Menurut Wikipedia, penyisipan massal adalah proses atau metode yang disediakan oleh sistem manajemen basis data untuk memuat beberapa baris data ke dalam tabel basis data. Jika kita menyesuaikan penjelasan ini dengan pernyataan BULK INSERT, penyisipan massal memungkinkan mengimpor file data eksternal ke SQL Server.
Asumsikan bahwa organisasi kami memiliki file CSV 1.500.000 baris, dan kami ingin mengimpornya ke tabel tertentu di SQL Server untuk menggunakan pernyataan BULK INSERT di SQL Server. Kami dapat menemukan beberapa metode untuk menangani tugas ini. Itu bisa menggunakan BCP (b ulk c salin p rogram), SQL Server Import and Export Wizard, atau paket Layanan Integrasi SQL Server. Namun, pernyataan BULK INSERT jauh lebih cepat dan kuat. Keuntungan lainnya adalah ia menawarkan beberapa parameter yang membantu menentukan pengaturan proses penyisipan massal.
Mari kita mulai dengan sampel dasar. Kemudian kita akan melalui skenario yang lebih canggih.
Persiapan
Pertama-tama, kita memerlukan contoh file CSV. Kami mengunduh contoh file CSV dari situs web E for Excel (kumpulan contoh file CSV dengan nomor baris berbeda). Di sini, kita akan menggunakan 1.500.000 Catatan Penjualan.
Unduh file zip, unzip untuk mendapatkan file CSV, dan letakkan di drive lokal Anda.
Impor File CSV ke tabel SQL Server
Kami mengimpor file CSV kami ke tabel tujuan dalam bentuk paling sederhana. Saya menempatkan file CSV sampel saya di drive C:. Sekarang kita membuat tabel untuk mengimpor data file CSV ke dalamnya:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
Pernyataan BULK INSERT berikut mengimpor file CSV ke tabel Penjualan:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Anda mungkin telah mencatat parameter spesifik dari pernyataan penyisipan massal di atas. Mari kita perjelas:
- PERTAMA menentukan titik awal dari pernyataan insert. Pada contoh di bawah ini, kami ingin melewatkan header kolom, jadi kami menetapkan parameter ini ke 2.

- FIELDTERMINATOR mendefinisikan karakter yang memisahkan bidang satu sama lain. SQL Server mendeteksi setiap bidang dengan cara ini.
- ROWTERMINATOR tidak jauh berbeda dengan FIELDTERMINATOR. Ini mendefinisikan karakter pemisahan baris.
Dalam contoh file CSV, FIELDTERMINATOR sangat jelas, dan ini adalah koma (,). Untuk mendeteksi parameter ini, buka file CSV di Notepad++ dan arahkan ke View -> Show Symbol -> Show All Charters. Karakter CRLF ada di akhir setiap kolom.
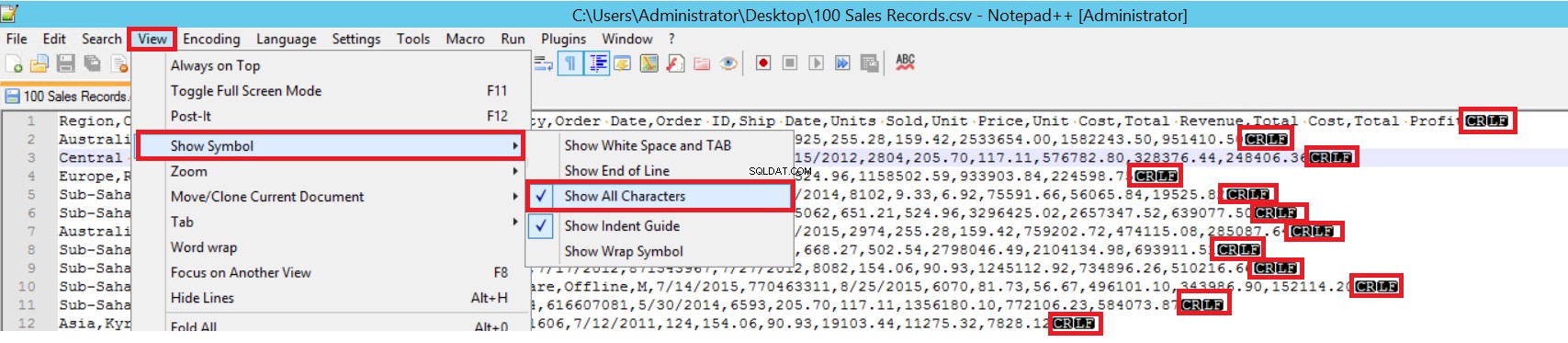
CR =Pengembalian Kereta dan LF =Umpan Garis. Mereka digunakan untuk menandai jeda baris dalam file teks. Indikatornya adalah “\n” dalam pernyataan penyisipan massal.
Cara lain untuk mengimpor file CSV ke tabel dengan penyisipan massal adalah dengan menggunakan parameter FORMAT. Perhatikan bahwa parameter ini hanya tersedia di SQL Server 2017 dan versi yang lebih baru.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Itu adalah skenario paling sederhana di mana tabel tujuan dan file CSV memiliki jumlah kolom yang sama. Namun, jika tabel tujuan memiliki lebih banyak kolom, maka file CSV adalah tipikal. Mari kita pertimbangkan.
Kami menambahkan kunci utama ke tabel Penjualan untuk memecahkan pemetaan kolom kesetaraan. Kami membuat tabel Penjualan dengan kunci utama dan mengimpor file CSV melalui perintah penyisipan massal.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Tapi itu menghasilkan kesalahan:
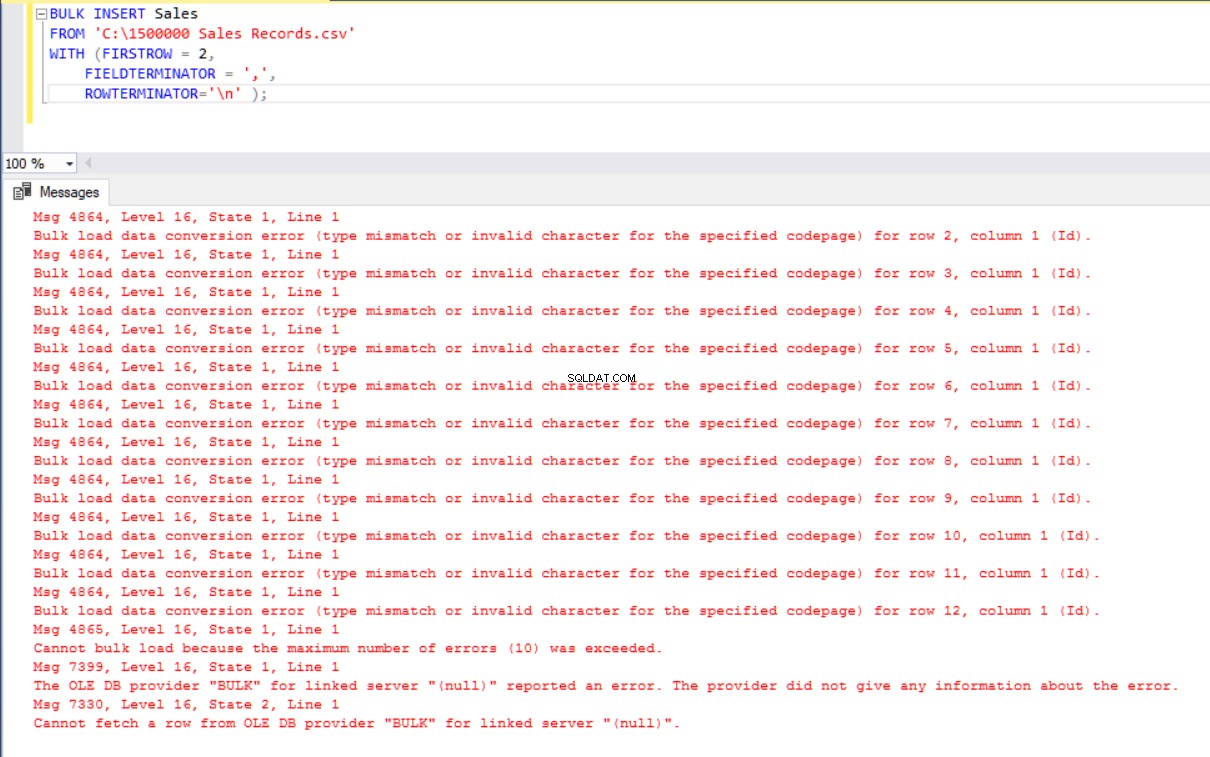
Untuk mengatasi kesalahan tersebut, kami membuat tampilan tabel Penjualan dengan memetakan kolom ke file CSV. Kemudian kami mengimpor data CSV melalui tampilan ini ke tabel Penjualan:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Pisahkan dan muat file CSV besar ke dalam ukuran batch kecil
SQL Server memperoleh kunci ke tabel tujuan selama operasi penyisipan massal. Secara default, jika Anda tidak menyetel parameter BATCHSIZE, SQL Server membuka transaksi dan memasukkan seluruh data CSV ke dalamnya. Dengan parameter ini, SQL Server membagi data CSV sesuai dengan nilai parameter.
Mari kita bagi seluruh data CSV menjadi beberapa set masing-masing 300.000 baris.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); Data akan diimpor lima kali dalam beberapa bagian.
- Jika pernyataan penyisipan massal Anda tidak menyertakan parameter BATCHSIZE, kesalahan akan terjadi, dan SQL Server akan memutar kembali seluruh proses penyisipan massal.
- Dengan parameter ini disetel ke pernyataan penyisipan massal, SQL Server hanya mengembalikan bagian tempat kesalahan terjadi.
Tidak ada nilai optimal atau terbaik untuk parameter ini karena nilainya dapat berubah sesuai dengan kebutuhan sistem database Anda.
Setel perilaku jika terjadi kesalahan
Jika terjadi kesalahan dalam beberapa skenario penyalinan massal, kami dapat membatalkan proses penyalinan massal atau melanjutkannya. Parameter MAXERRORS memungkinkan kita untuk menentukan jumlah kesalahan maksimum. Jika proses penyisipan massal mencapai nilai kesalahan maksimum ini, itu akan membatalkan operasi impor massal dan memutar kembali. Nilai default untuk parameter ini adalah 10.
Misalnya, kami telah merusak tipe data dalam 3 baris file CSV. Parameter MAXERRORS diatur ke 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); Seluruh operasi penyisipan massal akan dibatalkan karena ada lebih banyak kesalahan daripada nilai parameter MAXERRORS.
Jika kita mengubah parameter MAXERRORS menjadi 4, pernyataan penyisipan massal akan melewati baris ini dengan kesalahan dan menyisipkan baris terstruktur data yang benar. Proses penyisipan massal akan selesai.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Jika kita menggunakan BATCHSIZE dan MAXERRORS secara bersamaan, proses penyalinan massal tidak akan membatalkan seluruh operasi penyisipan. Itu hanya akan membatalkan bagian yang dibagi.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Perhatikan gambar di bawah ini yang menunjukkan hasil eksekusi skrip:
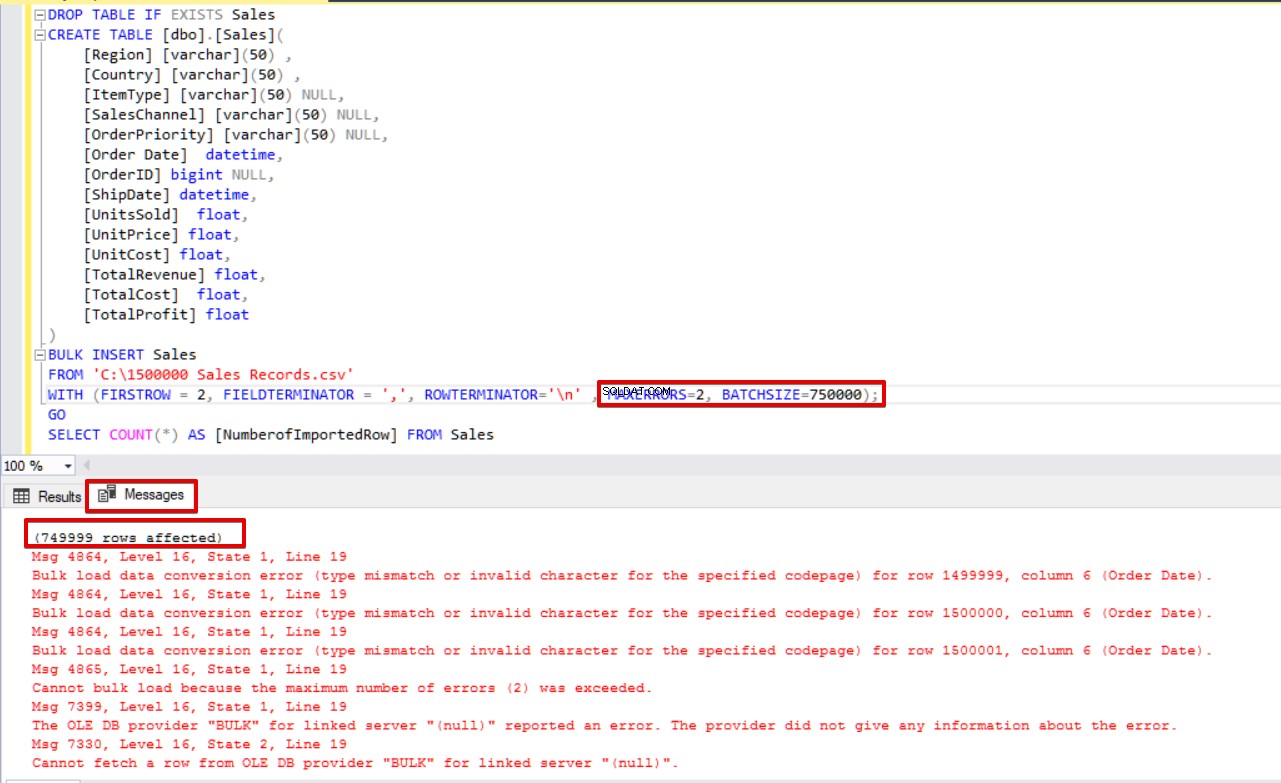
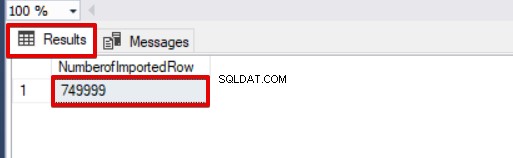
Opsi lain dari proses penyisipan massal
FIRE_TRIGGERS – mengaktifkan pemicu di tabel tujuan selama operasi penyisipan massal
Secara default, selama proses penyisipan massal, pemicu penyisipan yang ditentukan dalam tabel target tidak diaktifkan. Namun, dalam beberapa situasi, kami mungkin ingin mengaktifkannya.
Solusinya adalah menggunakan opsi FIRE_TRIGGERS dalam pernyataan penyisipan massal. Namun harap dicatat bahwa ini dapat memengaruhi dan menurunkan kinerja operasi penyisipan massal. Itu karena trigger/pemicu dapat membuat operasi terpisah dalam database.
Pada awalnya, kami tidak menyetel parameter FIRE_TRIGGERS, dan proses penyisipan massal tidak akan mengaktifkan pemicu penyisipan. Lihat skrip T-SQL di bawah ini:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogSaat skrip ini dijalankan, pemicu penyisipan tidak akan diaktifkan karena opsi FIRE_TRIGGERS tidak disetel.
Sekarang, mari tambahkan opsi FIRE_TRIGGERS ke pernyataan penyisipan massal:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 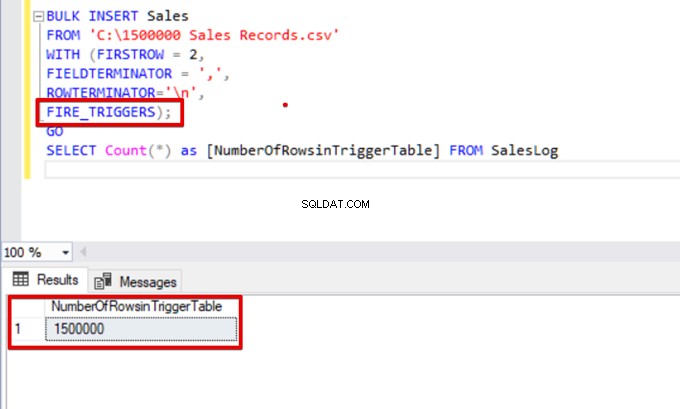
CHECK_CONSTRAINTS – mengaktifkan batasan pemeriksaan selama operasi penyisipan massal
Batasan pemeriksaan memungkinkan kami menerapkan integritas data dalam tabel SQL Server. Tujuan dari batasan adalah untuk memeriksa nilai yang dimasukkan, diperbarui, atau dihapus sesuai dengan regulasi sintaksisnya. Seperti, batasan NOT NULL menyatakan bahwa nilai NULL tidak dapat mengubah kolom yang ditentukan.
Di sini, kami fokus pada batasan dan interaksi penyisipan massal. Secara default, selama proses penyisipan massal, semua pemeriksaan dan batasan kunci asing diabaikan. Tapi ada beberapa pengecualian.
Menurut Microsoft, “kendala UNIQUE dan PRIMARY KEY selalu diterapkan. Saat mengimpor ke kolom karakter yang batasan NOT NULL didefinisikan, BULK INSERT menyisipkan string kosong saat tidak ada nilai dalam file teks.”
Dalam skrip T-SQL berikut, kami menambahkan batasan centang ke kolom OrderDate, yang mengontrol tanggal pemesanan lebih besar dari 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'Akibatnya, proses penyisipan massal melewatkan kontrol batasan pemeriksaan. Namun, SQL Server menunjukkan batasan pemeriksaan sebagai tidak tepercaya:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'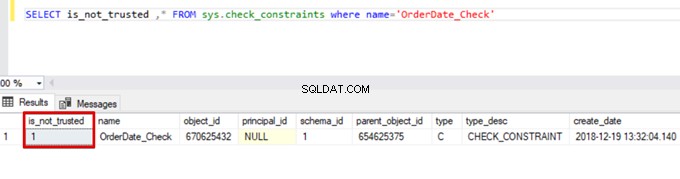
Nilai ini menunjukkan bahwa seseorang memasukkan atau memperbarui beberapa data ke kolom ini dengan melewatkan batasan pemeriksaan. Pada saat yang sama, kolom ini mungkin berisi data yang tidak konsisten mengenai kendala tersebut.
Coba jalankan pernyataan penyisipan massal dengan opsi CHECK_CONSTRAINTS. Hasilnya sederhana:check constraint mengembalikan kesalahan karena data yang tidak tepat.
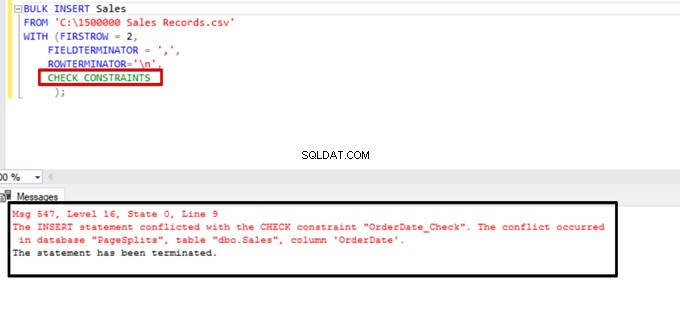
TABLOCK – meningkatkan kinerja dalam beberapa penyisipan massal ke dalam satu tabel tujuan
Tujuan utama dari mekanisme penguncian di SQL Server adalah untuk melindungi dan memastikan integritas data. Dalam konsep Utama artikel penguncian SQL Server, Anda dapat menemukan detail tentang mekanisme penguncian.
Kami akan fokus pada detail penguncian proses penyisipan massal.
Jika Anda menjalankan pernyataan penyisipan massal tanpa opsi TABLELOCK, itu memperoleh kunci baris atau tabel menurut hierarki kunci. Namun dalam beberapa kasus, kita mungkin ingin menjalankan beberapa proses penyisipan massal terhadap satu tabel tujuan dan dengan demikian mengurangi waktu operasi.
Pertama, kami mengeksekusi dua pernyataan penyisipan massal secara bersamaan dan menganalisis perilaku mekanisme penguncian. Buka dua jendela kueri di SQL Server Management Studio dan jalankan pernyataan penyisipan massal berikut secara bersamaan.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);Jalankan kueri DMV (Dynamic Management View) berikut – ini membantu memantau status proses penyisipan massal:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID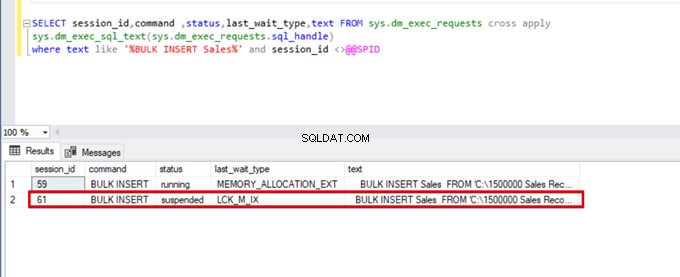
Seperti yang Anda lihat pada gambar di atas, sesi 61, status proses penyisipan massal ditangguhkan karena penguncian. Jika kami memverifikasi masalah, sesi 59 mengunci tabel tujuan penyisipan massal. Kemudian, sesi 61 menunggu pelepasan kunci ini untuk melanjutkan proses penyisipan massal.
Sekarang, kami menambahkan opsi TABLOCK ke pernyataan penyisipan massal dan menjalankan kueri.
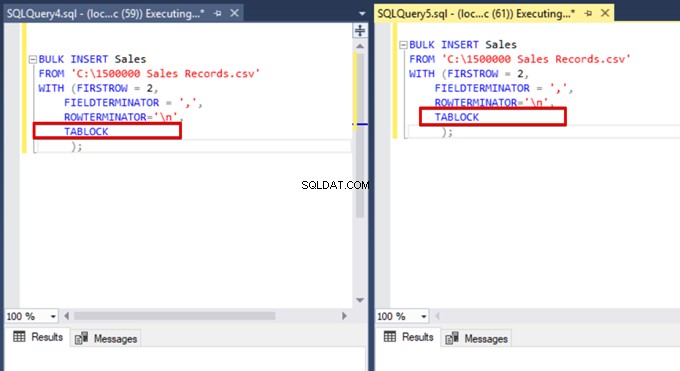
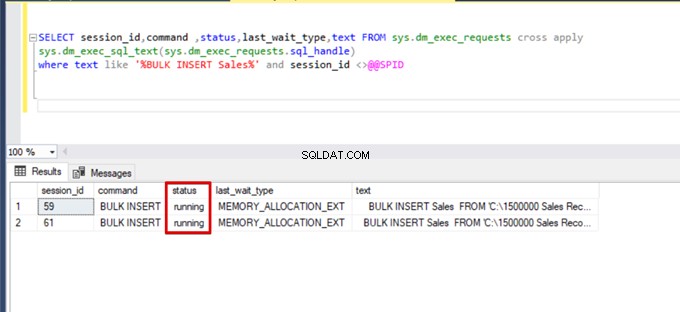
Ketika kami menjalankan kueri pemantauan DMV lagi, kami tidak dapat melihat proses penyisipan massal yang ditangguhkan karena SQL Server menggunakan jenis kunci tertentu yang disebut kunci pembaruan massal (BU). Jenis kunci ini memungkinkan pemrosesan beberapa operasi penyisipan massal terhadap tabel yang sama secara bersamaan. Opsi ini juga mengurangi total waktu proses penyisipan massal.
Saat kami menjalankan kueri berikut selama proses penyisipan massal, kami dapat memantau detail penguncian dan jenis penguncian:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()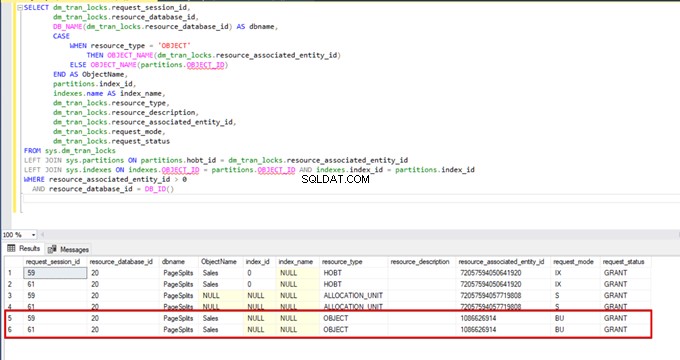
Kesimpulan
Artikel saat ini menjelajahi semua detail operasi penyisipan massal di SQL Server. Khususnya, kami menyebutkan perintah BULK INSERT dan pengaturan serta opsinya. Selain itu, kami menganalisis berbagai skenario yang mendekati masalah kehidupan nyata.
Alat yang berguna:
dbForge Data Pump – add-in SSMS untuk mengisi database SQL dengan data sumber eksternal dan memigrasikan data antar sistem.