Basis data adalah bagian penting dan vital dari setiap bisnis atau organisasi. Tren yang berkembang memperkirakan bahwa 82% perusahaan mengharapkan jumlah database meningkat selama 12 bulan ke depan. Tantangan utama setiap DBA adalah menemukan cara mengatasi pertumbuhan data besar-besaran, dan ini akan menjadi tujuan terpenting. Bagaimana Anda dapat meningkatkan kinerja database, menurunkan biaya, dan menghilangkan waktu henti untuk memberikan pengalaman terbaik kepada pengguna? Apakah kompresi data merupakan pilihan? Mari kita mulai dan lihat bagaimana beberapa fitur yang ada dapat berguna untuk menangani situasi seperti itu.
Pada artikel ini, kita akan mempelajari bagaimana solusi kompresi data dapat membantu kita mengoptimalkan solusi manajemen data. Dalam panduan ini, kami akan membahas topik berikut:
- Ikhtisar kompresi
- Manfaat kompresi
- Ringkasan tentang data adalah teknik kompresi
- Diskusi tentang berbagai jenis kompresi data
- Fakta tentang kompresi data
- Pertimbangan implementasi
- dan banyak lagi…
Kompresi
Kompresi adalah teknik dan, dengan demikian, operasi yang sensitif terhadap sumber daya, tetapi dengan pertukaran perangkat keras. Seseorang harus memikirkan penerapan kompresi data untuk manfaat berikut:
- Pengelolaan ruang yang efektif
- Teknik pengurangan biaya yang efisien
- Kemudahan pengelolaan backup database
- Penggunaan bandwidth N/W yang efektif
- Pemulihan atau pemulihan yang aman dan lebih cepat
- Kinerja yang lebih baik – mengurangi jejak memori sistem
Catatan: Jika SQL Server dibatasi oleh CPU atau memori, maka kompresi mungkin tidak sesuai dengan lingkungan Anda.
Kompresi data berlaku untuk:
- Tumpukan
- Indeks berkerumun
- Indeks yang tidak berkerumun
- Partisi
- Tampilan yang diindeks
Catatan: Objek besar tidak dikompresi (Misalnya, LOB dan BLOB)
Paling cocok untuk aplikasi berikut:
- Tabel log
- Tabel audit
- Tabel fakta
- Pelaporan
Pengantar
Kompresi data adalah teknologi yang sudah ada sejak SQL Server 2008. Ide kompresi data adalah Anda dapat memilih tabel, indeks, atau partisi secara selektif dalam database. I/O terus menjadi hambatan dalam memindahkan informasi antara masuk dan keluar dari database. Kompresi data memanfaatkan jenis ini dan membantu meningkatkan efisiensi database. Seperti yang kita ketahui bahwa kecepatan jaringan jauh lebih lambat daripada kecepatan pemrosesan, adalah mungkin untuk menemukan peningkatan efisiensi dengan menggunakan kekuatan pemrosesan untuk mengompresi data dalam database, sehingga berjalan lebih cepat. Dan kemudian gunakan kekuatan pemrosesan lagi, untuk membuka kompres data di ujung yang lain. Secara umum, kompresi data mengurangi ruang yang ditempati oleh data. Teknik kompresi data tersedia untuk setiap database dan didukung oleh semua edisi SQL Server 2016 SP1. Sebelumnya, ini hanya tersedia di SQL Server Enterprise atau edisi Pengembang, bukan di Standar atau Ekspres.
Dukungan Fitur

Jenis kompresi data
Ada dua jenis kompresi data yang tersedia dalam SQL Server, tingkat baris dan tingkat halaman.
Kompresi tingkat baris bekerja di belakang layar dan mengubah tipe data panjang tetap menjadi tipe panjang variabel. Asumsinya di sini adalah bahwa seringkali data disimpan pada tipe panjang tetap, seperti char 100, dan mereka tidak benar-benar mengisi seluruh 100 karakter untuk setiap record. Keuntungan kecil dapat dicapai dengan menghapus ruang ekstra ini dari meja. Tentu saja, jika tabel data Anda tidak menggunakan bidang teks dan numerik dengan panjang tetap, atau jika mereka melakukannya dan Anda benar-benar menyimpan jumlah karakter dan digit yang diizinkan sepenuhnya, maka perolehan kompresi di bawah skema tingkat baris akan menjadi minimal terbaik.
Konsep kompresi diperluas ke semua tipe data dengan panjang tetap, termasuk char, int, dan float. SQL Server memungkinkan menghemat ruang dengan menyimpan data seperti itu adalah tipe berukuran variabel; data akan muncul dan berperilaku seperti panjang tetap.
Misalnya, jika Anda menyimpan nilai 100 dalam int kolom, SQL Server tidak perlu menggunakan semua 32 bit, melainkan hanya menggunakan 8 bit (1 byte).
Kompresi tingkat halaman membawa hal-hal ke tingkat lain. Pertama, ini secara otomatis menerapkan kompresi tingkat baris pada bidang data dengan panjang tetap, sehingga Anda secara otomatis mendapatkan keuntungan tersebut secara default. Kemudian di atas itu, itu menerapkan sesuatu yang disebut kompresi awalan, dan teknik lain yang disebut kompresi kamus.
Kompresi Baris
Kompresi baris adalah tingkat kompresi dalam yang menyimpan string karakter tetap dengan menggunakan format panjang variabel dengan tidak menyimpan karakter kosong. Langkah-langkah berikut dilakukan dalam kompresi tingkat baris.
- Semua tipe data numerik seperti int , mengambang , desimal, dan uang diubah menjadi tipe data panjang variabel. Misalnya, 125 disimpan dalam kolom dan tipe data kolom adalah bilangan bulat. Kemudian kita tahu bahwa 4 byte digunakan untuk menyimpan nilai integer. Tetapi 125 dapat disimpan dalam 1 byte karena 1 byte dapat menyimpan nilai dari 0 hingga 255. Jadi, 125 dapat disimpan sebagai int kecil , sehingga 3 byte dapat disimpan.
- Char dan Nchar tipe data disimpan sebagai tipe data panjang variabel. Misalnya, “SQL” disimpan dalam char (20) jenis kolom. Tetapi setelah kompresi, hanya 3 byte yang akan digunakan. Setelah kompresi data, tidak ada karakter kosong yang disimpan dengan jenis data ini.
- Metadata catatan dikurangi.
- Nilai NULL dan 0 dioptimalkan dan tidak ada ruang yang digunakan.
Kompresi Halaman
Kompresi halaman adalah tingkat lanjutan dari kompresi data. Secara default, kompresi halaman juga mengimplementasikan kompresi tingkat baris. Kompresi halaman dikategorikan menjadi dua jenis
- Kompresi awalan dan
- Kompresi kamus.
Kompresi Awalan
Dalam kompresi awalan untuk setiap halaman, untuk setiap kolom di halaman, nilai umum diambil dari semua baris dan disimpan di bawah header di setiap kolom. Sekarang di setiap baris, referensi ke nilai itu disimpan alih-alih nilai umum.
Kompresi Kamus
Kompresi kamus mirip dengan kompresi awalan tetapi nilai umum diambil dari semua kolom dan disimpan di baris kedua setelah header. Kompresi kamus mencari nilai yang sama persis di semua kolom dan baris di setiap halaman.
Kita dapat melakukan kompresi tingkat baris dan halaman untuk objek database berikut.
- Tabel yang disimpan dalam heap.
- Seluruh tabel disimpan sebagai indeks berkerumun.
- Tampilan yang diindeks.
- Indeks non-cluster.
- Indeks dan tabel yang dipartisi.
Catatan: Kita dapat melakukan kompresi data baik pada saat pembuatan seperti CREATE TABLE, CREATE INDEX atau setelah pembuatan menggunakan perintah ALTER dengan opsi REBUILD seperti ALTER TABLE…. MEMBANGUN KEMBALI DENGAN.
Demo
WideWorldImporters database digunakan melalui seluruh demo. Juga, DW waktu nyata database dipertimbangkan untuk operasi kompresi.
Mari kita ikuti langkah-langkahnya secara detail:
1. Untuk melihat pengaturan kompresi untuk objek dalam database, jalankan T-SQL berikut:
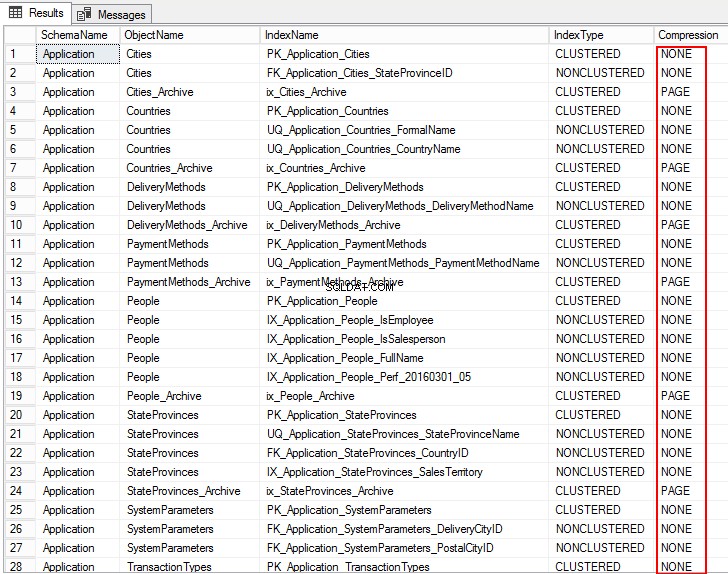
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
Output berikut menunjukkan tipe kompresi sebagai PAGE, ROW, dan untuk beberapa tabel NONE. Ini berarti tidak dikonfigurasi untuk kompresi.
2. Untuk memperkirakan kompresi, jalankan prosedur tersimpan sistem berikut sp_estimate_data_compression_savings . Dalam hal ini, prosedur tersimpan dijalankan pada tabel PurchaseOrderLines.
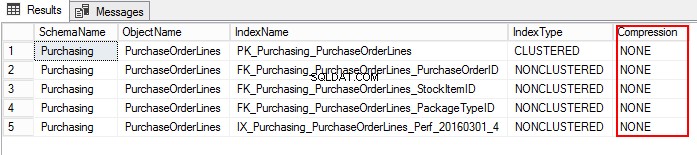
3. Mari kita cari tahu pengaturan kompresi PurchaseOrderLines dengan menjalankan T-SQL berikut:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

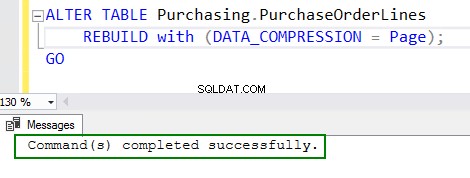
4. Aktifkan kompresi dengan menjalankan perintah ALTER table:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
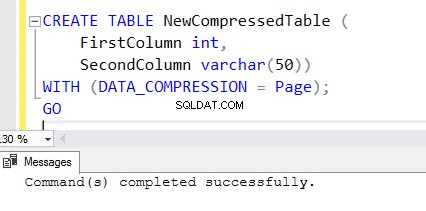
5. Untuk membuat tabel baru dengan fitur kompresi yang diaktifkan, tambahkan klausa WITH di akhir pernyataan CREATE TABLE. Anda dapat melihat pernyataan CREATE TABLE di bawah ini yang digunakan untuk membuat NewCompressedTable .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Fakta Kompresi Data
Mari kita telusuri beberapa informasi aktual tentang kompresi
- Kompresi tidak dapat diterapkan ke tabel sistem
- Tabel tidak dapat diaktifkan untuk kompresi jika ukuran baris melebihi 8060 byte.
- Data terkompresi di-cache di kumpulan buffer; itu berarti waktu respons lebih cepat
- Mengaktifkan kompresi dapat menyebabkan rencana kueri berubah karena data disimpan menggunakan jumlah halaman dan jumlah baris yang berbeda per halaman.
- Indeks non-cluster tidak mewarisi properti kompresi
- Saat indeks berkerumun dibuat di heap, indeks berkerumun mewarisi status kompresi heap kecuali jika status kompresi alternatif ditentukan.
- Kompresi tingkat ROW dan PAGE dapat diaktifkan dan dinonaktifkan, offline atau online.
- Jika setelan heap diubah, maka semua indeks yang tidak berkerumun harus dibuat ulang.
- Persyaratan ruang disk untuk mengaktifkan atau menonaktifkan kompresi baris atau halaman sama dengan untuk membuat atau membangun kembali indeks.
- Saat partisi dipisah dengan menggunakan pernyataan ALTER PARTITION, kedua partisi mewarisi atribut kompresi data dari partisi asli.
- Saat dua partisi digabungkan, partisi yang dihasilkan mewarisi atribut kompresi data dari partisi tujuan.
- Untuk mengganti partisi, properti kompresi data partisi harus cocok dengan properti kompresi tabel.
- Tabel dan indeks Columnstore selalu disimpan dengan kompresi Columnstore.
- Kompresi data tidak kompatibel dengan kolom yang jarang sehingga tabel tidak dapat dikompresi.
Skenario waktu nyata
Mari kita mempelajari teknik kompresi data dan memahami parameter utama kompresi data.
Untuk memeriksa ruang yang digunakan oleh setiap tabel, jalankan T-SQL berikut. Keluaran kueri memberi kita informasi terperinci tentang penggunaan setiap tabel. Ini akan menjadi faktor penentu untuk implementasi kompresi data.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
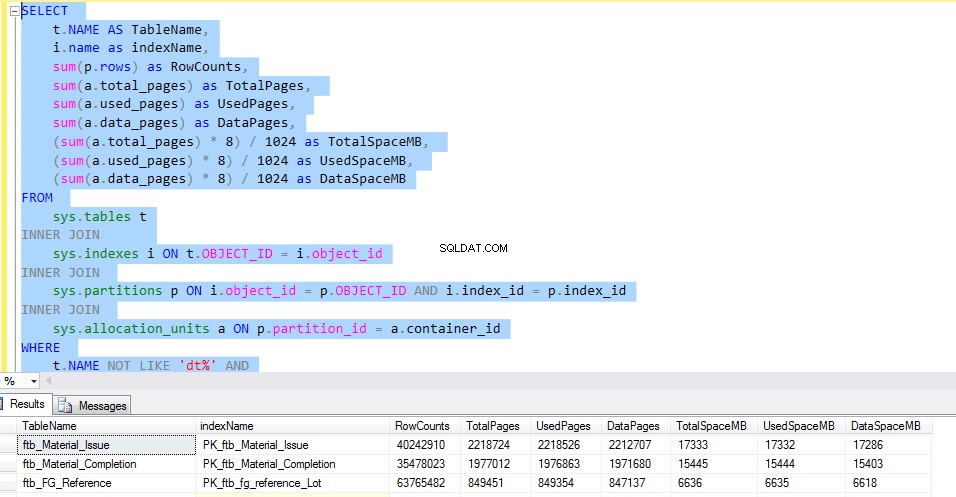
Mari kita pertimbangkan ftb_material_Issue tabel fakta. Tabel fakta memiliki tipe data numerik BIGINT.
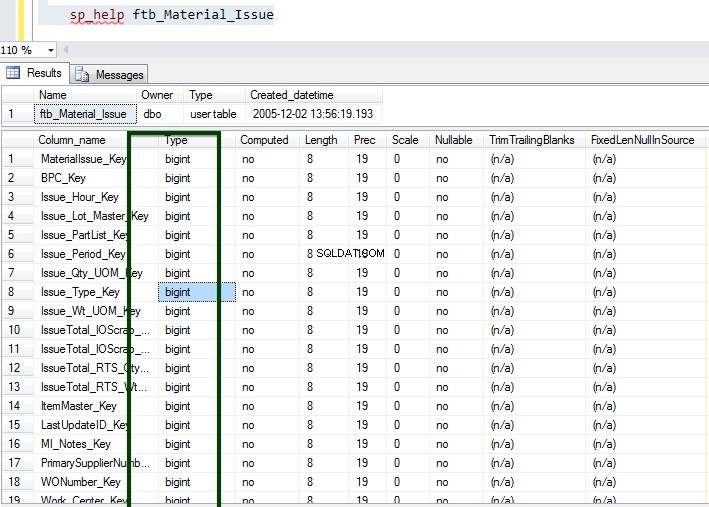
Sekarang, jalankan prosedur tersimpan sp_spaceused untuk memahami detail tabel. Anda dapat mempelajari lebih lanjut tentang perintah sp_spaceused di sini.
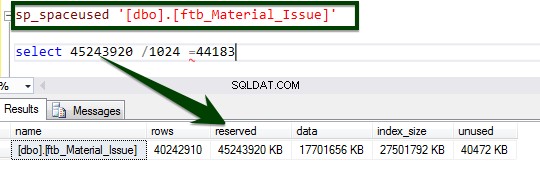
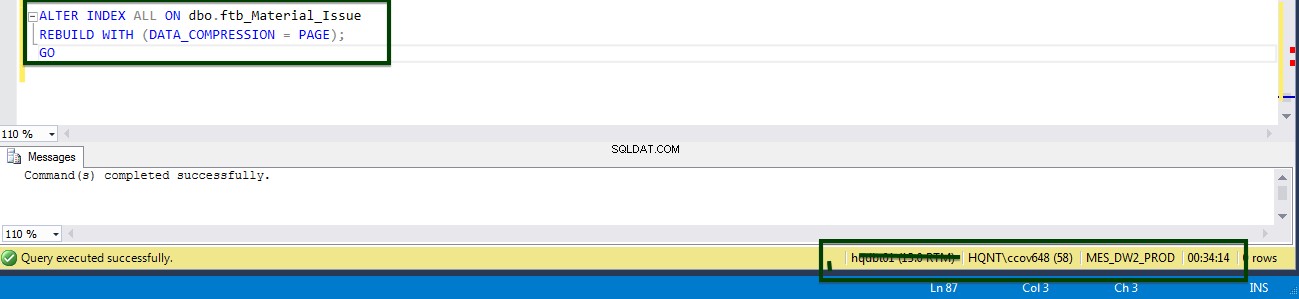
Aktifkan kompresi tingkat tabel dengan menjalankan T-SQL berikut. T-SQL berikut dijalankan di server dan butuh 34 menit 14 detik untuk mengompresi halaman di tingkat tabel.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
Anda dapat melihat fluktuasi CPU dan I/O selama eksekusi perintah tabel ALTER.
Sekarang, mari kita lakukan perbandingan kompresi data Sebelum v/s Setelah. Ukuran tabel sekitar ~45 GB diturunkan menjadi ~15 GB.
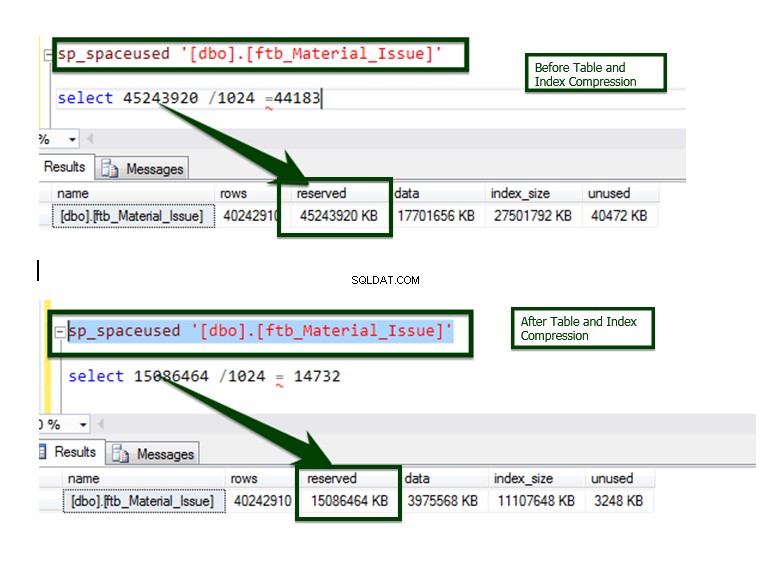
Proses ini diimplementasikan pada sebagian besar objek menggunakan skrip otomatis dan inilah hasil akhir perbandingannya.
Perbandingan data antara Sebelum dan Setelah operasi kompresi indeks.

Ringkasan
Kompresi data adalah teknik yang sangat efektif untuk mengurangi ukuran data; pengurangan data membutuhkan lebih sedikit proses I/O. Menambahkan kompresi ke database meningkatkan beban pada persyaratan CPU. Anda harus memastikan bahwa Anda memiliki kapasitas pemrosesan yang tersedia untuk mengakomodasi perubahan ini secara efisien. Jadi lebih baik melakukan sedikit riset terlebih dahulu dan melihat jenis keuntungan yang dapat diharapkan sebelum menerapkan modifikasi untuk mengaktifkan kompresi data. Ini sangat bermanfaat dalam penyiapan basis data cloud yang melibatkan biaya.
Lakukan kompresi (jangan lakukan semuanya sekaligus) dan kompres selama periode waktu aktivitas rendah. Kompresi data dan kompresi cadangan berjalan berdampingan dengan baik dan dapat menghasilkan penghematan ruang penyimpanan tambahan, jadi lanjutkan dan manjakan diri Anda.
Kompresi tidak hanya mengurangi ukuran file fisik, tetapi juga mengurangi I/O disk, yang dapat sangat meningkatkan kinerja banyak aplikasi database, bersama dengan backup database.
Memutuskan untuk mengimplementasikan kompresi lebih mudah jika kita mengetahui infrastruktur dan kebutuhan bisnis yang mendasarinya. Kami pasti dapat menggunakan prosedur sistem yang tersedia untuk memahami dan memperkirakan penghematan kompresi. Prosedur tersimpan ini tidak memberikan detail apa pun yang memberi tahu Anda bagaimana kompresi akan berdampak positif atau negatif pada sistem Anda. Jelas bahwa ada trade-off untuk segala jenis kompresi. Jika Anda memiliki pola data besar yang sama, maka kompresi adalah kunci untuk menghemat ruang. Dengan pertumbuhan daya CPU dan setiap sistem terikat pada struktur multi-inti, kompresi mungkin cocok untuk banyak sistem. Saya akan merekomendasikan pengujian sistem Anda. Uji untuk memastikan bahwa kinerja tidak terpengaruh secara negatif. Jika indeks memiliki banyak pembaruan dan penghapusan, biaya CPU untuk mengompresi dan mendekompresi data mungkin lebih besar daripada penghematan I/O dan RAM dari kompresi data. Tidak setiap database atau tabel secara otomatis akan menjadi kandidat yang baik untuk menerapkan kompresi, jadi sebaiknya lakukan sedikit riset terlebih dahulu untuk melihat jenis keuntungan yang dapat diharapkan sebelum menerapkan modifikasi untuk mengaktifkan kompresi data pada database Anda. Anda perlu menguji kompresi untuk melihat apakah itu berfungsi dengan baik di lingkungan Anda, karena mungkin tidak berfungsi dengan baik di database yang banyak disisipkan.
Referensi
Edisi dan fitur yang didukung dari SQL Server 2016
Kompresi Data
Implementasi Kompresi Baris
Implementasi Kompresi Halaman