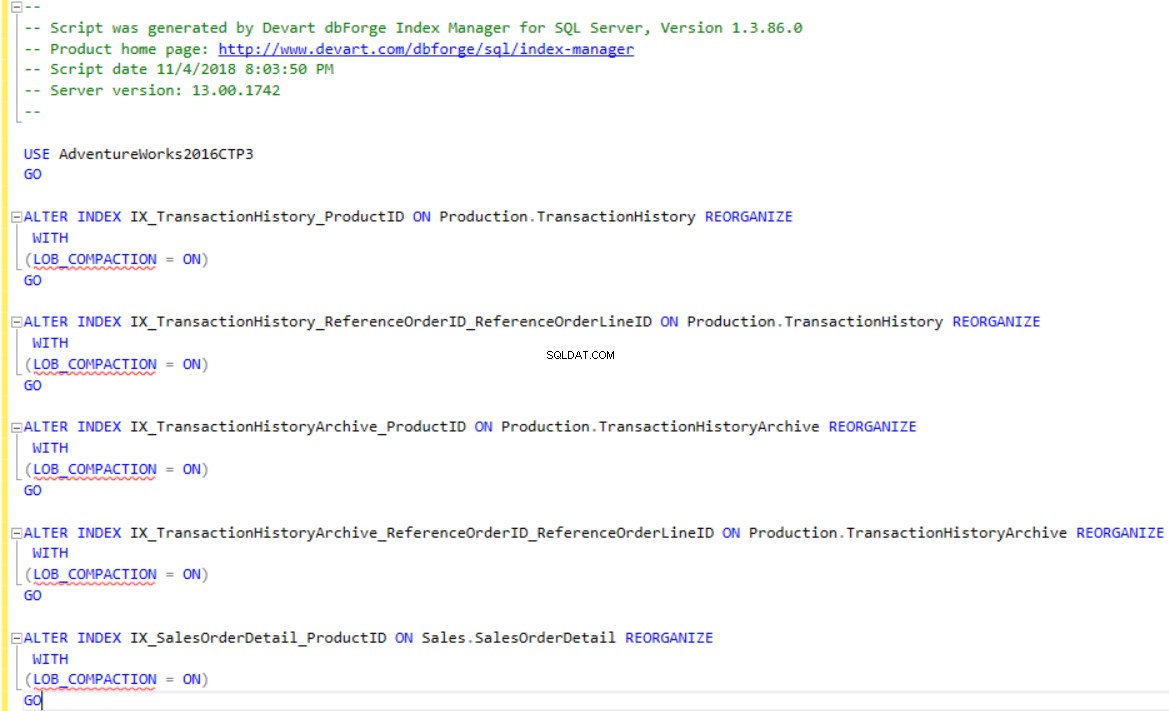
dbForge Index Manager memungkinkan Anda membuat skrip T-SQL untuk membangun kembali atau mengatur ulang indeks sesuai dengan rekomendasi alat. Gunakan Perubahan Skrip opsi untuk menampilkan atau menyimpan skrip untuk indeks yang terfragmentasi, seperti yang ditunjukkan di bawah ini:
Alat Pengelola Indeks dbForge memberi Anda kemampuan untuk memperbaiki masalah fragmentasi indeks secara langsung dengan mengeklik Perbaiki tombol yang akan melakukan tindakan yang disarankan secara langsung pada indeks yang dipilih, menunjukkan status perbaikan pada Hasil kolom seperti gambar di bawah ini:

Jika Anda mengeklik tombol Analisis ulang tombol, itu akan memindai fragmentasi indeks pada database lagi setelah melakukan operasi perbaikan dengan sukses. Apa yang tercantum di sini dalam artikel ini hanyalah pengantar tentang bagaimana alat Pengelola Indeks dbForge akan membantu kami dalam mengidentifikasi dan memperbaiki masalah fragmentasi indeks. Rekomendasi saya untuk Anda adalah mengunduhnya dan memeriksa apa yang dapat ditawarkan alat ini kepada Anda.
Tautan yang berguna:
- Dasar-dasar indeks
- Jenis indeks
- Indeks berkerumun dan tidak berkerumun dijelaskan
- Struktur indeks berkerumun
Alat yang berguna:
dbForge Index Manager – add-in SSMS yang berguna untuk menganalisis status indeks SQL dan memperbaiki masalah dengan fragmentasi indeks.