Pengantar
Tutorial ini mencakup informasi tentang SQL (DDL, DML) yang telah saya kumpulkan selama kehidupan profesional saya. Ini adalah minimum yang perlu Anda ketahui saat bekerja dengan database. Jika ada kebutuhan untuk menggunakan konstruksi SQL yang kompleks, maka biasanya saya menjelajahi perpustakaan MSDN, yang dapat dengan mudah ditemukan di internet. Menurut saya, sangat sulit untuk menyimpan semuanya di kepala Anda dan, omong-omong, tidak perlu untuk ini. Saya menyarankan Anda untuk mengetahui semua konstruksi utama yang digunakan di sebagian besar database relasional seperti Oracle, MySQL, dan Firebird. Namun, mereka mungkin berbeda dalam tipe data. Misalnya, untuk membuat objek (tabel, batasan, indeks, dll.), Anda cukup menggunakan lingkungan pengembangan terintegrasi (IDE) untuk bekerja dengan database dan tidak perlu mempelajari alat visual untuk tipe database tertentu (MS SQL, Oracle , MySQL, Firebird, dll.). Ini nyaman karena Anda dapat melihat keseluruhan teks, dan Anda tidak perlu melihat banyak tab untuk membuat, misalnya, indeks atau batasan. Jika Anda terus-menerus bekerja dengan database, membuat, memodifikasi, dan terutama membangun kembali objek menggunakan skrip jauh lebih cepat daripada mode visual. Selain itu, menurut saya, dalam mode skrip (dengan presisi yang tepat), lebih mudah untuk menentukan dan mengontrol aturan untuk penamaan objek. Selain itu, akan lebih mudah menggunakan skrip saat Anda perlu mentransfer perubahan basis data dari basis data uji ke basis data produksi.
SQL dibagi menjadi beberapa bagian. Dalam artikel saya, saya akan mengulas yang paling penting:
DDL – Bahasa Definisi Data
DML – Bahasa Manipulasi Data, yang mencakup konstruksi berikut:
- PILIH – pemilihan data
- INSERT – penyisipan data baru
- PERBARUI – pembaruan data
- HAPUS – penghapusan data
- GABUNG – penggabungan data
Saya akan menjelaskan semua konstruksi dalam studi kasus. Selain itu, menurut saya bahasa pemrograman, khususnya SQL, harus dipelajari dalam praktik untuk pemahaman yang lebih baik.
Ini adalah tutorial langkah demi langkah, di mana Anda perlu melakukan contoh saat membacanya. Namun, jika Anda perlu mengetahui perintah secara detail, maka jelajahi Internet, misalnya, MSDN.
Saat membuat tutorial ini, saya telah menggunakan database MS SQL Server, versi 2014, dan MS SQL Server Management Studio (SSMS) untuk mengeksekusi skrip.
Secara singkat tentang MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) adalah utilitas Microsoft SQL Server untuk mengonfigurasi, mengelola, dan mengelola komponen basis data. Ini termasuk editor skrip dan program grafis yang bekerja dengan objek dan pengaturan server. Alat utama SQL Server Management Studio adalah Object Explorer, yang memungkinkan pengguna untuk melihat, mengambil, dan mengelola objek server. Teks ini sebagian diambil dari Wikipedia.
Untuk membuat editor skrip baru, gunakan tombol Kueri Baru:
Untuk beralih dari database saat ini, Anda dapat menggunakan menu tarik-turun:
Untuk menjalankan perintah atau kumpulan perintah tertentu, sorot dan tekan tombol Execute atau F5. Jika hanya ada satu perintah di editor atau Anda perlu menjalankan semua perintah, maka jangan sorot apa pun.
Setelah Anda menjalankan skrip yang membuat objek (tabel, kolom, indeks), pilih objek yang sesuai (misalnya, Tabel atau Kolom), lalu klik Refresh pada menu pintasan untuk melihat perubahannya.
Sebenarnya, hanya ini yang perlu Anda ketahui untuk menjalankan contoh yang diberikan di sini.
Teori
Database relasional adalah sekumpulan tabel yang dihubungkan bersama. Secara umum, database adalah file yang menyimpan data terstruktur.
Sistem Manajemen Basis Data (DBMS) adalah seperangkat alat untuk bekerja dengan tipe basis data tertentu (MS SQL, Oracle, MySQL, Firebird, dll.).
Catatan: Seperti dalam kehidupan kita sehari-hari, kita mengatakan “Oracle DB” atau hanya “Oracle” yang sebenarnya berarti “Oracle DBMS”, maka dalam tutorial ini, saya akan menggunakan istilah “database”.
Tabel adalah kumpulan kolom. Sangat sering, Anda dapat mendengar definisi istilah berikut:bidang, baris, dan catatan, yang artinya sama.
Sebuah tabel adalah objek utama dari database relasional. Semua data disimpan baris demi baris dalam kolom tabel.
Untuk setiap tabel serta kolomnya, Anda perlu menentukan nama, yang dengannya Anda dapat menemukan item yang diperlukan.
Nama objek, tabel, kolom, dan indeks boleh memiliki panjang minimal – 128 simbol.
Catatan: Dalam database Oracle, nama objek mungkin memiliki panjang minimum – 30 simbol. Jadi, dalam database tertentu, perlu dibuat aturan khusus untuk nama objek.
SQL adalah bahasa yang memungkinkan mengeksekusi query dalam database melalui DBMS. Dalam DBMS tertentu, bahasa SQL mungkin memiliki dialeknya sendiri.
DDL dan DML – subbahasa SQL:
- Bahasa DDL berfungsi untuk membuat dan memodifikasi struktur database (penghapusan tabel dan tautan);
- Bahasa DML memungkinkan manipulasi data tabel, barisnya. Ini juga berfungsi untuk memilih data dari tabel, menambahkan data baru, serta memperbarui dan menghapus data saat ini.
Dimungkinkan untuk menggunakan dua jenis komentar dalam SQL (baris tunggal dan dibatasi):
-- komentar satu baris
dan
/* komentar dibatasi */
Itu saja teorinya.
DDL – Bahasa Definisi Data
Mari kita pertimbangkan tabel sampel dengan data tentang karyawan yang diwakili dengan cara yang akrab bagi orang yang bukan programmer.
| ID Karyawan | Nama Lengkap | Tanggal lahir | Posisi | Departemen | |
| 1000 | John | 19.02.1955 | contoh@sqldat.com | CEO | Administrasi |
| 1001 | Daniel | 03.12.1983 | contoh@sqldat.com | pemrogram | TI |
| 1002 | Mike | 07.06.1976 | contoh@sqldat.com | Akuntan | Dept akun |
| 1003 | Yordania | 17.04.1982 | contoh@sqldat.com | Programmer senior | TI |
Dalam hal ini, kolom memiliki judul berikut:ID Karyawan, Nama Lengkap, Tanggal Lahir, E-mail, Jabatan, dan Departemen.
Kita dapat mendeskripsikan setiap kolom tabel ini berdasarkan tipe datanya:
- ID Karyawan – bilangan bulat
- Nama Lengkap – string
- Tanggal lahir – tanggal
- Email – string
- Posisi – string
- Departemen – string
Tipe kolom adalah properti yang menentukan tipe data apa yang dapat disimpan oleh setiap kolom.
Untuk memulainya, Anda perlu mengingat tipe data utama yang digunakan dalam MS SQL:
| Definisi | Penunjukan di MS SQL | Deskripsi |
| String dengan panjang variabel | varchar(N) dan nvarchar(N) | Menggunakan nomor N, kita dapat menentukan panjang string maksimum yang mungkin untuk kolom tertentu. Misalnya, jika kita ingin mengatakan bahwa nilai kolom Nama Lengkap dapat berisi 30 simbol (paling banyak), maka perlu untuk menentukan jenis nvarchar(30).
Perbedaan antara varchar dari nvarchar adalah varchar memungkinkan penyimpanan string dalam format ASCII, sedangkan nvarchar menyimpan string dalam format Unicode, di mana setiap simbol membutuhkan 2 byte. |
| String dengan panjang tetap | char(N) dan nchar(N) | Jenis ini berbeda dari string panjang variabel dalam hal berikut:jika panjang string kurang dari simbol N, maka spasi selalu ditambahkan ke panjang N di sebelah kanan. Jadi, dalam database, dibutuhkan persis N simbol, di mana satu simbol membutuhkan 1 byte untuk char dan 2 byte untuk nchar. Dalam praktik saya, tipe ini tidak banyak digunakan. Namun, jika ada yang menggunakannya, biasanya tipe ini memiliki format char(1), yaitu ketika sebuah field didefinisikan oleh 1 simbol. |
| Bilangan bulat | int | Jenis ini memungkinkan kita untuk menggunakan hanya bilangan bulat (baik positif maupun negatif) dalam sebuah kolom. Catatan:rentang angka untuk tipe ini adalah sebagai berikut:dari 2 147 483 648 hingga 2 147 483 647. Biasanya, ini adalah tipe utama yang digunakan untuk ашту pengidentifikasi. |
| Angka titik-mengambang | mengambang | Angka dengan titik desimal. |
| Tanggal | tanggal | Ini digunakan untuk menyimpan hanya tanggal (tanggal, bulan, dan tahun) dalam kolom. Misalnya, 15/02/2014. Jenis ini dapat digunakan untuk kolom berikut:tanggal penerimaan, tanggal lahir, dll., ketika Anda hanya perlu menentukan tanggal atau ketika waktu tidak penting bagi kami dan kami dapat membatalkannya. |
| Waktu | waktu | Anda dapat menggunakan jenis ini jika perlu untuk menyimpan waktu:jam, menit, detik, dan milidetik. Misalnya, Anda memiliki 17:38:31.3231603 atau Anda perlu menambahkan waktu keberangkatan penerbangan. |
| Tanggal dan waktu | waktu tanggal | Jenis ini memungkinkan pengguna untuk menyimpan tanggal dan waktu. Misalnya, Anda memiliki acara pada 15/02/2014 17:38:31.323. |
| Indikator | bit | Anda dapat menggunakan jenis ini untuk menyimpan nilai seperti 'Ya'/'Tidak', di mana 'Ya' adalah 1, dan 'Tidak' adalah 0. |
Selain itu, tidak perlu menentukan nilai bidang, kecuali jika dilarang. Dalam hal ini, Anda dapat menggunakan NULL.
Untuk mengeksekusi contoh, kami akan membuat database pengujian bernama 'Test'.
Untuk membuat database sederhana tanpa properti tambahan, jalankan perintah berikut:
BUAT Uji Basis Data
Untuk menghapus database, jalankan perintah ini:
UJI DROP DATABASE
Untuk beralih ke database kami, gunakan perintah:
Uji GUNAKAN
Atau, Anda dapat memilih database Test dari menu drop-down di area menu SSMS.
Sekarang, kita dapat membuat tabel di database kita menggunakan deskripsi, spasi, dan simbol Cyrillic:
BUAT TABEL [Karyawan]( [ID Karyawan] int, [Nama Lengkap] nvarchar(30), [Tanggal Lahir], [Email] nvarchar(30), [Posisi] nvarchar(30), [Departemen] nvarchar( 30) )
Dalam hal ini, kita perlu membungkus nama dalam tanda kurung siku […].
Namun, lebih baik untuk menentukan semua nama objek dalam bahasa Latin dan tidak menggunakan spasi dalam namanya. Dalam hal ini, setiap kata dimulai dengan huruf kapital. Misalnya, untuk bidang “EmployeeID”, kita dapat menentukan nama PersonnelNumber. Anda juga dapat menggunakan nomor dalam nama, misalnya, PhoneNumber1.
Catatan: Di beberapa DBMS, lebih mudah menggunakan format nama berikut «PHONE_NUMBER». Misalnya, Anda dapat melihat format ini di database ORACLE. Selain itu, nama field tidak boleh sama dengan kata kunci yang digunakan dalam DBMS.
Untuk alasan ini, Anda dapat melupakan sintaks tanda kurung siku dan dapat menghapus tabel Karyawan:
DROP TABLE [Karyawan]
Misalnya, Anda dapat memberi nama tabel dengan karyawan sebagai “Karyawan” dan menetapkan nama berikut untuk bidangnya:
- ID
- Nama
- Ulang tahun
- Posisi
- Departemen
Sangat sering, kami menggunakan 'ID' untuk bidang pengenal.
Sekarang, mari kita buat tabel:
BUAT TABEL Karyawan( ID int, Nama nvarchar(30), Tanggal lahir, Email nvarchar(30), Posisi nvarchar(30), Departemen nvarchar(30) )
Untuk mengatur kolom wajib, Anda dapat menggunakan opsi NOT NULL.
Untuk tabel saat ini, Anda dapat mendefinisikan ulang bidang menggunakan perintah berikut:
-- ID field updateALTER TABLE Employee ALTER COLUMN ID int NOT NULL-- Nama field updateALTER TABLE Employee ALTER COLUMN Nama nvarchar(30) NOT NULL
Catatan: Konsep umum bahasa SQL untuk sebagian besar DBMS adalah sama (dari pengalaman saya sendiri). Perbedaan antara DDL dalam DBMS yang berbeda terutama pada tipe data (mereka dapat berbeda tidak hanya dengan namanya tetapi juga dengan implementasi spesifiknya). Selain itu, implementasi SQL tertentu (perintah) sama, tetapi mungkin ada sedikit perbedaan dalam dialek. Mengetahui dasar-dasar SQL, Anda dapat dengan mudah beralih dari satu DBMS ke DBMS lainnya. Dalam hal ini, Anda hanya perlu memahami secara spesifik implementasi perintah dalam DBMS baru.
Bandingkan perintah yang sama di ORACLE DBMS:
-- buat tabel CREATE TABLE Employee( ID int, -- Di ORACLE tipe int adalah nilai untuk angka(38) Nama nvarchar2(30), -- di ORACLE nvarchar2 identik dengan nvarchar di MS SQL Tanggal ulang tahun, Email nvarchar2(30), Posisi nvarchar2(30), Departemen nvarchar2(30) ); -- Pembaruan kolom ID dan Nama (di sini kita menggunakan MODIFY(…) alih-alih ALTER COLUMNALTER TABLE Employee MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- add PK (dalam hal ini konstruksinya sama seperti pada MS SQL) ALTER TABLE Employee ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE berbeda dalam mengimplementasikan tipe varchar2. Formatnya tergantung pada pengaturan DB dan Anda dapat menyimpan teks, misalnya, dalam UTF-8. Selain itu, Anda dapat menentukan panjang bidang baik dalam byte maupun simbol. Untuk melakukan ini, Anda perlu menggunakan nilai BYTE dan CHAR diikuti dengan bidang panjang. Misalnya:
NAME varchar2(30 BYTE) – kapasitas bidang sama dengan 30 byte NAMA varchar2(30 CHAR) -- kapasitas bidang sama dengan 30 simbol
Nilai (BYTE atau CHAR) yang akan digunakan secara default ketika Anda hanya menunjukkan varchar2(30) di ORACLE akan tergantung pada pengaturan DB. Seringkali, Anda mudah bingung. Oleh karena itu, saya menyarankan untuk secara eksplisit menentukan CHAR saat Anda menggunakan tipe varchar2 (misalnya, dengan UTF-8) di ORACLE (karena lebih nyaman untuk membaca panjang string dalam simbol).
Namun, dalam hal ini, jika ada data dalam tabel, maka untuk berhasil menjalankan perintah, perlu mengisi kolom ID dan Nama di semua baris tabel.
Saya akan menunjukkannya dalam contoh tertentu.
Mari kita masukkan data pada kolom ID, Jabatan, dan Departemen dengan menggunakan script berikut:
MASUKKAN Karyawan(ID,Posisi,Departemen) NILAI (1000,'CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts dept'), (1003,N'Senior Programmer',N'IT')
Dalam hal ini, perintah INSERT juga mengembalikan kesalahan. Ini terjadi karena kami belum menentukan nilai untuk Nama bidang wajib.
Jika ada beberapa data di tabel asli, maka perintah “ALTER TABLE Employee ALTER COLUMN ID int NOT NULL” akan bekerja, sedangkan perintah “ALTER TABLE Employee ALTER COLUMN Name int NOT NULL” akan mengembalikan kesalahan yang dimiliki bidang Nama Nilai NULL.
Mari kita tambahkan nilai di bidang Nama:
MASUKKAN Karyawan(ID,Posisi,Departemen,Nama) NILAI (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel '), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan')
Selain itu, Anda dapat menggunakan NOT NULL saat membuat tabel baru dengan pernyataan CREATE TABLE.
Pertama, mari kita hapus tabel:
Karyawan DROP TABLE
Sekarang, kita akan membuat tabel dengan kolom wajib ID dan Nama:
BUAT TABEL Karyawan( ID int NOT NULL, Nama nvarchar(30) NOT NULL, Tanggal lahir, Email nvarchar(30), Posisi nvarchar(30), Departemen nvarchar(30) )
Selain itu, Anda dapat menentukan NULL setelah nama kolom yang menyiratkan bahwa nilai NULL diperbolehkan. Ini tidak wajib, karena opsi ini disetel secara default.
Jika Anda perlu membuat kolom saat ini tidak wajib, gunakan sintaks berikut:
ALTER TABLE Karyawan ALTER COLUMN Nama nvarchar(30) NULL
Atau, Anda dapat menggunakan perintah ini:
ALTER TABLE Karyawan ALTER COLUMN Nama nvarchar(30)
Selain itu, dengan perintah ini, kita dapat memodifikasi jenis bidang ke yang lain yang kompatibel atau mengubah panjangnya. Misalnya, mari kita perluas bidang Nama menjadi 50 simbol:
ALTER TABLE Karyawan ALTER COLUMN Nama nvarchar(50)
Kunci utama
Saat membuat tabel, Anda perlu menentukan kolom atau kumpulan kolom yang unik untuk setiap baris. Dengan menggunakan nilai unik ini, Anda dapat mengidentifikasi catatan. Nilai ini disebut kunci utama. Kolom ID (yang berisi «nomor pribadi karyawan» – dalam kasus kami ini adalah nilai unik untuk setiap karyawan dan tidak dapat diduplikasi) dapat menjadi kunci utama untuk tabel Karyawan kami.
Anda dapat menggunakan perintah berikut untuk membuat kunci utama tabel:
ALTER TABLE Karyawan ADD CONSTRAINT PK_Kunci UTAMA Karyawan(ID)
'PK_Employees' adalah nama kendala yang mendefinisikan kunci utama. Biasanya, nama kunci utama terdiri dari awalan ‘PK_’ dan nama tabel.
Jika kunci utama berisi beberapa bidang, maka Anda perlu mencantumkan bidang ini dalam tanda kurung yang dipisahkan dengan koma:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(field1,field2,…)
Perlu diingat bahwa di MS SQL, semua bidang kunci utama harus NOT NULL.
Selain itu, Anda dapat menentukan kunci utama saat membuat tabel. Mari kita hapus tabelnya:
Karyawan DROP TABLE
Kemudian, buat tabel menggunakan sintaks berikut:
BUAT TABEL Karyawan( ID int NOT NULL, Nama nvarchar(30) NOT NULL, Tanggal lahir, Email nvarchar(30), Posisi nvarchar(30), Departemen nvarchar(30), CONSTRAINT PK_Karyawan PRIMARY KEY(ID) – jelaskan PK setelah semua pengajuan sebagai kendala )
Tambahkan data ke tabel:
MASUKKAN Karyawan(ID,Posisi,Departemen,Nama) NILAI (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel '), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Programmer senior',N'IT',N'Jordan')
Sebenarnya, Anda tidak perlu menentukan nama kendala. Dalam hal ini, nama sistem akan ditetapkan. Misalnya, «PK__Employee__3214EC278DA42077»:
BUAT TABEL Karyawan( ID int NOT NULL, Nama nvarchar(30) NOT NULL, Tanggal lahir, Email nvarchar(30), Posisi nvarchar(30), Departemen nvarchar(30), PRIMARY KEY(ID) )
atau
BUAT TABEL Karyawan( ID int NOT NULL PRIMARY KEY, Nama nvarchar(30) NOT NULL, Tanggal lahir, Email nvarchar(30), Posisi nvarchar(30), Departemen nvarchar(30) )
Secara pribadi, saya akan merekomendasikan secara eksplisit menentukan nama batasan untuk tabel permanen, karena lebih mudah untuk bekerja dengan atau menghapus nilai yang ditentukan secara eksplisit dan jelas di masa mendatang. Misalnya:
ALTER TABLE Karyawan DROP CONSTRAINT PK_Karyawan
Namun, lebih nyaman untuk menerapkan sintaks pendek ini, tanpa nama batasan saat membuat tabel database sementara (nama tabel sementara dimulai dengan # atau ##.
Ringkasan:
Kami telah menganalisis perintah berikut:
- BUAT TABEL table_name (daftar bidang dan jenisnya, serta batasannya) – berfungsi untuk membuat tabel baru di database saat ini;
- TABEL DROP table_name – berfungsi untuk menghapus tabel dari database saat ini;
- ALTER TABLE table_name ALTER COLUMN column_name … – berfungsi untuk memperbarui jenis kolom atau untuk mengubah pengaturannya (misalnya, ketika Anda perlu mengatur NULL atau NOT NULL);
- ALTER TABLE table_name TAMBAHKAN KENDALA constraint_name KUNCI UTAMA (field1, field2,…) – digunakan untuk menambahkan kunci utama ke tabel saat ini;
- ALTER TABLE table_name HAPUS KENDALA constraint_name – digunakan untuk menghapus batasan dari tabel.
Tabel sementara
Abstrak dari MSDN. Ada dua jenis tabel sementara di MS SQL Server:lokal (#) dan global (##). Tabel sementara lokal hanya dapat dilihat oleh pembuatnya sebelum instance SQL Server terputus. Mereka secara otomatis dihapus setelah pengguna terputus dari contoh SQL Server. Tabel sementara global terlihat oleh semua pengguna selama sesi koneksi apa pun setelah membuat tabel ini. Tabel ini dihapus setelah pengguna terputus dari instance SQL Server.
Tabel sementara dibuat di database sistem tempdb, yang berarti kita tidak membanjiri database utama. Selain itu, Anda dapat menghapusnya menggunakan perintah DROP TABLE. Sangat sering, tabel sementara lokal (#) digunakan.
Untuk membuat tabel sementara, Anda dapat menggunakan perintah CREATE TABLE:
BUAT TABEL #Temp( ID int, Nama nvarchar(30) )
Anda dapat menghapus tabel sementara dengan perintah DROP TABLE:
DROP TABLE #Temp
Selain itu, Anda dapat membuat tabel sementara dan mengisinya dengan data menggunakan sintaks SELECT … INTO:
PILIH ID,Nama INTO #Temp FROM Karyawan
Catatan: Dalam DBMS yang berbeda, implementasi database sementara dapat bervariasi. Misalnya, dalam ORACLE dan Firebird DBMS, struktur tabel sementara harus didefinisikan terlebih dahulu oleh perintah CREATE GLOBAL TEMPORARY TABLE. Juga, Anda perlu menentukan cara menyimpan data. Setelah ini, pengguna melihatnya di antara tabel umum dan bekerja dengannya seperti dengan tabel konvensional.
Normalisasi database:membagi menjadi subtabel (tabel referensi) dan mendefinisikan hubungan tabel
Tabel Karyawan kami saat ini memiliki kelemahan:pengguna dapat mengetik teks apa pun di bidang Posisi dan Departemen, yang dapat mengembalikan kesalahan, karena untuk satu karyawan ia dapat menentukan "TI" sebagai departemen, sedangkan untuk karyawan lain, ia dapat menentukan "TI" departemen". Akibatnya, tidak jelas apa yang dimaksud pengguna, apakah karyawan ini bekerja untuk departemen yang sama atau apakah ada kesalahan ejaan dan ada 2 departemen yang berbeda. Selain itu, dalam kasus ini, kami tidak akan dapat mengelompokkan data dengan benar untuk sebuah laporan, di mana kami perlu menunjukkan jumlah karyawan untuk setiap departemen.
Kelemahan lainnya adalah volume penyimpanan dan duplikasinya, yaitu Anda perlu menentukan nama lengkap departemen untuk setiap karyawan, yang memerlukan ruang dalam database untuk menyimpan setiap simbol nama departemen.
Kerugian ketiga adalah kerumitan memperbarui data lapangan ketika Anda perlu mengubah nama posisi apa pun – dari programmer ke programmer junior. Dalam hal ini, Anda perlu menambahkan data baru di setiap baris tabel di mana Posisinya adalah “Programmer”.
Untuk menghindari situasi seperti itu, disarankan untuk menggunakan normalisasi database – membagi menjadi subtabel – tabel referensi.
Mari kita buat 2 tabel referensi “Posisi” dan “Departemen”:
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Nama nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Nama nvarchar(30) NOT NULL )
Perhatikan bahwa di sini kita telah menggunakan IDENTITY properti baru. Artinya data di kolom ID akan otomatis terdaftar mulai dari 1. Jadi, saat menambahkan record baru, nilai 1, 2, 3, dst. akan diberikan secara berurutan. Biasanya, bidang ini disebut bidang peningkatan otomatis. Hanya satu bidang dengan properti IDENTITY yang dapat didefinisikan sebagai kunci utama dalam sebuah tabel. Biasanya, tetapi tidak selalu, bidang tersebut adalah kunci utama tabel.
Catatan: Dalam DBMS yang berbeda, implementasi bidang dengan incrementer mungkin berbeda. Di MySQL, misalnya, bidang seperti itu ditentukan oleh properti AUTO_INCREMENT. Di ORACLE dan Firebird, Anda dapat meniru fungsi ini berdasarkan urutan (Urutan). Tapi sejauh yang saya tahu, properti GENERATED AS IDENTITY telah ditambahkan di ORACLE.
Mari kita isi tabel ini secara otomatis berdasarkan data saat ini di bidang Posisi dan Departemen pada tabel Karyawan:
-- isi field Name pada tabel Positions dengan nilai unik dari field Position pada tabel Employee INSERT Positions(Name) SELECT DISTINCT Position FROM Employee WHERE Position IS NOT NULL – drop record dimana posisi tidak ditentukanAnda perlu melakukan langkah yang sama untuk tabel Departemen:
MASUKKAN Departemen(Nama) PILIH Departemen BERBEDA DARI Karyawan DI MANA Departemen TIDAK NULLSekarang, jika kita membuka tabel Posisi dan Departemen, maka kita akan melihat daftar nilai bernomor di bidang ID:
PILIH * DARI Posisi
| ID | Nama |
| 1 | Akuntan |
| 2 | CEO |
| 3 | Pemrogram |
| 4 | Programmer Senior |
PILIH * DARI Departemen
| ID | Nama |
| 1 | Administrasi |
| 2 | Departemen akun |
| 3 | TI |
Tabel-tabel ini akan menjadi tabel referensi untuk menentukan posisi dan departemen. Sekarang, kita akan mengacu pada pengidentifikasi posisi dan departemen. Pertama, mari buat bidang baru di tabel Karyawan untuk menyimpan pengenal:
-- tambahkan field untuk ID posisi ALTER TABLE Employee ADD PositionID int -- tambahkan field untuk ID department ALTER TABLE Employee ADD DepartmentID int
Jenis bidang referensi harus sama dengan tabel referensi, dalam hal ini adalah int.
Selain itu, Anda dapat menambahkan beberapa bidang menggunakan satu perintah dengan mencantumkan bidang yang dipisahkan dengan koma:
ALTER TABLE Karyawan ADD PositionID int, DepartmentID int
Sekarang, kami akan menambahkan batasan referensi (KUNCI ASING) ke bidang ini, sehingga pengguna tidak dapat menambahkan nilai apa pun yang bukan nilai ID dari tabel referensi.
ALTER TABLE Karyawan TAMBAHKAN CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENSI Posisi(ID)
Langkah yang sama harus dilakukan untuk kolom kedua:
ALTER TABLE Karyawan TAMBAHKAN CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCEs Departments(ID)
Sekarang, pengguna hanya dapat memasukkan nilai ID di bidang ini dari tabel referensi yang sesuai. Jadi, untuk menggunakan departemen atau posisi baru, pengguna harus menambahkan catatan baru di tabel referensi yang sesuai. Karena posisi dan departemen disimpan dalam tabel referensi dalam satu salinan, maka untuk mengubah namanya, Anda hanya perlu mengubahnya di tabel referensi.
Nama batasan referensi biasanya majemuk. Ini terdiri dari awalan «FK» diikuti dengan nama tabel dan nama bidang yang mengacu pada pengidentifikasi tabel referensi.
Pengidentifikasi (ID) biasanya merupakan nilai internal yang hanya digunakan untuk tautan. Tidak peduli berapa nilai yang dimilikinya. Jadi, jangan mencoba menghilangkan celah dalam urutan nilai yang muncul saat Anda bekerja dengan tabel, misalnya, saat Anda menghapus record dari tabel referensi.
Dalam beberapa kasus, dimungkinkan untuk membuat referensi dari beberapa bidang:
ALTER TABLE table ADD CONSTRAINT constraint_name FOREIGN KEY(field1,field2,…) REFERENCES tabel referensi(field1,field2,…)
Dalam hal ini, kunci utama diwakili oleh sekumpulan beberapa bidang (bidang1, bidang2, …) dalam tabel “reference_table”.
Sekarang, mari perbarui bidang PositionID dan DepartmentID dengan nilai ID dari tabel referensi.
Untuk melakukan ini, kita akan menggunakan perintah UPDATE:
PERBARUI e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employee e
Jalankan kueri berikut:
PILIH * DARI Karyawan
| ID | Nama | Ulang Tahun | Posisi | Departemen | PositionID | DepartmentID | |
| 1000 | John | NULL | NULL | CEO | Administrasi | 2 | 1 |
| 1001 | Daniel | NULL | NULL | Pemrogram | TI | 3 | 3 |
| 1002 | Mike | NULL | NULL | Akuntan | Dept akun | 1 | 2 |
| 1003 | Yordania | NULL | NULL | Programmer senior | TI | 4 | 3 |
Seperti yang Anda lihat, bidang PositionID dan DepartmentID cocok dengan posisi dan departemen. Dengan demikian, Anda dapat menghapus bidang Posisi dan Departemen di tabel Karyawan dengan menjalankan perintah berikut:
ALTER TABLE Karyawan DROP COLUMN Posisi,Departemen
Sekarang, jalankan pernyataan ini:
PILIH * DARI Karyawan
| ID | Nama | Ulang Tahun | PositionID | DepartmentID | |
| 1000 | John | NULL | NULL | 2 | 1 |
| 1001 | Daniel | NULL | NULL | 3 | 3 |
| 1002 | Mike | NULL | NULL | 1 | 2 |
| 1003 | Jordan | NULL | NULL | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
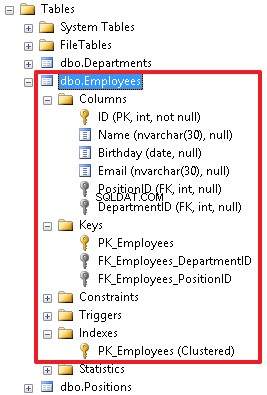
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
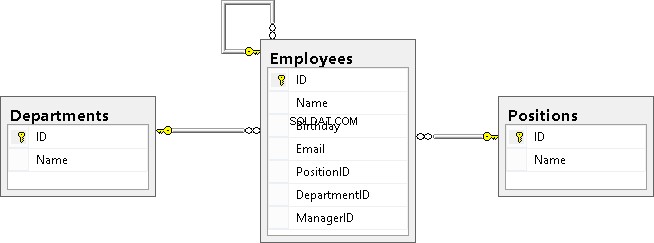
Then create a diagram and check how our tables are linked:
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ONINSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Summary:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
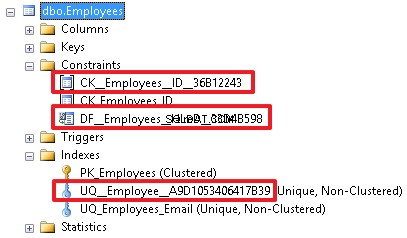
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON
Ringkasan
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.



